# 多路查找树
[B 树,B+ 树,B * 树](#B 树,B+ 树,B * 树)
钢达姆机器人

# 二叉树与 B 树
二叉树的问题分析
二叉树的操作效率较高,但是也存在问题,请看下面的二叉树
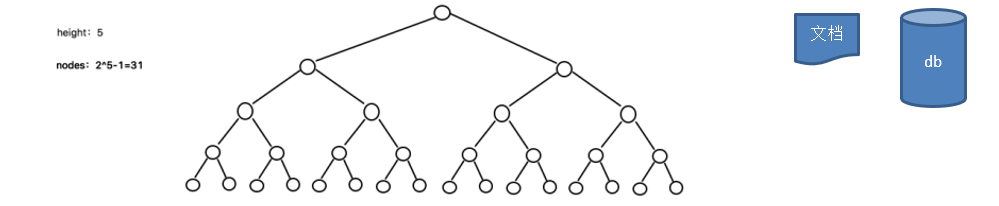
层数:5
节点数量:31
- 计算方式:2 ^ 5 层数 - 1 = 31
- 二叉树需要加载到内存的,如果二叉树的节点少,没有什么问题,但是如果二叉树的节点很多 (比如 1 亿),就存在如下问题:
- 问题 1:在构建二叉树时,需要多次进行
i/o操作 (海量数据存在数据库或文件中),节点海量,构建二叉树时,速度有影响。 - 问题 2:节点海量,也会造成二叉树的高度很大,会降低操作速度。
# 多叉树
- 在 <font style="color:red"> 二叉树中 </font>,每个节点有 < font style="color:red"> 数据项 </font>,<font style="color:red"> 最多有两个子节点 </font>。如果允许每个节点可以有更多的数据项和更多的子节点,就是多叉树 (multiway tree)
- 后面讲解的 2 - 3 树,2 - 3 - 4 树就是多叉树,多叉树通过重新组织节点,减少树的高度,能对二叉树进行优化。
- 举例说明 (下面 2 - 3 树就是一颗多叉树)
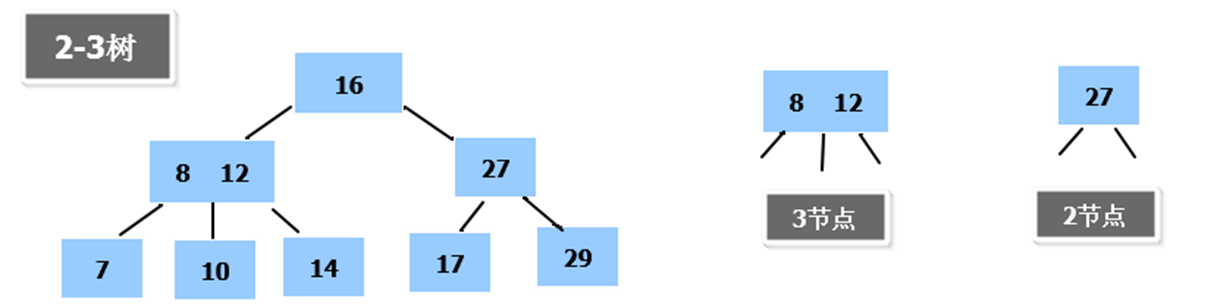
多叉树中,如果一个节点中存在了三个分叉则称为 3 节点。如果是两个分叉则称为 2 节点。
# B 树的基本介绍
B 树通过重新组织节点,降低树的高度,并减少 i/o 读写次数来提升效率。

上图说明:
一个 ○ 代表一个数项
一整个 ○ ○ ○ 的集合代表一个节点
优点理解:
降低树的高度:
可以看到,一个节点中有很多数据项,就能大大减少节点数量,从而降低树的高度
减少
I/O读写次数文件系统及数据库系统的设计者利用了磁盘预读原理,将一个节点的大小设为等于一个页 (页的大小通常为 4K),这样每个节点只需要一次
i/o就可以完全载入。这样说,你可能没有概念,举个例子:将树的度 M 设置为 1024 ,在 600 亿个元素中最多只需要 4 次
i/o操作就可以读取到想要的元素,B 树 (B+) 宽泛应用于文件存储系统以及数据库系统中。什么是 度?
节点的度:
一个节点下的子树节点个数就是 节点的度。
树的度:
指一颗树中 ,节点的度最大的哪一个值。
# 树
# 2 - 3 树基本介绍
2 - 3 树 是最简单的 B 树结构,具有如下特点:
2 - 3 树的所有叶子节点都在同一层 (只要是 B 树都满足这个条件,就是满树)
有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点
不能只有一个节点,说得通俗点就是不能比父节点的节点还少
有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点
不能有二个子节点,一个子节点,说得通俗点就是不能比父节点的节点还少
2 - 3 树是由二节点和三节点构成的树。
# 2-3 树构建图解
对数列 {16, 24, 12, 32, 14, 26, 34, 10, 8, 28, 38, 20} 构建成一个 2-3 树,那么它构建的规则要满足前面说的特点。下面进行图解后,你就明白,上面的特点是如何限制的。
有几个额外的注意事项:
- 一个节点中,最多只允许放 2 个数据。
- 构建的树必须是有序的,也就是按照二叉排序 (BST) 的要求构建有序的树
下面是图解步骤:
- 添加 16,24

添加 16 时,没有数据,直接新建一个节点,放进去。
添加 24 时,发现有一个节点了,并且比 16 大, 此时该节点中只有一个数据,则将 24 放在 16 的右边。
- 添加 12
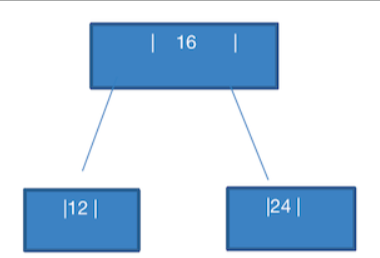
此时会发现,12 比 16 小,本来应该放在 16 的左边。此时发现这个节点 已经有两个数据了,那么就只能放在 左子节点。
如果直接将 12 放到 16 , 24 的左节点,就会破坏 2-3 树的条件:2 节点 ,要么没有子节点,要么有两个节点。
那么此时就只能将 16,24 这个节点进行拆分。如上图: 24 变成 16 的右节点,12 变成 16 的左节点。
这时就满足了 2-3 树 的特性。
- 添加 32
这个就简单了,以现在的树结构,可以直接添加到 24 的 右边 ,变成 24,32
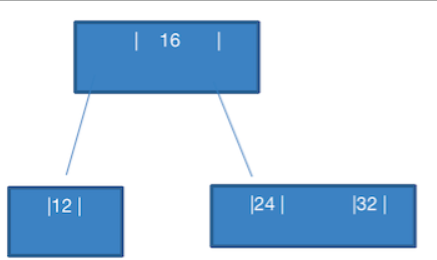
- 添加 14
这个也简单,直接添加到 12 的右边,变成 12,14
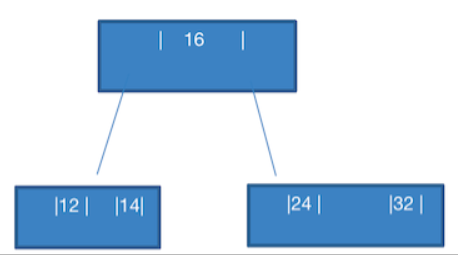
- 添加 26
此时应该添加到 24,32 的中间,由于一个节点只能添加两个数据,那么就需要拆分。
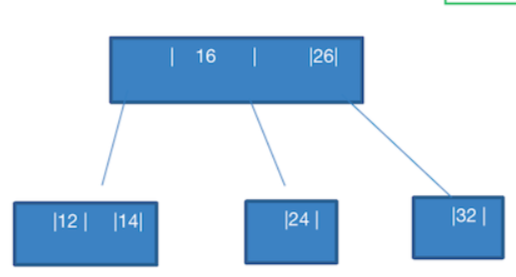
为了满足 B 树特点,发现上层的 16 只有一个数,那么就补足它。组成 16,26 。
因为此时 24,32 这个节点,不满足 BST 的排序了,24 是小于 26 的。只能 32 满足。
拆完上层,再拆本层:由于 24 介于 16,24 之间,则将它安排在 3 节点中的中间节点, 24,32 把 24 拆分出去了,只剩下 32 ,此时完全满足 B 树的特点
- 添加 34
此时就简单了,添加到 32,34 中。
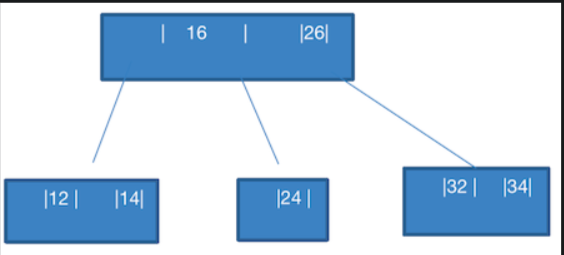
- 添加 10
此时应该添加到 12,14 的左侧,但是不满足条件:一个节点最多只能装 2 个数据。
放到 12,14 的左节点,也不满足条件:所有叶子节点必须在同一层,也不满足 2-3 树 节点的 数量要求。
那么此时就需要拆分,先看它们上层 16,26 是满 的,如何做呢?看下图:
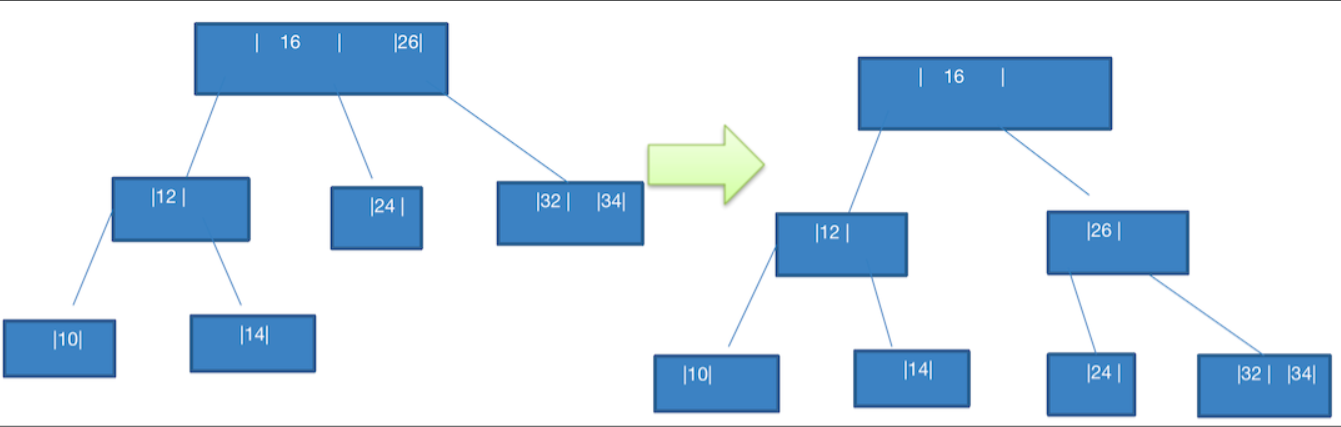
左侧的拆分图,上面我们分析过了,不满足 B 树要求,那么就需要拆分成右图这样:
将
12,14中的 14 拆分成 右子节点 ,10 挂在 左节点。此时不满足 B 树要求的,则将
16,26中的 26 拆分成 右子节点。24这个节点由于上层被拆分了,不满足在中间节点了。调整它的位置原来的
32,34节点调整为16的有节点。添加 8
此时很简单,组成
8,10即可![image-20230711174809201]()
添加 28
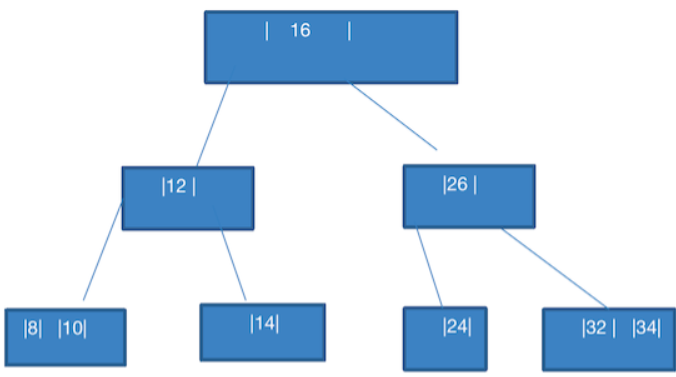
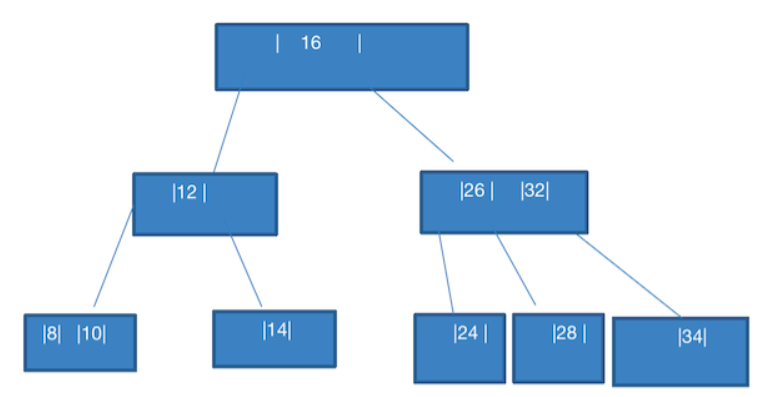
这里有个小问题,此时 28 不是应该加在 26,28 吗?难道说还有一个规则?
- 只有一个数据的节点,下面只允许 最多右 2 个节点,要么没有
- 有 2 个数据的节点,下面只允许 最多 3 个节点,要么没有
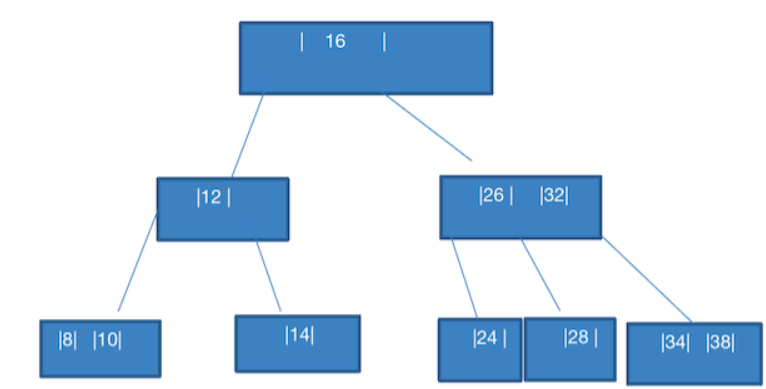
- 添加 38
此时就简单,直接组成 34,38
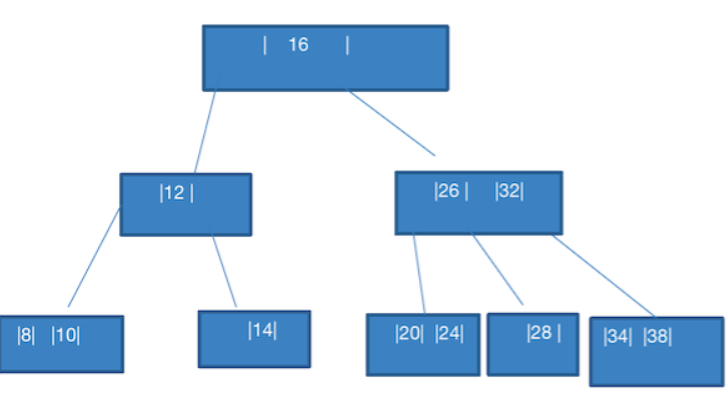
- 添加 20
这个也简单,直接组成 20,24
# 2-3 树添加规则总结
满足如下特点:
所有 叶子节点 都在同一层
只要是 B 树都满足这个条件,就是满树。
有两个子节点的节点 叫 二节点
二节点要么 没有子节点 ,要么 必须有两个子节点。
有三个子节点的节点叫 三节点
三节点要么 没有子节点,要么 必须有三个子节点。
2-3 树 是由 二节点 和 三节点 构成的树
构建的树,要满足二叉排序树(BST)的顺序。
一个节点中,最多只允许放 2 个数据。
只有一个数据的节点,下面只允许 最多有 2 个节点,要么没有
有 2 个数据的节点,下面只允许 最多有 3 个节点,要么没有
其它说明
除了 23 树,还有 234 树等,概念和 23 树类似,也是一种 B 树。如图:
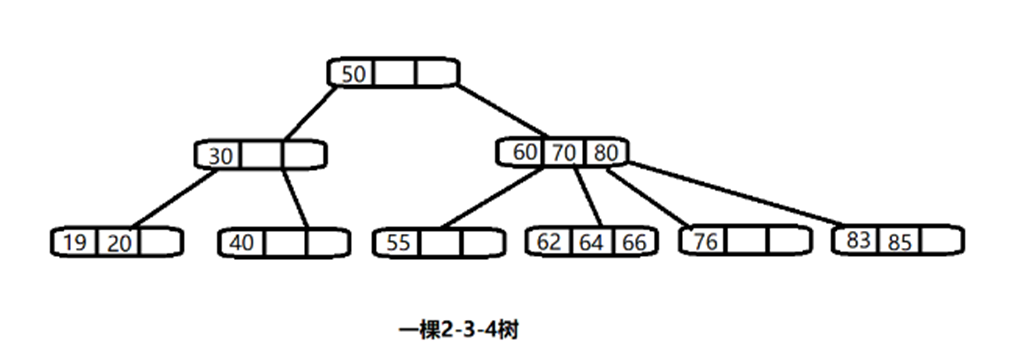
# B 树,B+ 树,B * 树
# B 树的介绍
B-tree 树即 B 树,B 即 Balanced,平衡的意思。有人把 B-tree 翻译成 B - 树,容易让人产生误解。会以为 B - 树是一种树,而 B 树又是另一种树。实际上,B-tree 就是指的 B 树。
前面已经介绍了 2-3 树 和 2-3-4 树,它们就是 B 树 (英语: B-tree 也写成 B - 树),这里我们再做一个说明,我们在学习 MySQL 时,经常听到说某种类型的索引是基于 B 树或者 B + 树的,如图:
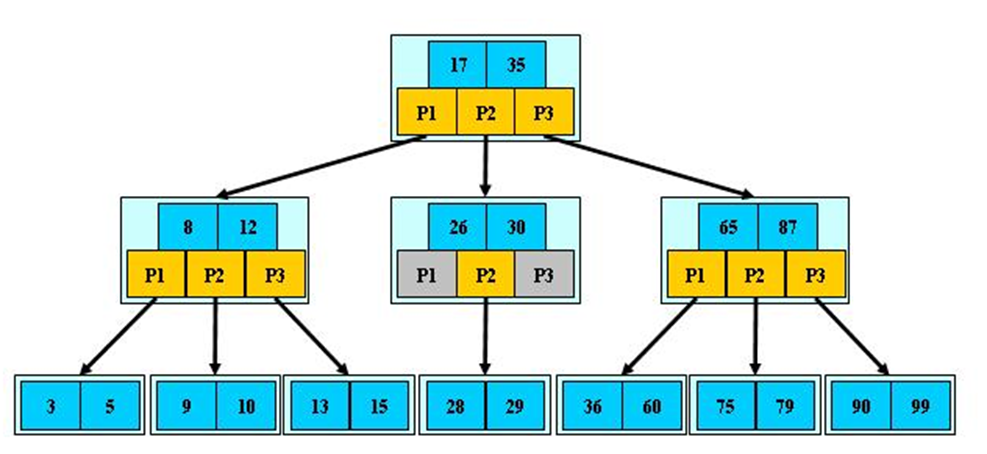
B 树的说明:
- B 树的阶:节点的最多子节点个数。比如 2-3 树的阶是 3,2-3-4 树的阶是 4
- B - 树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点
- 关键字集合分布在整颗树中,即叶子节点和非叶子节点都存放数据.
- 搜索有可能在非叶子结点结束
- 其搜索性能等价于在关键字全集内做一次二分查找
# B + 树的介绍
B + 树是 B 树的变体,也是一种多路搜索树。
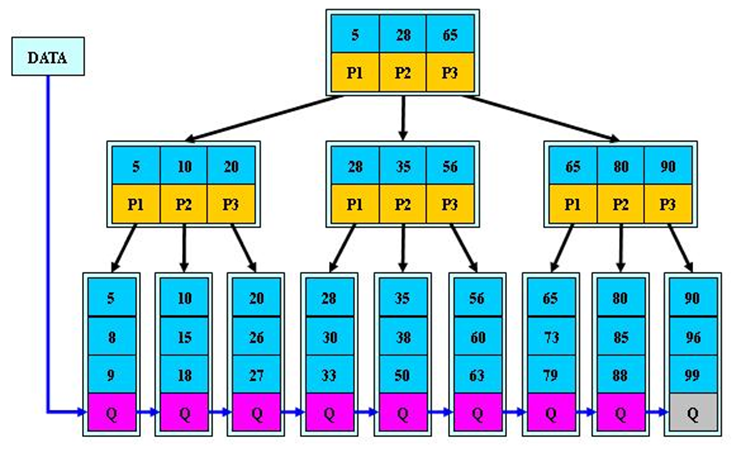
B + 树的说明:
- B + 树的搜索与 B 树也基本相同,区别是 B + 树只有达到叶子结点才命中(B 树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找
- 所有关键字都出现在叶子结点的链表中(即数据只能在叶子节点【也叫稠密索引】),且链表中的关键字 (数据) 恰好是有序的。
- 不可能在非叶子结点命中
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
- 更适合文件索引系统
- B 树和 B + 树各有自己的应用场景,不能说 B + 树完全比 B 树好,反之亦然.
# B 树的介绍
B * 树是 B + 树的变体,在 B + 树的非根和非叶子结点再增加指向兄弟的指针。
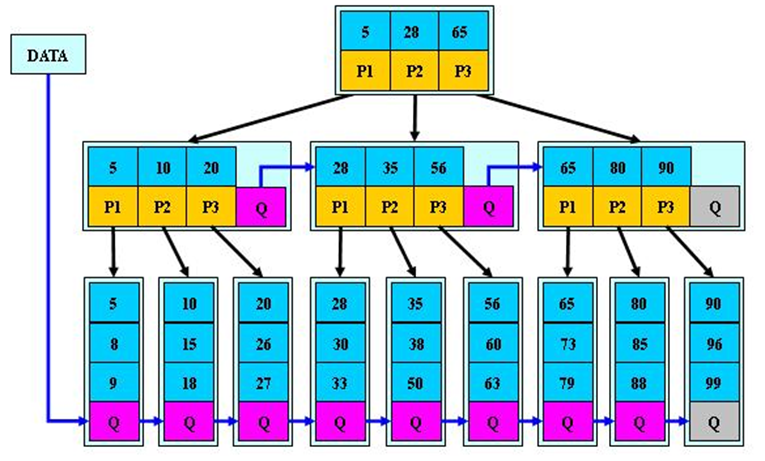
B 树的说明:
- B * 树定义了非叶子结点关键字个数至少为 (2/3)*M,即块的最低使用率为 2/3,而 B + 树的块的最低使用率为 B + 树的 1/2。
- 从第 1 个特点我们可以看出,B * 树分配新结点的概率比 B + 树要低,空间使用率更高