# 二叉搜索树的概述
之前我们已经学过了基础的数据结构了比如说:数组,链表,队列。在这些数据结构中如果我想去从中查找一个元素,这个效率高不高呢?答:并不高!都是线性时间 也就是 O (n)
如果我的需求是必须快速查找,那么我们就需要引入一种新的算法或者数据结构了
你可能会想到之前学过的 二分查找法,它能不能提高查询效率呢?
答案:可以的!它可以达到 对数 时间,也就是 Olog (n)
不过它有限制:必须是针对一个已排序的数组 进行二分查找,但是话说回来 我们对一个数组 做排序 成本还是比较高的
先去排序再去查找,好像有点得不偿失。
那么有没有一个 折中的办法呢?答:有!就是我们换一种数据结构 不采用数组了,而是采用 本章要讲的 二叉搜索树
用它既可以让我们查找效率比较高,也可以让我们在这个结构中加入新的元素时它就是已经排好序的结构
如下图就一颗二叉搜索树,也称之为 二叉排序树
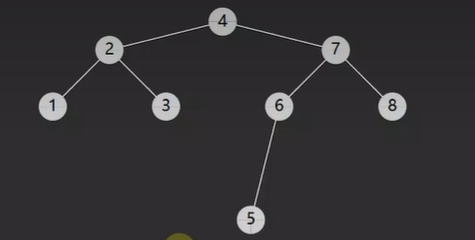
要成为 二叉搜索树 必须符合如下两个特征:
- 树节点增加 key 属性,用来比较谁打谁小,key 不可以重复
- 对于任意一个树节点,它的 key 比左子树的 key 都大,同时也比右子树的 key 都小
PS:而却 二叉搜索树 使用 中序遍历的结果 是一个 升序的 元素顺序,比如上图二叉搜索树 进行中序遍历结果为:1,2,3,4,5,6,7,8。
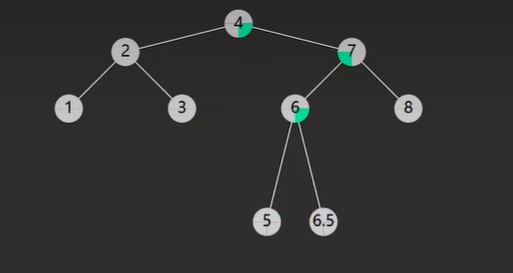
对照上面的二叉搜索树来看如果我要在二叉树中的 6 节点添加一个节点那么它应该是几呢?
首先它必须比 7 小因为 是 7 的左子树,还要比 6 大 因为是 6 的右子树。这样的话我们只能添加一个值为 6.5 的节点了
# 演示 二叉搜索树 的查找效率如何:
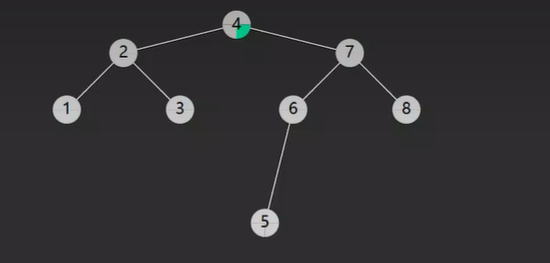
比如说 我要查找一个值为 8 的节点
先从根节点开始 比较 发现比 4 大 那就从右子树开始找,因为根据二叉搜索树的定义中 4 左子树比 4 还要小 不可能存在 8 这个值
接下来跟 4 的右子树 的 7 进行比较 发现比 7 还大 那么就从 7 的右子树 找
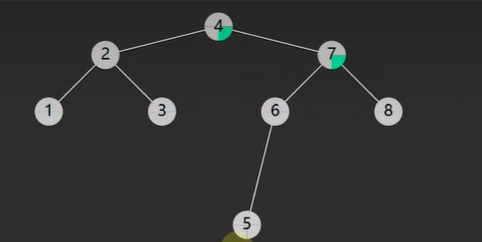
接下来 7 的右子树节点的值就是 8 到这就找到了 8 这个节点了
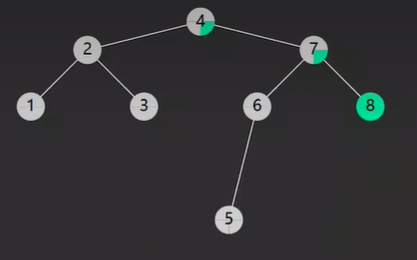
这样的话 就能看出 二叉搜索树可以 一次性 忽略一 半的 分叉 快速找到 我们想要找的节点
上面只是 二叉搜索树 长的比较好的情况下的 结果,如果二叉搜索树长的很糟糕的话 情况就大不如意 了
比如说我们看一个特殊情况:
如下 也算是一颗 二叉搜索树 根节点 5 的左子树都比它小,4 的左子树也比 4 小,3 也是,2 也是
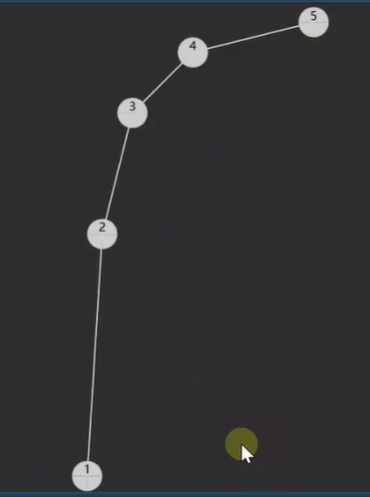
但是这颗 二叉搜索树 长的比较丑,能看得出来 它不平衡 在这种情况下 如果要查找的话 那么它的性能可能就不是那么高了。
比如说要查找 1 的话,那么就需要比较 5 次 才能找到 1 那么这时 时间复杂度 又回到线性时间了也就是 O (n) 了
所以:二叉搜索树 它的平均 时间复杂度是 对数 时间,但是它有一个最糟的情况就是上面不平衡的二叉搜索树情况这种情况下 它的时间复杂度又会下降为 O (n) 线性时间了