# 自管理敏感词
# 敏感词 - 过滤 - 技术选型
| 方案 | 说明 |
|---|---|
| 数据库模糊查询 | 效率太低 |
| String.indexOf ("") 查找 | 数据库量大的话也是比较慢 |
| 全文检索 | 分词再匹配 |
| DFA 算法 | 确定有穷自动机 (一种数据结构) |
# DFA 实现原理
DFA 全称为:Deterministic Finite Automaton, 即确定有穷自动机
存储:一次性的把所有的敏感词存储到了多个 map 中,就是下图表示这种结构
敏感词:冰毒,大麻,大坏蛋

# 检索的过程
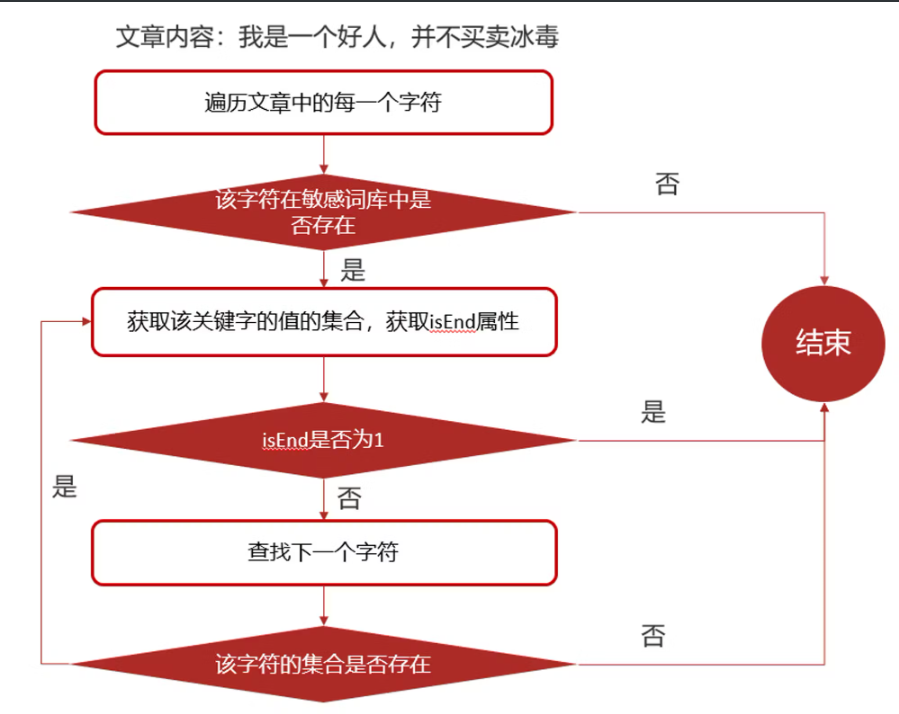
# 功能实现
# 创建敏感词的数据库
/* | |
Navicat MySQL Data Transfer | |
Source Server : localhost | |
Source Server Version : 50721 | |
Source Host : localhost:3306 | |
Source Database : leadnews_wemedia | |
Target Server Type : MYSQL | |
Target Server Version : 50721 | |
File Encoding : 65001 | |
Date: 2021-05-23 11:19:37 | |
*/ | |
SET FOREIGN_KEY_CHECKS=0; | |
-- ---------------------------- | |
-- Table structure for ad_sensitive | |
-- ---------------------------- | |
DROP TABLE IF EXISTS `wm_sensitive`; | |
CREATE TABLE `wm_sensitive` ( | |
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', | |
`sensitives` varchar(10) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '敏感词', | |
`created_time` datetime DEFAULT NULL COMMENT '创建时间', | |
PRIMARY KEY (`id`) USING BTREE | |
) ENGINE=InnoDB AUTO_INCREMENT=3201 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ROW_FORMAT=DYNAMIC COMMENT='敏感词信息表'; | |
-- ---------------------------- | |
-- Records of wm_sensitive | |
-- ---------------------------- | |
INSERT INTO `wm_sensitive` VALUES ('3104', '冰毒', '2021-05-23 15:38:51'); | |
INSERT INTO `wm_sensitive` VALUES ('3105', '法轮功', '2021-05-23 15:38:51'); | |
INSERT INTO `wm_sensitive` VALUES ('3106', '私人侦探', '2021-05-23 11:09:22'); | |
INSERT INTO `wm_sensitive` VALUES ('3107', '针孔摄象', '2021-05-23 11:09:52'); | |
INSERT INTO `wm_sensitive` VALUES ('3108', '信用卡提现', '2021-05-23 11:10:11'); | |
INSERT INTO `wm_sensitive` VALUES ('3109', '无抵押贷款', '2021-05-23 11:10:41'); | |
INSERT INTO `wm_sensitive` VALUES ('3110', '广告代理', '2021-05-23 11:10:59'); | |
INSERT INTO `wm_sensitive` VALUES ('3111', '代开发票', '2021-05-23 11:11:18'); | |
INSERT INTO `wm_sensitive` VALUES ('3112', '蚁力神', '2021-05-23 11:11:39'); | |
INSERT INTO `wm_sensitive` VALUES ('3113', '售肾', '2021-05-23 11:12:08'); | |
INSERT INTO `wm_sensitive` VALUES ('3114', '刻章办', '2021-05-23 11:12:24'); | |
INSERT INTO `wm_sensitive` VALUES ('3116', '套牌车', '2021-05-23 11:12:37'); | |
INSERT INTO `wm_sensitive` VALUES ('3117', '足球投注', '2021-05-23 11:12:51'); | |
INSERT INTO `wm_sensitive` VALUES ('3118', '地下钱庄', '2021-05-23 11:13:07'); | |
INSERT INTO `wm_sensitive` VALUES ('3119', '出售答案', '2021-05-23 11:13:24'); | |
INSERT INTO `wm_sensitive` VALUES ('3200', '小额贷款', '2021-05-23 11:13:40'); |
# pojo
package com.heima.model.wemedia.pojos; | |
import com.baomidou.mybatisplus.annotation.IdType; | |
import com.baomidou.mybatisplus.annotation.TableField; | |
import com.baomidou.mybatisplus.annotation.TableId; | |
import com.baomidou.mybatisplus.annotation.TableName; | |
import lombok.Data; | |
import java.io.Serializable; | |
import java.util.Date; | |
/** | |
* <p> | |
* 敏感词信息表 | |
* </p> | |
* | |
* @author itheima | |
*/ | |
@Data | |
@TableName("wm_sensitive") | |
public class WmSensitive implements Serializable { | |
private static final long serialVersionUID = 1L; | |
/** | |
* 主键 | |
*/ | |
@TableId(value = "id", type = IdType.AUTO) | |
private Integer id; | |
/** | |
* 敏感词 | |
*/ | |
@TableField("sensitives") | |
private String sensitives; | |
/** | |
* 创建时间 | |
*/ | |
@TableField("created_time") | |
private Date createdTime; | |
} |
# SensitiveWordUtil
import java.util.*; | |
public class SensitiveWordUtil { | |
public static Map<String, Object> dictionaryMap = new HashMap<>(); | |
/** | |
* 生成关键词字典库 | |
* @param words | |
* @return | |
*/ | |
public static void initMap(Collection<String> words) { | |
// 判断传入的敏感词集合是否为中 | |
if (words == null) { | |
System.out.println("敏感词列表不能为空"); | |
return ; | |
} | |
//map 初始长度 words.size (),整个字典库的入口字数 (小于 words.size (),因为不同的词可能会有相同的首字) | |
Map<String, Object> map = new HashMap<>(words.size()); | |
// 遍历过程中当前层次的数据 | |
Map<String, Object> curMap = null; | |
// 循环遍历传入的 List 集合 | |
Iterator<String> iterator = words.iterator(); | |
while (iterator.hasNext()) { | |
// 每循环一次拿到一条敏感词 | |
String word = iterator.next(); | |
// 初始化 curMap 集合 将 map 集合的引用 赋值 给 curMap 在下面的 curMap 的 put 中数据将共享到 map 集合对象中 | |
curMap = map; | |
// 获取当前循环的敏感词的长度 | |
int len = word.length(); | |
for (int i =0; i < len; i++) { | |
// 遍历每个词的字 | |
String key = String.valueOf(word.charAt(i)); | |
// 当前字在当前层是否存在,不存在则新建,当前层数据指向下一个节点,继续判断是否存在数据 | |
Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key); | |
if (wordMap == null) { | |
// 每个节点存在两个数据:下一个节点和 isEnd (是否结束标志) 每次的节点都是不同的对象 | |
wordMap = new HashMap<>(2); | |
// 每个单词的 isEnd 都默认为 0 表示没有结束 | |
wordMap.put("isEnd", "0"); | |
// 将单词为 key,wordMap 对象为 value,存储到 curMap 对象中 | |
curMap.put(key, wordMap); | |
} | |
// 将 wordMap 对象引用赋值给 curMap 对象然后将 isEnd 给修改为 1 不然所有的 isEnd 都将修改为 1 | |
curMap = wordMap; | |
// 如果当前字是词的最后一个字,则将 isEnd 标志置 1 | |
if (i == len -1) { | |
curMap.put("isEnd", "1"); | |
} | |
} | |
} | |
dictionaryMap = map; | |
} | |
/** | |
* 搜索文本中某个文字是否匹配关键词 | |
* @param text | |
* @param beginIndex | |
* @return | |
*/ | |
private static int checkWord(String text, int beginIndex) { | |
// 判断初始化的敏感词库是否为 null | |
if (dictionaryMap == null) { | |
throw new RuntimeException("字典不能为空"); | |
} | |
boolean isEnd = false; | |
int wordLength = 0; | |
// 定义一个敏感词库的 map 集合 | |
Map<String, Object> curMap = dictionaryMap; | |
int len = text.length(); | |
// 从文本的第 beginIndex 开始匹配 | |
for (int i = beginIndex; i < len; i++) { | |
String key = String.valueOf(text.charAt(i)); | |
// 获取当前 key 的下一个节点 | |
// 获取文本中的每一个单词是否存在 敏感词库中 | |
curMap = (Map<String, Object>) curMap.get(key); | |
if (curMap == null) { | |
// 如果不存在就 跳出循环 | |
break; | |
} else { | |
// 如果存在 敏感词 就进行 wordLength ++ | |
wordLength ++; | |
// 判断是否为敏感词的结束单词 , 并修改 isEnd 为 true 不要重置 wordLength 的值 | |
if ("1".equals(curMap.get("isEnd"))) { | |
isEnd = true; | |
} | |
} | |
} | |
if (!isEnd) { | |
wordLength = 0; | |
} | |
return wordLength; | |
} | |
/** | |
* 获取匹配的关键词和命中次数 | |
* @param text | |
* @return | |
*/ | |
public static Map<String, Integer> matchWords(String text) { | |
// 创建 map 集合 | |
Map<String, Integer> wordMap = new HashMap<>(); | |
// 获取文章内容的长度 | |
int len = text.length(); | |
// 循环 | |
for (int i = 0; i < len; i++) { | |
// 调用函数检查文章内容出现了多少次 的敏感词 次数 每次返回敏感词后再从 | |
int wordLength = checkWord(text, i); | |
if (wordLength > 0) { | |
String word = text.substring(i, i + wordLength); | |
// 添加关键词匹配次数 | |
if (wordMap.containsKey(word)) { | |
// 重复的敏感词 数量 进行追加 | |
wordMap.put(word, wordMap.get(word) + 1); | |
} else { | |
wordMap.put(word, 1); | |
} | |
// 略过敏感词 进行下一个 | |
i += wordLength - 1; | |
} | |
} | |
return wordMap; | |
} | |
public static void main(String[] args) { | |
List<String> list = new ArrayList<>(); | |
list.add("法轮"); | |
list.add("法轮功"); | |
list.add("冰毒"); | |
initMap(list); | |
String content="我是一个好人,并不会卖冰毒,也不操练法轮功,我真的不卖冰毒"; | |
Map<String, Integer> map = matchWords(content); | |
System.out.println(map); | |
} | |
} |
# 在文章审核的逻辑代码中的使用方式
/** | |
* 资管理的敏感词审核 | |
* @param content | |
* @param wmNews | |
* @return | |
*/ | |
private boolean handleSensitiveScan(String content, WmNews wmNews) { | |
boolean flag = true; | |
// 获取所有的敏感词 对象 | |
List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers | |
.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives)); | |
// 获取所有敏感词 存入 List 集合中 | |
List<String> sensitivesList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList()); | |
// 初始化敏感词库 | |
SensitiveWordUtil.initMap(sensitivesList); | |
// 查看文章中是否包含敏感词 | |
Map<String, Integer> map = SensitiveWordUtil.matchWords(content); | |
if(map.size() > 0) | |
{ | |
updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容" + map); | |
flag = false; | |
} | |
return flag; | |
} |