# 图片敏感文字检查
# 需求
识别如下图片中的文字

# 图片文字识别
认识 OCR 什么是 OCR?
OCR (Optical Character Recognition,光学字符识别) 是指电子设备 (例如扫描仪或数码相机) 检查纸上打印的字符,通过检测暗,亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
| 方案 | 说明 |
|---|---|
| 百度 OCR | 收费 |
| Tesseract-OCR | Google 维护的开源 OCR 引擎,支持 Java,Python 等语言调用 |
| Tess4J | 封装了 Tesseract-OCR ,支持 Java 调用 |
# 使用步骤
# 导入依赖
<dependency> | |
<groupId>net.sourceforge.tess4j</groupId> | |
<artifactId>tess4j</artifactId> | |
<version>4.1.1</version> | |
</dependency> |
在指定的位置创建一个名为:tessdata 的文件夹将 中文文字库文件 放入其中
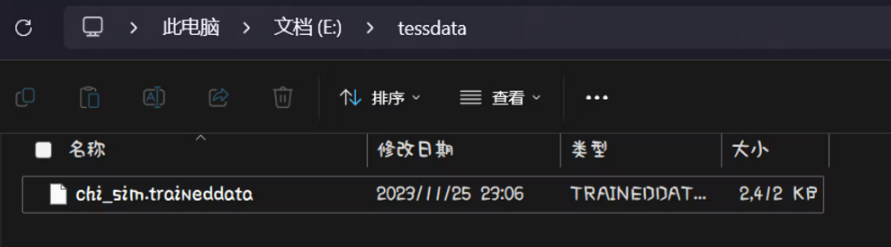
文件内容如下:
https://file.notion.so/f/f/73b84cb9-15ed-45fa-a30f-5ee9486a5bec/459678e4-a204-4c08-add2-a43897c77886/chi_sim.traineddata?id=3912f598-1fea-4ef8-875c-53ecad098164&table=block&spaceId=73b84cb9-15ed-45fa-a30f-5ee9486a5bec&expirationTimestamp=1709546400000&signature=zX05AjmzQu-0SZYXxvxjlndyQahM8uGNTCHTOZp1qfY&download=true&downloadName=chi_sim.traineddata
# 测试 - 使用
编写测试类进行测试:
package com.heima.tess4j; | |
import net.sourceforge.tess4j.ITesseract; | |
import net.sourceforge.tess4j.Tesseract; | |
import java.io.File; | |
public class Application { | |
public static void main(String[] args) { | |
try { | |
// 获取本地图片 | |
File file = new File("D:\\26.png"); | |
// 创建 Tesseract 对象 | |
ITesseract tesseract = new Tesseract(); | |
// 设置字体库路径 | |
tesseract.setDatapath("E:\\tessdata"); | |
// 中文识别 | |
tesseract.setLanguage("chi_sim"); | |
// 执行 ocr 识别 | |
String result = tesseract.doOCR(file); | |
// 替换回车和 tal 键 使结果为一行 | |
result = result.replaceAll("\\r|\\n","-").replaceAll(" ",""); | |
System.out.println("识别的结果为:"+result); | |
} catch (Exception e) { | |
e.printStackTrace(); | |
} | |
} | |
} |
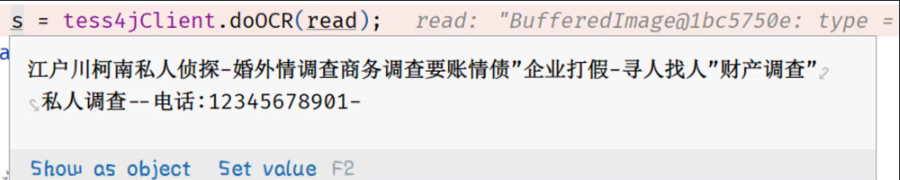
输出结果为如下: