# 一、概述
# 1.1 函数式编程思想
面相对象需要关注用什么对象完成什么事情,二函数式编程思想就类似于我们数学中的函数,它主要关注的是对数据进行了什么操作
# 1.2 优点
- 代码简介,开发快速
- 接近自然语言,易于理解
- 易于 "并发编程"
# 二、Lambda 表达式
# 2.1 概述
Lambda 是 JDK8 中一个语法糖,可以看成是一种语法糖,它可以对某些匿名内部类的代码进行简化,它是函数式编程思想的一个重要体现,让我们不用关注是什么对象,而是更关注我们对数据进行了什么操作
# 2.2 核心原则
可推导可省略
# 2.3 基本格式
(参数列表) -> {代码} |
# 例一
我们在创建线程并启动时可以使用匿名内部类的写法:
new Thread(new Runnable() { | |
@Override | |
public void run() | |
{ | |
System.out.println("hello"); | |
} | |
}).start(); |
可以使用 Lambda 的格式对其进行修改,修改后如下:
new Thread(() -> { | |
System.out.println("hello"); | |
}).start(); |
PS:什么情况下才可以使用 Lambda 进行简化呢?原则:如果这个匿名内部类是一个接口并且其中只有一个抽象方法的时候我们就可以对它进行简化
# 例二
现有方法定义如下,其中 IntBinaryOperator 是一个接口,先使用匿名内部类的写法调用该方法
public static int calculateNum(IntBinaryOperator operator) | |
{ | |
int a = 10; | |
int b = 10; | |
return operator.applyAsInt(a, b); | |
} | |
public static void main(String... args) | |
{ | |
} |
lambda 写法:
public static void main(String[] args) | |
{ | |
int i = calculateNum(new IntBinaryOperator() | |
{ | |
@Override | |
public int applyAsInt(int left, int right) | |
{ | |
return left + right; | |
} | |
}); | |
System.out.println(i); | |
} | |
public static int calculateNum(IntBinaryOperator operator) | |
{ | |
int a = 10; | |
int b = 10; | |
return operator.applyAsInt(a, b); | |
} |
lambda 简化写法:
public static void main(String[] args) | |
{ | |
int i = calculateNum((left, right) -> left + right); | |
System.out.println(i); | |
} | |
public static int calculateNum(IntBinaryOperator operator) | |
{ | |
int a = 10; | |
int b = 10; | |
return operator.applyAsInt(a, b); | |
} |
结果都是:20
# 例三
现有方法定义如下,其中 IntPredicate 是一个接口,先使用匿名内部类的写法调用该方法
public static void main(String[] args) | |
{ | |
printNum(new IntPredicate() | |
{ | |
@Override | |
public boolean test(int value) | |
{ | |
return value % 2 == 0; | |
} | |
}); | |
} | |
public static void printNum(IntPredicate predicate) | |
{ | |
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; | |
for (int i : arr) | |
{ | |
if(predicate.test(i)) | |
{ | |
System.out.println(i); | |
} | |
} | |
} |
lambda 简化写法:
public static void main(String[] args) | |
{ | |
printNum(value -> value % 2 == 0); | |
} | |
public static void printNum(IntPredicate predicate) | |
{ | |
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; | |
for (int i : arr) | |
{ | |
if(predicate.test(i)) | |
{ | |
System.out.println(i); | |
} | |
} | |
} |
结果都是:2,4,6,8,10
# 例四
现有方法定义如下,其中 Function 是一个接口,现使用匿名内部类的写法调用该方法
public static void main(String[] args) | |
{ | |
Integer i = typeConver(new Function<String, Integer>() | |
{ | |
@Override | |
public Integer apply(String s) | |
{ | |
return Integer.valueOf(s); | |
} | |
}); | |
System.out.println(i); | |
} | |
public static <R> R typeConver(Function<String, R> function) | |
{ | |
String str = "12345"; | |
R result = function.apply(str); | |
return result; | |
} |
lambda 简化写法:
public static void main(String[] args) | |
{ | |
Integer i = typeConver(s -> Integer.valueOf(s)); | |
System.out.println(i); | |
} | |
public static <R> R typeConver(Function<String, R> function) | |
{ | |
String str = "12345"; | |
R result = function.apply(str); | |
return result; | |
} |
# 2.4 省略规则
- 参数类型可以省略
- 方法体只有一句代码时大括号 return 和唯一一句代码的分号可以省略
- 方法只有一个参数时小括号可以省略
# 三、stream 流
# 3.1 概述
java8 的 stream 使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合或数组进行链状流式的操作,可以方便的让我们对集合或数组操作
# 3.2 案例数据准备
@Data | |
@NoArgsConstructor | |
@AllArgsConstructor | |
@EqualsAndHashCode // 用于后期的去重使用 | |
public class Author { | |
// id | |
private Long id; | |
// 姓名 | |
private String name; | |
// 年龄 | |
private Integer age; | |
// 简介 | |
private String intro; | |
// 作品 | |
private List<Book> books; | |
} |
@Data | |
@NoArgsConstructor | |
@AllArgsConstructor | |
@EqualsAndHashCode // 用于后期的去重使用 | |
public class Book { | |
// id | |
private Long id; | |
// 书名 | |
private String name; | |
// 分类 | |
private String category; | |
// 评分 | |
private Integer score; | |
// 简介 | |
private String intro; | |
} |
public static void main(String[] args) | |
{ | |
System.out.println(getAuthors()); | |
} | |
public static List<Author> getAuthors() { | |
// 数据初始化 | |
Author author = new Author(1L, "demo", 33, "demo01", null); | |
Author author2 = new Author(2L, "demo1", 23, "demo02", null); | |
Author author3 = new Author(3L, "demo2", 13, "demo03", null); | |
Author author4 = new Author(3L, "demo3", 43, "demo04", null); | |
// 书籍列表 | |
List<Book> books1 = new ArrayList<>(); | |
List<Book> books2 = new ArrayList<>(); | |
List<Book> books3 = new ArrayList<>(); | |
books1.add(new Book(1L, "aaa", "aaa1", 88, "aaa3")); | |
books1.add(new Book(2L, "bbb", "bbb1", 48, "bbb3")); | |
books2.add(new Book(3L, "ccc", "ccc1", 68, "ccc3")); | |
books2.add(new Book(3L, "ddd", "ddd1", 38, "ddd3")); | |
books2.add(new Book(4L, "eee", "eee1", 18, "eee3")); | |
books3.add(new Book(5L, "fff", "fff1", 82, "fff3")); | |
books3.add(new Book(6L, "ggg", "ggg1", 84, "ggg3")); | |
books3.add(new Book(6L, "hhh", "hhh1", 85, "hhh3")); | |
author.setBooks(books1); | |
author2.setBooks(books2); | |
author3.setBooks(books3); | |
author4.setBooks(books3); | |
List<Author> authorList = new ArrayList<>(Arrays.asList(author, author2, author3, author4)); | |
return authorList; | |
} |
打印结果:
[Author(id=1, name=demo, age=33, intro=demo01, books=[Book(id=5, name=fff, category=fff1, score=82, intro=fff3), Book(id=6, name=ggg, category=ggg1, score=84, intro=ggg3), Book(id=6, name=hhh, category=hhh1, score=85, intro=hhh3)]), Author(id=2, name=demo1, age=23, intro=demo02, books=null), Author(id=3, name=demo2, age=13, intro=demo03, books=null), Author(id=3, name=demo3, age=43, intro=demo04, books=null)]
# 3.3 快速入门
# 3.3.1 需求
我们可以调用 getAuthors 方法获取到作家的集合,现在需要打印所有年龄小于 18 的作家的名字,并且注意去重。
# 3.3.2 实现
public static void main(String[] args) | |
{ | |
getAuthors().stream().distinct().filter(e -> e.getAge() < 18) | |
.forEach(e -> System.out.println(e)); | |
} |
打印结果:
Author(id=3, name=demo2, age=13, intro=demo03, books=null)
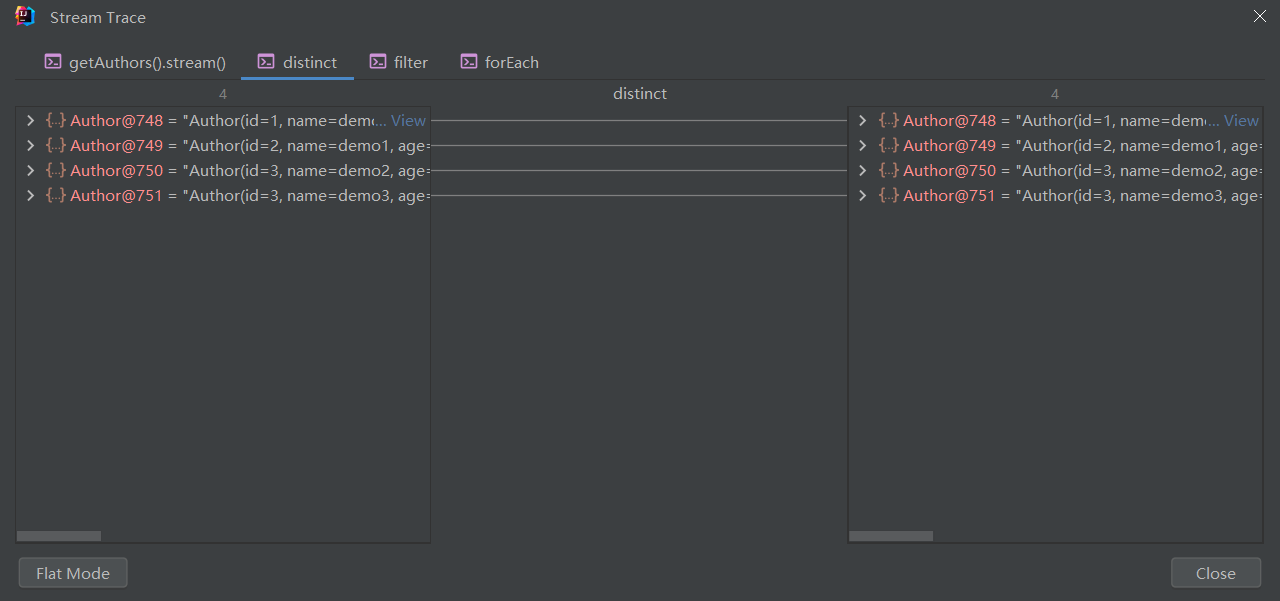
# 如何 debug 查看流程结果呢?
点击 Trace Current Stream Chain
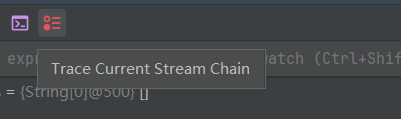
我们可以清除的看到它帮我们计算出来的流程结果了
# 3.4 常用操作
# 3.4.1 创建流
单列集合: 集合对象.stream()
List<Author> authors = getAuthors(); | |
Stream<Author> stream = authors.stream(); |
数组: Arrays.stream(数组)或者使用Stream.of来创建
Integer arr[] = {1, 2, 3, 4, 5}; | |
Stream<Integer> stream = Arrays.stream(arr); | |
Stream<Integer> stream2 = Stream.of(arr); |
双列集合:转换成单列集合后再创建
Map<String, Integer> map = new HashMap<>(); | |
map.put("demo", 19); | |
map.put("demo1", 17); | |
map.put("demo2", 16); | |
Stream<Map.Entry<String, Integer>> stream = map.entrySet().stream(); |
# 3.4.2 中间操作
# filter
可以对流中的元素进行条件过滤,符合过滤条件的才能继续留在流中
例如:
打印所有姓名长度大于 1 的作家的姓名
List<Author> authors = getAuthors(); | |
authors.stream() | |
.filter(author -> author.getName().length() > 1) | |
.forEach(author -> System.out.println(author.getName)); |
# map
可以把对流中的元素进行计算或转换
例如:
打印所有作家的姓名
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> "作家姓名:" + author.getName()) | |
.forEach(name -> System.out.println(name)); | |
//------------------------------------------------------ | |
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getAge()) | |
.map(age -> age + 10) | |
.forEach(age -> System.out.println(age)); |
# distinct
可以去除流中重复的元素
例如:
打印所有作家的姓名,并且要求其中不能有重复元素
List<Author> authors = getAuthors(); | |
authors.stream() | |
.distinct() | |
.forEach(author -> System.out.println(author.getName())); |
注意:distinc 方法是依赖 Object 的 equals 方法来判断是否相同对象的,所以需要注意重写 equals 方法
# sorted
可以对流中的元素进行排序
sorted ():需要在排序的对象中 实现 Comparable<Object> 接口并重写 CompareTo (Object o) 方法来定义排序规则
sorted (Comparator<? super Author> comparator ):Comparator 接口中提供了 compare 方法来定义排序规则
例如:只演示 有参方法
对流中的元素按照年龄进行降序排序,并且要求不能有重复元素
List<Author> authors = getAuthors(); | |
authors.stream() | |
.distinct() | |
.sorted((o1, o2) -> o2.getAge() - o1.getAge()) | |
.forEach(author -> System.out.println(author)); |
注意:如果调用空参的 sorted 方法时,需要流中的元素 (需要排序的类) 实现了 Comparable 接口并重写 CompareTo 来定义排序规则
# limit
可以设置流的最大长度,超出的部分将被抛弃
例如:
对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素,然后打印其中年龄最大的两个作家的姓名
List<Author> authors = getAuthors(); | |
authors.stream() | |
.distinct() | |
.sorted((o1, o2) -> o2.getAge() - o1.getAge()) | |
.limit(10) // 限制流的最大长度为 10 个数据 | |
.forEach(author -> System.out.println(author.getName())); |
# skip
跳过流中的前 n 个元素,返回剩下的元素
例如:
打印除了年龄最大的作家外的其它作家,要求不能有重复元素,并且按照年龄降序排序
List<Author> authors = getAuthors(); | |
authors.stream() | |
.distinct() | |
.sorted((o1, o2) -> o2.getAge() - o1.getAge()) | |
.sikp(1) // 跳过前一个元素 | |
.forEach(author -> System.out.println(author.getName())); |
# flatMap
map 只能把一个对象转换成另一个对象来作为流中的元素,而 flatMap 可以把一个对象转换成多个对象作为流中的元素
例一:
打印所有书籍的名字,要求对重复的元素进行去重
List<Author> authors = getAuthors(); | |
authors().stream() | |
.flatMap(author -> author.getBooks().stream()) | |
.distinct() | |
.forEach(book -> System.out.println(book.getName())); |
流程分析:将 author 对象中的所有 Books 集合转换为流作为一个 Book 对象
debug
如下将不同的流对象里面的 List<Books> 集合转换为对应的对象,将一个流转换为多个流到 Stream 中
# 3.4.3 终结操作
# forEach
对流中的元素进行遍历操作,我们通过传入的参数去指定对遍历到的元素进行什么具体操作
例子:
输出所有作家的名字
List<Author> authors = getAuthors(); | |
authors().stream() | |
.forEach(author -> System.out.println(author.getName())); |
# count
可以用来获取当前流中元素的个数
例子:
打印这些作家的所出书籍的数目,注意去除重复元素
List<Author> authors = getAuthors(); | |
long count = authors().stream() | |
.flatMap(author -> author.getBooks().stream()) | |
.distinct() | |
.count(); |
# max&min
可以用来获取流中的最 (大 / 小) 值
例子:
分别获取这些作家的所出书籍的最高分和最低分并打印
最大值
List<Author> authors = getAuthors(); | |
Optional<Integer> max = authors().stream() | |
.flatMap(author -> author.getBooks().stream()) | |
.map(book -> book.getScore()) | |
.max((o1, o2) -> o1 - o2); | |
System.out.println(max.get()); |
最小值
List<Author> authors = getAuthors(); | |
Optional<Integer> max = authors().stream() | |
.flatMap(author -> author.getBooks().stream()) | |
.map(book -> book.getScore()) | |
.min((o1, o2) -> o1 - o2); | |
System.out.println(max.get()); |
# collect
把当前流转换成一个集合
例子:
获取一个存放所有作者名字的 List 集合
List<String> collect = getAuthors().stream() | |
.map(author -> author.getName()) | |
.collect(Collectors.toList()); |
获取一个所有书名的 Set 集合
Set<String> collect = getAuthors().stream() | |
.flatMap(author -> author.getBooks().stream()) | |
.map(book -> book.getName()) | |
.collect(Collectors.toSet()); |
获取一个 map 集合,map 的 key 为作者名,value 为 List<Book>
Map<String, List<Book>> collect = getAuthors().stream() | |
.collect(Collectors.toMap(e -> e.getName(), e1 -> e1.getBooks())); | |
System.out.println(collect); |
打印结果:
{demo3=[Book(id=5, name=fff, category=fff1, score=82, intro=fff3), Book(id=6, name=ggg, category=ggg1, score=84, intro=ggg3), Book(id=6, name=hhh, category=hhh1, score=85, intro=hhh3)], demo=[Book(id=1, name=aaa, category=aaa1, score=88, intro=aaa3), Book(id=2, name=bbb, category=bbb1, score=48, intro=bbb3)], demo1=[Book(id=3, name=ccc, category=ccc1, score=68, intro=ccc3), Book(id=3, name=ddd, category=ddd1, score=38, intro=ddd3), Book(id=4, name=eee, category=eee1, score=18, intro=eee3)], demo2=[Book(id=5, name=fff, category=fff1, score=82, intro=fff3), Book(id=6, name=ggg, category=ggg1, score=84, intro=ggg3), Book(id=6, name=hhh, category=hhh1, score=85, intro=hhh3)]}
获取一个 map 集合,map 的 key 为作者名,value 为 List<String> 书名的集合
Map<String, List<String>> collect = getAuthors().stream() | |
.collect(Collectors.toMap(e -> e.getName(), e1 -> e1.getBooks().stream().map(o -> o.getName()).collect(Collectors.toList()))); | |
System.out.println(collect); |
打印结果:
{demo3=[fff, ggg, hhh], demo=[aaa, bbb], demo1=[ccc, ddd, eee], demo2=[fff, ggg, hhh]}
PS:如果我们在使用 key 为作者名的时候 key 是不能重复的比如我更改两个重复的作者名
// 数据初始化 | |
Author author = new Author(1L, "demo", 33, "demo01", null); | |
Author author2 = new Author(2L, "demo1", 23, "demo02", null); | |
Author author3 = new Author(3L, "demo2", 13, "demo03", null); | |
Author author4 = new Author(3L, "demo2", 13, "demo03", null); |
然后我们在运行代码:
Map<String, List<Book>> collect = getAuthors().stream() | |
.collect(Collectors.toMap(e -> e.getName(), e1 -> e1.getBooks())); | |
System.out.println(collect); |
运行结果:
Exception in thread "main" java.lang.IllegalStateException: Duplicate key [Book(id=5, name=fff, category=fff1, score=82, intro=fff3), Book(id=6, name=ggg, category=ggg1, score=84, intro=ggg3), Book(id=6, name=hhh, category=hhh1, score=85, intro=hhh3)]
at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1255)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1320)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at com.dkx.StreamDemo.main(StreamDemo.java:14)
报错了,说 key 不能重复,因此我们可以使用去重来解决这个问题
Map<String, List<Book>> collect = getAuthors().stream() | |
.distinct() | |
.collect(Collectors.toMap(e -> e.getName(), e1 -> e1.getBooks())); | |
System.out.println(collect); |
打印结果:
{demo=[Book(id=1, name=aaa, category=aaa1, score=88, intro=aaa3), Book(id=2, name=bbb, category=bbb1, score=48, intro=bbb3)], demo1=[Book(id=3, name=ccc, category=ccc1, score=68, intro=ccc3), Book(id=3, name=ddd, category=ddd1, score=38, intro=ddd3), Book(id=4, name=eee, category=eee1, score=18, intro=eee3)], demo2=[Book(id=5, name=fff, category=fff1, score=82, intro=fff3), Book(id=6, name=ggg, category=ggg1, score=84, intro=ggg3), Book(id=6, name=hhh, category=hhh1, score=85, intro=hhh3)]} |
这时问题就解决了。
# 查找与匹配
# anyMatch
可以用来判断是否有任意符合匹配条件的元素,结果为 boolean 类型
例子:
判断是否有年龄在 29 以上的作家
boolean b = getAuthors().stream() | |
.anyMatch(author -> author.getAge() > 29); | |
System.out.println(b);// true |
# allMatch
可以用来判断是否都符合匹配条件,结果为 boolean 类型。如果都符合结果为 true,否则结果为 false
例子:
判断是否所有的作家都是成年人
boolean b = getAuthors().stream() | |
.allMatch(author -> author.getAge() >= 18); | |
System.out.println(b);// false |
# noneMatch
可以判断流中的元素是否都符合匹配条件,如果都不符合结果为 true,否则结果为 false
例子:
判断作家是否都没有超过 100 岁的
boolean b = getAuthors().stream() | |
.noneMatch(author -> author.getAge() >= 100); | |
System.out.println(b);// true |
# findAny
获取流中的任意一个元素,该方法没有办法保证获取的一定是流中的第一个元素
PS:使用场景并不多,因为它是随机性的并不是一定获取的就是第一个元素 (推荐使用 findFirst)
例子:
获取任意一个年龄大于 18 的作家,如果存在就输出它的名字
Optional<Author> any = getAuthors().stream() | |
.filter(author -> author.getAge() > 18) | |
.findAny(); | |
//ifPresent 可以避免空指针异常的出现,如果有值就正常输出,如果没有值就不输出也不抛出异常 | |
any.ifPresent(e -> System.out.println(e.getName())); |
# findFirst
获取流中的第一个元素
例子:
获取一个年龄最小的作家, 并输出它的姓名。
Optional<Author> first = getAuthors().stream() | |
.sorted((o1, o2) -> o1.getAge() - o2.getAge()) | |
.findFirst(); | |
first.ifPresent(e -> System.out.println(e.getName())); |
# reduce 归并
对流中的数据按照你制定的计算方式计算出一个结果。(缩减操作)
reduce 的作用是把 stream 中的元素给组合起来,我们可以传入一个初始值,它会按照我们的计算方式依次拿流中的元素和在初始化值的基础上进行计算,计算结果再和后面的元素计算
它内部的计算方式如下:
T result = identity; | |
for (T element : this stream) | |
result = accumulator.apply(result, element) | |
return result; |
其中 identity 就是我们可以通过方法参数传入的初始值,accumulator 的 apply 具体进行什么计算也是我们通过方法参数来确定的
例子:
使用 reduce 求所有作者年龄的和
Integer reduce = getAuthors().stream() | |
.map(author -> author.getAge()) | |
// 0: 从几开始相加,result 结果 + element 当前值 | |
.reduce(0, (result, element) -> result + element); |
使用 reduce 求所有作者中年龄的最大值
Integer reduce = getAuthors().stream() | |
.map(author -> author.getAge()) | |
.reduce(Integer.MIN_VALUE, (result, element) -> result < element ? element : result); |
使用 reduce 求所有作者中年龄的最小值
Integer reduce = getAuthors().stream() | |
.map(author -> author.getAge()) | |
.reduce(Integer.MAX_VALUE, (result, element) -> result > element ? element : result) |
reduce 一个参数的重载形式内部的计算
boolean foundAny = false; | |
T result = null; | |
for (T element : this stream) { | |
if (!foundAny) { | |
foundAny = true; | |
result = element; | |
} | |
else | |
result = accumulator.apply(result, element); | |
} | |
return foundAny ? Optional.of(result) : Optional.empty(); |
就是把流当中 第一个元素作为 初始化值 进行后面的计算
如果使用一个参数的重载方法求最小值的代码如下:
Optional<Integer> reduce = getAuthors().stream() | |
.map(author -> author.getAge()) | |
.reduce((result, element) -> result > element ? element : result); | |
reduce.ifPresent(r -> System.out.pintln(r.get())); |
# GroupingBy 用法大全
java8 中,Collectors.groupingBy 会用得比较多,对其常见用法做一个汇总
# 模拟数据
item
import java.math.BigDecimal; | |
public class Item { | |
private String name; | |
private Integer quantity; | |
private BigDecimal price; | |
public Item(String name, int quantity, BigDecimal price) { | |
this.name = name; | |
this.quantity = quantity; | |
this.price = price; | |
} | |
public String getName() { | |
return name; | |
} | |
public void setName(String name) { | |
this.name = name; | |
} | |
public Integer getQuantity() { | |
return quantity; | |
} | |
public void setQuantity(Integer quantity) { | |
this.quantity = quantity; | |
} | |
public BigDecimal getPrice() { | |
return price; | |
} | |
public void setPrice(BigDecimal price) { | |
this.price = price; | |
} | |
} |
# 数据
public static List<Item> initData(){ | |
List<Item> items = Arrays.asList(new Item("apple", 20, new BigDecimal("4.99")), | |
new Item("apple", 30, new BigDecimal("7.99")), | |
new Item("apple", 10, new BigDecimal("9.99")), | |
new Item("banana", 30, new BigDecimal("2.99")), | |
new Item("banana", 20, new BigDecimal("6.99")), | |
new Item("orange", 50, new BigDecimal("3.99")), | |
new Item("orange", 20, new BigDecimal("8.99")), | |
new Item("watermelon", 200, new BigDecimal("2.99")), | |
new Item("watermelon", 100, new BigDecimal("5.99")), | |
new Item("kiwi fruit", 40, new BigDecimal("5.88")), | |
new Item("kiwi fruit", 20, new BigDecimal("8.88"))); | |
return items; | |
} |
# 用法
# groupingBy
// 根据水果名称分组 | |
private static void groupingBy(){ | |
List<Item> items = initData(); | |
Map<String, List<Item>> itemGroupBy = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName)); | |
System.out.println(JSON.toJSONString(itemGroupBy)); | |
} |
结果:
{ | |
"orange": [{ | |
"name": "orange", | |
"price": 3.99, | |
"quantity": 50 | |
}, { | |
"name": "orange", | |
"price": 8.99, | |
"quantity": 20 | |
}], | |
"banana": [{ | |
"name": "banana", | |
"price": 2.99, | |
"quantity": 30 | |
}, { | |
"name": "banana", | |
"price": 6.99, | |
"quantity": 20 | |
}], | |
"apple": [{ | |
"name": "apple", | |
"price": 4.99, | |
"quantity": 20 | |
}, { | |
"name": "apple", | |
"price": 7.99, | |
"quantity": 30 | |
}, { | |
"name": "apple", | |
"price": 9.99, | |
"quantity": 10 | |
}], | |
"kiwi fruit": [{ | |
"name": "kiwi fruit", | |
"price": 5.88, | |
"quantity": 40 | |
}, { | |
"name": "kiwi fruit", | |
"price": 8.88, | |
"quantity": 20 | |
}], | |
"watermelon": [{ | |
"name": "watermelon", | |
"price": 2.99, | |
"quantity": 200 | |
}, { | |
"name": "watermelon", | |
"price": 5.99, | |
"quantity": 100 | |
}] | |
} |
# groupingCounting
// 统计水果的种类 | |
private static void groupingCounting(){ | |
List<Item> items = initData(); | |
Map<String, Long> itemGroupCount = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, Collectors.counting())); | |
System.out.println(JSON.toJSONString(itemGroupCount)); | |
} |
结果:
{ | |
"orange": 2, | |
"banana": 2, | |
"apple": 3, | |
"kiwi fruit": 2, | |
"watermelon": 2 | |
} |
# groupingSum
// 统计各水果的总数量 | |
private static void groupingSum(){ | |
List<Item> items = initData(); | |
Map<String, Integer> itemGroupSum = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.summingInt(Item::getQuantity))); | |
System.out.println(JSON.toJSONString(itemGroupSum)); | |
} |
结果:
{ | |
"orange": 70, | |
"banana": 50, | |
"apple": 60, | |
"kiwi fruit": 60, | |
"watermelon": 300 | |
} |
# groupingMax
// 统计各水果中数量最多的那个 | |
private static void groupingMax(){ | |
List<Item> items = initData(); | |
Map<String, Item> itemGroupMax = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Item::getQuantity)), Optional::get))); | |
System.out.println(JSON.toJSONString(itemGroupMax)); | |
Map<String, Item> itemGroupMaxMap = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.toMap(Item::getName, Function.identity(), | |
BinaryOperator.maxBy(Comparator.comparingInt(Item::getQuantity)))); | |
System.out.println(JSON.toJSONString(itemGroupMaxMap)); | |
} |
结果:
{ | |
"orange": { | |
"name": "orange", | |
"price": 3.99, | |
"quantity": 50 | |
}, | |
"banana": { | |
"name": "banana", | |
"price": 2.99, | |
"quantity": 30 | |
}, | |
"apple": { | |
"name": "apple", | |
"price": 7.99, | |
"quantity": 30 | |
}, | |
"kiwi fruit": { | |
"name": "kiwi fruit", | |
"price": 5.88, | |
"quantity": 40 | |
}, | |
"watermelon": { | |
"name": "watermelon", | |
"price": 2.99, | |
"quantity": 200 | |
} | |
} |
Collectors.collectingAndThen 聚合后再操作
其参数:
collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher) |
# grouping mapping
// 统计各水果的价格 | |
private static void groupingSet(){ | |
List<Item> items = initData(); | |
Map<String, Set<BigDecimal>> itemGroupSet = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.mapping(Item::getPrice, Collectors.toSet()))); | |
System.out.println(JSON.toJSONString(itemGroupSet)); | |
Map<String, List<BigDecimal>> itemGroupList = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.mapping(Item::getPrice, Collectors.toList()))); | |
System.out.println(JSON.toJSONString(itemGroupList)); | |
} |
结果
{ | |
"orange": [3.99, 8.99], | |
"banana": [2.99, 6.99], | |
"apple": [7.99, 9.99, 4.99], | |
"kiwi fruit": [5.88, 8.88], | |
"watermelon": [2.99, 5.99] | |
} |
# groupingMap
// 统计各水果的数量对应价格 | |
private static void groupingMap(){ | |
List<Item> items = initData(); | |
Map<String, Map<Integer, BigDecimal>> itemGroupMap = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.toMap(Item::getQuantity, Item::getPrice, (x, y) -> x))); | |
System.out.println(JSON.toJSONString(itemGroupMap)); | |
Map<String, Map<Integer, BigDecimal>> itemGroupMap2 = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, Collectors | |
.collectingAndThen(Collectors.toMap(Item::getQuantity, Item::getPrice), v -> v))); | |
System.out.println(JSON.toJSONString(itemGroupMap2)); | |
} |
结果
{ | |
"orange": { | |
50: 3.99, | |
20: 8.99 | |
}, | |
"banana": { | |
20: 6.99, | |
30: 2.99 | |
}, | |
"apple": { | |
20: 4.99, | |
10: 9.99, | |
30: 7.99 | |
}, | |
"kiwi fruit": { | |
20: 8.88, | |
40: 5.88 | |
}, | |
"watermelon": { | |
100: 5.99, | |
200: 2.99 | |
} | |
} |
第一种更为简便
# groupingAvg
// 统计各水果的平均数量 int double long 三种类型 | |
private static void groupingAvg(){ | |
List<Item> items = initData(); | |
Map<String, Double> itemGroupAvg = ListUtils.emptyIfNull(items).stream() | |
.collect(Collectors.groupingBy(Item::getName, | |
Collectors.averagingInt(Item::getQuantity))); | |
System.out.println(JSON.toJSONString(itemGroupAvg)); | |
} |
结果
{ | |
"orange": 35.0, | |
"banana": 25.0, | |
"apple": 20.0, | |
"kiwi fruit": 30.0, | |
"watermelon": 150.0 | |
} |
# 总结
常见使用聚合再进行 map 处理,用于匹配数据。了解 Collectors.collectingAndThen 的用法,聚合后再进行操作。写不来就分两步写,先完成,再优化
# Collectors 操作
学习了 groupingBy 的用法,里面会经常用到 Collectors.collectingAndThen,我理解为后续操作。
# JDK 原码
java.util.stream.Collectors#collectingAndThen 方法的作用是将 Collector 的结果在执行一个额外的 finisher 转换操作,其源码如下:
/** | |
* Adapts a {@code Collector} to perform an additional finishing | |
* transformation. For example, one could adapt the {@link #toList()} | |
* collector to always produce an immutable list with: | |
* <pre>{@code | |
* List<String> people | |
* = people.stream().collect(collectingAndThen(toList(), Collections::unmodifiableList)); | |
* }</pre> | |
* | |
* @param <T> the type of the input elements | |
* @param <A> intermediate accumulation type of the downstream collector | |
* @param <R> result type of the downstream collector | |
* @param <RR> result type of the resulting collector | |
* @param downstream a collector | |
* @param finisher a function to be applied to the final result of the downstream collector | |
* @return a collector which performs the action of the downstream collector, | |
* followed by an additional finishing step | |
*/ | |
public static<T, A, R, RR> Collector<T, A, RR> collectingAndThen(Collector<T, A, R> downstream, Function<R, RR> finisher) { | |
Set<Collector.Characteristics> characteristics = downstream.characteristics(); | |
if (characteristics.contains(Collector.Characteristics.IDENTITY_FINISH)) { | |
if (characteristics.size() == 1) { | |
characteristics = Collectors.CH_NOID; | |
} else { | |
characteristics = EnumSet.copyOf(characteristics); | |
characteristics.remove(Collector.Characteristics.IDENTITY_FINISH); | |
characteristics = Collections.unmodifiableSet(characteristics); | |
} | |
} | |
return new CollectorImpl<>(downstream.supplier(), | |
downstream.accumulator(), | |
downstream.combiner(), | |
downstream.finisher().andThen(finisher), | |
characteristics); | |
} |
T:输入元素的类型
A:下游 Collector 的结果类型
R:下游 Collector 的结果类型
RR:结果 Collector 的结果类型
参数:此方法接受下面列出的两个参数
dwnstream:Collector 的一个实例,可以使用任何 Collector
finisher:类型是 Function,该函数将应用于下游 Collector 的 最终结果
返回值:返回一个执行下游 Collector 动作的 Collector,然后在 finisher 函数的帮助下执行附加的转换步骤。
# 使用
模拟数据:
public static JSONArray initData(){ | |
String data = "[{\"code\":\"4\",\"codeType\":\"ALRAM\",\"sortId\":\"4\",\"name\":\"特级告警\"},{\"code\":\"2\",\"codeType\":\"ALRAM\",\"sortId\":\"2\",\"name\":\"中级告警\"},{\"code\":\"3\",\"codeType\":\"ALRAM\",\"sortId\":\"3\",\"name\":\"严重告警\"},{\"code\":\"1\",\"codeType\":\"ALRAM\",\"sortId\":\"1\",\"name\":\"普通告警\"},{\"code\":\"2\",\"codeType\":\"NOTICE\",\"sortId\":\"2\",\"name\":\"邮箱通知\"},{\"code\":\"1\",\"codeType\":\"NOTICE\",\"sortId\":\"1\",\"name\":\"短信通知\"},{\"code\":\"3\",\"codeType\":\"NOTICE\",\"sortId\":\"3\",\"name\":\"微信消息通知\"}]"; | |
return JSON.parseArray(data); | |
} |
# mapping
Collectors.mapping 是 java StreamAPI 中的一个收集器,用于在 Stream.collect 操作中对元素进行映射,然后再将映射后的结果收集到一个下游的收集器中。
它的作用是将元素通过一个 Function 映射到某种值,并将这些值交给下游收集器进行处理。换句话说,它提供了一种在数据收集过程中对流中的元素进行转换的简便方式。
使用场景
根据条件组分并提取字段
假设我们想将 Person 列表按照年龄段分组,并且只收集每组中的名字:
List<Person> people = Arrays.asList( | |
new Person("Alice", 30), | |
new Person("Bob", 25), | |
new Person("Charlie", 35) | |
); | |
Map<Boolean, List<String>> result = people.stream() | |
.collect(Collectors.groupingBy( | |
p -> p.getAge() > 30, // 根据年龄是否大于 30 分组 | |
Collectors.mapping(Person::getName, Collectors.toList()) // 提取名字并收集到列表中 | |
)); | |
System.out.println(result); | |
// 输出: {false=[Bob], true=[Alice, Charlie]} |
# 疑问:Stream 中可以使用 map 来映射某个值为什么还要 Collectors.mapping 呢?
# 主要区别
1. 工作时机不同
- map () 是流操作的中间处理方法,它会生成一个新的流,你可以在流的中间阶段使用它做转换操作
- Collectors.mapping () 是收集操作的一部分,用于在收集的过程中对元素进行映射。它往往与其他收集器 (如 groupbingBy,paririoningBy 等) 结合使用更为强大和简洁
2。灵活性与组合性
- map () 更适合单纯的转换操作,如果你只是想简单的将流中的元素转换后收集起来,用 map () 是足够的。
- Collectors.mapping () 更适合复杂的场景,尤其是与其它收集器组合时。比如,在分组,分区或者聚合操作中直接映射数据,不需要显示使用 map ()
# 优缺点比较
| 特性 | stream() + Collectors.toList() | Collectors.mapping() |
|---|---|---|
| 适用场景 | 适用于简单的流转换和收集 | 适用于复杂的收集操作组合 |
| 可读性 | 对于简单场景,代码更加直观 | 适合分组,分区等复杂操作 |
| 组合性 | 无法直接与 groupingBy 等收集器组合 | 可与 groupingBy 等收集器组合,更灵活,适合复杂场景 |
| 使用简便性 | 更加直观,适用于简单映射和收集 | 可以减少代码量,更紧凑 |
# 总结
- 如果你的场景只需要简单的映射流中的元素并收集结果,使用 map () + Collectors.toList () 是最直接的做法
- 如果你的场景比较复杂,比如需要进行分组或其它聚合操作,然后再进行映射,Collectors.mapping () 会让代码更加简洁
# toList
获取字段类型的各名称
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, List<String>> codeTypeNameMap1 = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), Collectors | |
.collectingAndThen(Collectors.toList(), | |
t -> ListUtils.emptyIfNull(t).stream().map(x -> MapUtils.getString(x, "name")) | |
.filter(Objects::nonNull).distinct().collect(Collectors.toList())))); | |
System.out.println(JSON.toJSONString(codeTypeNameMap1)); | |
} |
结果:
{ | |
"NOTICE": ["邮箱通知", "短信通知", "微信消息通知"], | |
"ALRAM": ["特级告警", "中级告警", "严重告警", "普通告警"] | |
} |
不过这种写法会有点繁琐,使用 mapping 更为简便直观
Map<String, List<String>> codeTypeNameMap2 = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
Collectors.mapping(f1 -> MapUtils.getString(f1, "name"), Collectors.toList()))); | |
System.out.println(JSON.toJSONString(codeTypeNameMap2)); |
# toMap
获取字段类型的字典及其名称
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, Map<String, String>> codeTypeMap1 = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
Collectors.collectingAndThen(Collectors.toMap(f1 -> MapUtils.getString(f1, "code"), | |
f2 -> MapUtils.getString(f2, "name"), (x, y) -> x), v -> v))); | |
System.out.println(JSON.toJSONString(codeTypeMap1)); | |
} |
结果:
{ | |
"NOTICE": { | |
"1": "短信通知", | |
"2": "邮箱通知", | |
"3": "微信消息通知" | |
}, | |
"ALRAM": { | |
"1": "普通告警", | |
"2": "中级告警", | |
"3": "严重告警", | |
"4": "特级告警" | |
} | |
} |
这个直接用 toMap 的方式也更为简便直观
Map<String, Map<String, String>> codeTypeMap2 = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
Collectors.toMap(f1 -> MapUtils.getString(f1, "code"), | |
f2 -> MapUtils.getString(f2, "name"), (x, y) -> x))); | |
System.out.println(JSON.toJSONString(codeTypeMap2)); |
# maxBy
分组后找到 code 最大的内容
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, JSONObject> codeMax = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(f1 -> MapUtils.getInteger(f1, "code"))), Optional::get))); | |
System.out.println(JSON.toJSONString(codeMax)); | |
} |
结果:
{ | |
"NOTICE": { | |
"code": "3", | |
"codeType": "NOTICE", | |
"sortId": "3", | |
"name": "微信消息通知" | |
}, | |
"ALRAM": { | |
"code": "4", | |
"codeType": "ALRAM", | |
"sortId": "4", | |
"name": "特级告警" | |
} | |
} |
这个可以直接用 toMap 和 BinaryOperator.maxBy 进行处理
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, JSONObject> codeMax = ListUtils.emptyIfNull(items).stream().map(e -> (JSONObject) e) | |
.collect(Collectors.toMap(e -> MapUtils.getString(e, "codeType"), | |
Function.identity(), | |
BinaryOperator.maxBy(Comparator.comparingInt(f1 -> MapUtils.getInteger(f1, "code"))))); | |
System.out.println(JSON.toJSONString(codeMax)); | |
} |
# sort asc
分组后,根据 sortId 进行排序 - 正序
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, List<JSONObject>> groupAscSort = ListUtils.emptyIfNull(items).stream() | |
.map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
LinkedHashMap::new, | |
Collectors.collectingAndThen(Collectors.toList(), s -> | |
s.stream().sorted(Comparator.comparing(e -> e.getInteger("sortId"))).collect(Collectors.toList())))); | |
System.out.println(JSON.toJSONString(groupAscSort)); | |
} |
结果:
{ | |
"ALRAM": [{ | |
"code": "1", | |
"codeType": "ALRAM", | |
"sortId": "1", | |
"name": "普通告警" | |
}, { | |
"code": "2", | |
"codeType": "ALRAM", | |
"sortId": "2", | |
"name": "中级告警" | |
}, { | |
"code": "3", | |
"codeType": "ALRAM", | |
"sortId": "3", | |
"name": "严重告警" | |
}, { | |
"code": "4", | |
"codeType": "ALRAM", | |
"sortId": "4", | |
"name": "特级告警" | |
}], | |
"NOTICE": [{ | |
"code": "1", | |
"codeType": "NOTICE", | |
"sortId": "1", | |
"name": "短信通知" | |
}, { | |
"code": "2", | |
"codeType": "NOTICE", | |
"sortId": "2", | |
"name": "邮箱通知" | |
}, { | |
"code": "3", | |
"codeType": "NOTICE", | |
"sortId": "3", | |
"name": "微信消息通知" | |
}] | |
} |
# sort desc
分组后,根据 sortId 进行排序 - 反序
public static void main(String[] args){ | |
JSONArray items = initData(); | |
Map<String, List<JSONObject>> groupReverseSort = ListUtils.emptyIfNull(items).stream() | |
.map(e -> (JSONObject) e) | |
.collect(Collectors.groupingBy(e -> MapUtils.getString(e, "codeType"), | |
LinkedHashMap::new, | |
Collectors.collectingAndThen(Collectors.toList(), s -> | |
s.stream().sorted((c1, c2) -> | |
MapUtils.getInteger(c2, "sortId").compareTo(MapUtils.getInteger(c1, "sortId"))).collect(Collectors.toList())))); | |
System.out.println(JSON.toJSONString(groupReverseSort)); | |
} |
结果:
{ | |
"ALRAM": [{ | |
"code": "4", | |
"codeType": "ALRAM", | |
"sortId": "4", | |
"name": "特级告警" | |
}, { | |
"code": "3", | |
"codeType": "ALRAM", | |
"sortId": "3", | |
"name": "严重告警" | |
}, { | |
"code": "2", | |
"codeType": "ALRAM", | |
"sortId": "2", | |
"name": "中级告警" | |
}, { | |
"code": "1", | |
"codeType": "ALRAM", | |
"sortId": "1", | |
"name": "普通告警" | |
}], | |
"NOTICE": [{ | |
"code": "3", | |
"codeType": "NOTICE", | |
"sortId": "3", | |
"name": "微信消息通知" | |
}, { | |
"code": "2", | |
"codeType": "NOTICE", | |
"sortId": "2", | |
"name": "邮箱通知" | |
}, { | |
"code": "1", | |
"codeType": "NOTICE", | |
"sortId": "1", | |
"name": "短信通知" | |
}] | |
} |
# 总结
Collectors.collectingAndThen 除了排序的,另外其它都直接替换。但是也要熟悉,这样当遇到需要进一步处理数据,也不知道有更简便的方法的时候,就可以直接用 Collectors.collectingAndThen 的方式去写。再不行,就分两步写
# 3.5 注意事项
- 惰性求值 (如果没有终结操作,没有中间操作是不会得到执行的)
- 流是一次性的 (一旦一个流对象经过一个终结操作后,这个流就不能再被使用)
- 不会影响原数据 (我们在流中可以多数据做很多处理。但是正常情况下不会影响原来集合中的元素的。这往往也是我们期望的)
针对第二步的说法错误代码演示如下:
Stream<Author> stream = getAuthors().stream(); | |
stream.map(author -> author.getAge()); | |
stream.map(author -> author.getName()); // 报错点 |
错误信息如下:
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)
at java.util.stream.ReferencePipeline.<init>(ReferencePipeline.java:94)
at java.util.stream.ReferencePipeline$StatelessOp.<init>(ReferencePipeline.java:618)
at java.util.stream.ReferencePipeline$3.<init>(ReferencePipeline.java:187)
at java.util.stream.ReferencePipeline.map(ReferencePipeline.java:186)
at com.dkx.StreamDemo.main(StreamDemo.java:14)
我们如果下次还想使用 stream 进行操作,我们需要重新去获取 stream 流而这样就不会报错
Stream<Author> stream = getAuthors().stream(); | |
stream.map(author -> author.getAge()); | |
Stream<Author> stream1 = getAuthors().stream(); | |
stream1.map(author -> author.getName()); |
针对第三步的详细说明如下:
List<Author> authors = getAuthors(); | |
Stream<Author> stream = authors.stream(); | |
stream | |
// 在流中针对 每个 年龄 都加上 10 并输出结果 | |
.map(author -> author.getAge() + 10) | |
.forEach(age -> System.out.println("stream数据:" + age)); | |
// 输出原集合中的数据看看有没有发生变化 | |
authors.forEach(author -> System.out.println("原数据:" + author.getAge())); |
打印结果:
stream数据:43
stream数据:33
stream数据:23
stream数据:23
原数据:33
原数据:23
原数据:13
原数据:13
上面的情况是不会影响到原数据的 这是正常的操作,如果是不正常的操作呢?如下:
List<Author> authors = getAuthors(); | |
Stream<Author> stream = authors.stream(); | |
stream | |
.map(author -> | |
{ | |
// 在流中针对 每个 对象的年龄字段 都加上 10 并输出结果 | |
author.setAge(author.getAge() + 10); | |
return author; | |
}).forEach(author -> System.out.println("stream数据:" + author.getAge())); | |
// 输出原集合中的数据看看有没有发生变化 | |
authors.forEach(author -> System.out.println("原数据:" + author.getAge())); |
打印结果:
stream数据:43
stream数据:33
stream数据:23
stream数据:23
原数据:43
原数据:33
原数据:23
原数据:23
# 四、Optional
非常优雅的避免 空指针异常。
# 4.1 概述
我们在编写代码的时候出现最多的就是空指针异常。所以在很多情况下我们需要做各种非空的判断。
例如:
public static void main(String[] args) | |
{ | |
Author author = getAuthor(); | |
if(author != null) | |
{ | |
System.out.println(author.getName()); | |
} | |
} | |
public static Author getAuthor() | |
{ | |
Author author = new Author(1L, "朵朵", 33, "未知生物", null); | |
return author ;// --> null; | |
} |
尤其是对象中的属性还是一个对象的情况下。这种判断会更多。
而过多的判断语句会让我们的代码显得臃肿不堪
所以在 JDK8 中引入了 Optional,养成使用 Optional 的习惯后你可以写出更优雅的代码来避免空指针异常
并且在很多函数式编程相关 API 中也都用到了 Optional,如果不会使用 Optional 也会对函数式编程的学习造成影响。
# 4.2 使用
# 4.2.1 创建对象
Optional 就好像是包装类,可以把我们的具体数据封装 Optional 对象内部。然后我们去使用 Optional 中封装好的方法操作封装进去的数据就可以非常优雅的避免空指针异常。
我们一般使用 Optional 的静态方法 ofNullable 来把数据封装成一个 Optional 对象。无论传入的参数是否为 null 都不会出现问题。
Author author = getAuthor(); | |
Optional<Author> authorOptional = Optional.ofNullable(author); |
你可能会觉得还要加一行代码来封装数据比较麻烦。但是如果改造下 getAuthor 方法,让其返回值就是封装好的 Optional 的话,我们在使用时就会方便很多。
而且在实际开发中我们的数据很多是从数据库获取的。Mybatis 从 3.5 版本可以也已经支持 Optional 了。我们可以直接把 dao 方法的返回值类型定义成 Optional 类型,Mybatis 会自己把数据封装成 Optinoal 对象返回。封装的过程也不需要我们自己操作。
如果你确定一个对象不是空的则可以使用 Optional 的静态方法 of 来把数据封装成 Optional 对象
Author author = new Author(); | |
Optional<Author> authorOptional = Optional.of(author); |
但是一定要注意,如果使用 of 的时候传入的参数必须不为 null。(尝试下传入 null 会出现什么结果)
public static void main(String[] args) | |
{ | |
Author author = getAuthor(); | |
Optional<Author> authorOptional = Optional.of(author); | |
authorOptional.ifPresent(r -> System.out.println(r.getName())); | |
} | |
public static Author getAuthor() | |
{ | |
Author author = new Author(1L, "朵朵", 33, "未知生物", null); | |
return null; // author ;// --> null; | |
} |
打印结果:
Exception in thread "main" java.lang.NullPointerException
at java.util.Objects.requireNonNull(Objects.java:203)
at java.util.Optional.<init>(Optional.java:96)
at java.util.Optional.of(Optional.java:108)
at com.dkx.StreamDemo01.main(StreamDemo01.java:10)
抛出了空指针异常
如果一个方法的返回值类型是 Optional 类型。而如果我们经判断发现某次计算得到的返回值为 null,这个时候就需要把 null 封装成 Optional 对象返回。这时则可以使用 Optional 的静态方法 empty 来进行封装。
Optional.empty(); |
代码演示:
public static void main(String[] args) | |
{ | |
Optional<Author> authorOptional = getAuthorOptional(); | |
authorOptional.ifPresent(r -> System.out.println(r.getName())); | |
} | |
public static Optional<Author> getAuthorOptional() | |
{ | |
Author author = new Author(1L, "朵朵", 33, "未知生物", null); | |
// 判断如果为 null 则返回一个空的 Optional 对象,如果不为空则使用 of(必须传入不为 null 的对象)返回 Optional 对象 | |
return author == null ? Optional.empty() : Optional.of(author); | |
} |
打印结果:
朵朵
所以最后你觉得哪种方式会更方便呢?
这里如果我们使用 ofNullable 一个方法就可以搞定了,不用手动去判断具体看场景但是推荐使用 ofNullable
# 4.2.2 安全消费值
我们获取到一个 Optional 对象后肯定需要对其中的数据进行使用。这时候我们可以使用其 ifPresent 方法对来消费其中的值。
这个方法会判断其内封装的数据是否为空,不为空时才会执行具体的消费代码。这样使用起来就更加安全了。
例如,以下写法就优雅的避免了空指针异常。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor()); | |
authorOptional.ifPresent(author -> System.out.println(author.getName())); |
# 4.2.3 获取值
如果我们想获取值自己进行处理可以使用 get 方法获取,但是不推荐,因为当 Optional 内部的数据为空的时候会出现异常。
public static void main(String[] args) | |
{ | |
Author author = getAuthor(); | |
Optional<Author> authorOptional = Optional.ofNullable(author); | |
authorOptional.get(); | |
} | |
public static Author getAuthor() | |
{ | |
Author author = new Author(1L, "朵朵", 33, "未知生物", null); | |
return null; // author ;// --> null; | |
} |
打印结果:
Exception in thread "main" java.util.NoSuchElementException: No value present
at java.util.Optional.get(Optional.java:135)
at com.dkx.StreamDemo01.main(StreamDemo01.java:11)
我们可以进行下面的 4.2.4 中介绍的来安全获取值
# 4.2.4 安全获取值
如果我们期望安全的获取值。我们不推荐使用 get 方法,而是使用 Optional 提供的以下方法。
orElaseGet
获取数据并且设置数据为空时的默认值。如果数据不为空就能获取到该数据。如果为空则根据你传入的参数来创建对象作为默认返回。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());
Author author1 = authorOptional.orElseGet(() -> new Author());
代码演示:
public static void main(String[] args)
{Author author = getAuthor();
Optional<Author> authorOptional = Optional.ofNullable(author);
Author author1 = authorOptional.orElseGet(() -> new Author(2L, "朵朵1", 44, "未知生物1", null));
System.out.println(author1.getName());
}public static Author getAuthor()
{Author author = new Author(1L, "朵朵", 33, "未知生物", null);
return null; // author ;// --> null;
}打印结果:
朵朵1orElseThrow
获取数据,如果数据不为空就能获取到该数据。如果为空则根据你传入的参数来创建异常抛出。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor());
try{Author author = authorOptional.orElseThrow((Supplier<Throwalbe> () -> new
RuntimeException("author为空"));
System.out.println(author.getName());
} catch(Throwable throwable)
{throwable.printStackTrace();
}代码演示:
public static void main(String[] args)
{Author author = getAuthor();
Optional<Author> authorOptional = Optional.ofNullable(author);
Author author1 = authorOptional.orElseThrow(() -> new RuntimeException("author为空"));
System.out.println(author1.getName());
}public static Author getAuthor()
{Author author = new Author(1L, "朵朵", 33, "未知生物", null);
return null; // author ;// --> null;
}打印结果:
Exception in thread "main" java.lang.RuntimeException: author为空 at com.dkx.StreamDemo01.lambda$main$0(StreamDemo01.java:11) at java.util.Optional.orElseThrow(Optional.java:290) at com.dkx.StreamDemo01.main(StreamDemo01.java:11)
# 4.2.5 过滤
我们可以使用 filter 方法对数据进行过滤。如果原本是有数据的,但是不符合判断,也会变成一个无数据的 Optional 对象。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor()); | |
// 判断年龄不为空并且大于 100 的 | |
authorOptional.filter(author -> author.getAge() > 100).ifPresent(author -> System.out.println(author.getName())); |
# 4.2.6 判断
我们可以使用 isPresent 方法进行是否存在数据的判断。如果为空返回值为 false,如果不为空,返回值为 true。但是这种方式并不能体现 Optional 的好处,更推荐使用 ifPresent 方法。
Optional<Author> authorOptional = Optional.ofNullable(getAuthor()); | |
if(authorOptional.isPresent()) | |
{ | |
System.out.println(authorOptional.get().getName()); | |
} |
# 4.2.7 数据转换
Optional 还提供了 map 可以让我们对数据进行转换,并且转换得到的数据也还是被 Optional 包装好的,保证了我们的使用安全。
例如我们想获取作家的书籍集合
Optional<Author> authorOptional = Optional.ofNullable(getAuthor()); | |
Optoinal<List<Book>> books = authorOptional.map(author -> author.getBooks()); | |
books.ifPresent(new Consumer<List<Book>>() | |
{ | |
@Override | |
public void accept(List<Book> books) | |
{ | |
books.forEach(book -> System.out.println(book.getName())); | |
} | |
}); |
# 五、函数式接口
# 5.1 概述
只有一个抽象方法的接口我们称之为函数式接口。
JDK 的函数式接口都加上了 @FunctionalInterface 注解进行标识。但是无论是否加上该注解只要接口中只有一个抽象方法,都是函数式接口。
# 5.2 常见函数式接口
Consumer 消费接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中传入的参数进行消费
![image-20240503180324703]()
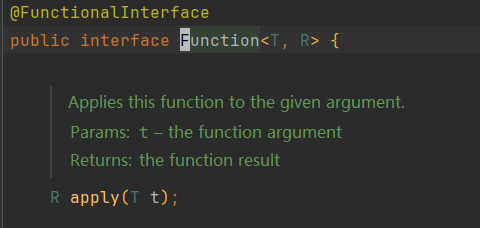
Funcion 计算转换接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中对传入的参数计算或转换,把结果返回
![image-20240503180417372]()
Predicate 判断接口
根据其中的抽象方法的参数列表和返回值类型知道,我们可以在方法中对传入的参数条件判断,返回判断结果
![image-20240503180534953]()
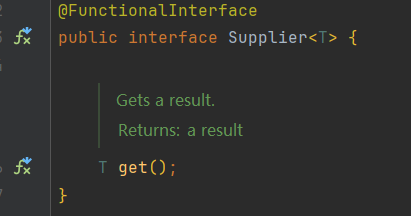
Supplier 生产接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中创建对象,把创建好的对象返回
![image-20240503180851242]()


# 5.3 常用的默认方法
and
我们在使用 Prediccate 接口时候可能需要进行判断条件的拼接。而 and 方法相当于是使用 && 来拼接两个条件
例如:
打印作家中年龄大于 17 并且姓名的长度大于 1 的作家。
List<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
stream.filter(new Predicate<Author>()
{@Overridepublic boolean test(Author author)
{return author.getAge() > 17;
}}.and(new Predicate<Author>()
{@Overridepublic boolean test(Author author)
{return author.getName().length() > 1;
}})).forEach(author -> System.out.println(author));
转换为 lambda 表达式:
List<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
stream.filter(((Predicate<Author>) author -> author.getAge() > 17)
.and(author -> author.getName().length() > 1))
.forEach(author -> System.out.println(author));
前面不加 (Predicate<Author>) 就会报错
![image-20240503182848199]()
这样写我们必须在前面写上 (Predicate<Author>),如果不想加我们可以使用 && 来进行判断
List<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
stream.filter(author -> author.getAge() > 17 && author.getName().length() > 1)
.forEach(author -> System.out.println(author));
or
我们在使用 Predicate 接口时候可能需要进行判断条件的拼接。而 or 方法相当于是使用 || 来拼接两个判断条件。
例如:
打印作家中年龄大于 17 或者姓名的长度小于 2 的作家。
List<Author> authors = getAuthors();
authors.stream()
.filter(new Predicate<Author>()
{@Overridepublic boolean test(Author author)
{return author.getAge() > 17;
}}.or(new Predicate<Author>()
{@Overridepublic boolean test(Author author)
{return author.getName().length() < 2;
}})).forEach(System.out::println);
转换为 lambda 表达式:
List<Author> authors = getAuthors();
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 17)
.or(author -> author.getName().length() < 2))
.forEach(System.out::println);
使用 || 来判断
List<Author> authors = getAuthors();
authors.stream()
.filter(author -> author.getAge() > 17 || author.getName().length() < 2)
.forEach(System.out::println);
negate
Predicate 接口中的方法。negate 方法相当于是在判断添加前面加了个!表示取反
例如:
打印作家中年龄不大于 17 的作家
List<Author> authors = getAuthors();
authors.stream()
.filter(new Predicate<Author>()
{@Overridepublic boolean test(Author author)
{return author.getAge() > 17;
}}.negate())
.forEach(System.out::println);
转换为 lambda 格式:
List<Author> authors = getAuthors();
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 17).negate())
.forEach(System.out::println);
使用!来判断
List<Author> authors = getAuthors();
authors.stream()
.filter(author -> !(author.getAge() > 17))
.forEach(System.out::println);
# 六、方法引用
我们在使用 lambda 时,如果方法体中只有一个方法的调用的话 (包括构造方法),我们可以用方法引用进一步简化代码。
# 6.1 推荐用法
我们在使用 lambda 时不需要考虑什么时候用方法引用,哪种方法引用,方法引用是什么。我们只需要在写完 lambda 方法发现方法体只有一行代码,并且是方法的调用时使用快捷键尝试是否是能够转换成方法引用即可。
当我们方法引用使用的多了慢慢的也可以直接写出方法引用。
# 6.2 基本格式
类名或者对象名::方法名
# 6.3 语法详解 (了解)
# 6.3.1 引用静态方法
其实就是引用类的静态方法
# 格式
类名::方法名
# 使用前提
如果我们在重写方法的时候,方法体中只有一行代码,并且这行代码是调用了某个方法的静态方法,并且我们把要重写的抽象方法中所有的参数都按照顺序传入了这个静态方法中,这个时候我们就可以引用类的静态方法。
例如:
如下代码就可以用方法引用进行简化
List<Author> authors = getAuthors(); | |
Stream<Author> authorStream = authors.stream(); | |
authorStream.map(author -> author.getAge()) | |
.map(age -> String.valueOf(age)); |
注意,如果我们所重写的方法都是没有参数的,调用的方法也是没有参数的也相当于符合以上规则。
优化后代码如下:
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getAge()) | |
.map(String::valueOf); |
# 6.3.2 引用对象的实例方法
# 格式
对象名::方法名
# 使用前提
如果我们在重写方法的时候,方法体中只有一行代码,并且这行代码是 调用了某个对象的成员方法,并且我们把要重写的抽象方法中所有的参数都按照顺序传入了这个成员方法中,这个时候我们就可以引用对象的实例方法。
例如:
List<Author> authors = getAuthros(); | |
Stream<Author> authorStream = authors.stream(); | |
StringBuilder sb = new StringBuilder(); | |
authorStream.map(author -> author.getName()) | |
.forEach(name -> sb.append(name)); |
优化后:
List<Author> authors = getAuthors(); | |
Stream<Author> stream = authors.stream(); | |
StringBuilder sb = new StringBuilder(); | |
stream.map(author -> author.getName()) | |
.forEach(sb::append); |
# 6.3.4 引用类的实例方法
# 格式
类名::方法名
# 使用前提
如果我们在重写方法的时候,方法体中只有一行代码,并且这行代码是调用了第一个参数的成员方法,并且我们把要重写的抽象方法中剩余的所有的参数都按照顺序传入了这个成员方法中,这个时候我们就可以引用类的实例方法。
package com.dkx; | |
import java.util.List; | |
import static com.dkx.StreamDemo.getAuthors; | |
public class StreamDemo02 | |
{ | |
interface UserString | |
{ | |
String use(String str, int start, int length); | |
} | |
public static String subAuthorName(String str, UserString useString) | |
{ | |
int start = 0; | |
int length = 1; | |
return useString.use(str, start, length); | |
} | |
public static void main(String... args) | |
{ | |
List<Author> authors = getAuthors(); | |
subAuthorName("三更草堂", new UserString() | |
{ | |
@Override | |
public String use(String str, int start, int length) | |
{ | |
return str.substring(start, length); | |
} | |
}); | |
} | |
} |
优化后代码如下:
public static void main(String... args) | |
{ | |
List<Author> authors = getAuthors(); | |
subAuthorName("三更草堂", String::substring); | |
} |
# 6.3.5 构造器引用
如果方法体中的一行代码是构造器的话就可以使用构造器引用。
# 格式
类名::new
# 使用前提
如果我们在重写方法的时候,方法体中只有一行代码,并且这行代码是调用了某个类的构造方法,并且我们把要重写的抽象方法中的所有的参数都按照顺序传入了这个构造方法中,这个时候我们就可以引引用构造器。
例如:
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getName()) | |
.map(name->new StringBui1der(name)) | |
.map(sb->sb.append("-三更").tostring()) | |
.forEach(str-> System.out.println(str)); |
代码优化后如下:
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getName()) | |
.map(StringBuilder::new) | |
.map(sb -> sb.append("三更").toString()) | |
.forEach(str -> System.out.println(str)); |
# 七、高级用法
# 基本数据类型优化
我们之前用到的很多 Stream 的方法由于都使用了泛型。所以涉及到的参数和返回值都是引用数据类型。
即使我们操作的是整数小数,但是实际用的都是它们的包装类。JDK5 中引入的自动装箱拆箱让我们在使用对应的包装类时就好像使用基本数据类型一样方便。但是你一定要知道装箱和拆箱肯定是要消耗时间的。虽然这个时间消耗很小。但是在大量的数据不断的重复装箱拆箱的时候,你就不能无视这个时间损耗了。
所以为了让我们能够对这部分的时间消耗进行优化。stream 还提供了很多专门针对基本数据类型的方法。
例如:mapToInt,mapToLong,mapToDouble,floatMapToInt,floatMapToDouble 等。
private static void test27() | |
{ | |
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getAge()) | |
.map(age -> age + 10) | |
.filter(age -> age > 18) | |
.map(age -> age + 2) | |
.forEach(System.out::println); | |
} |
在 age + 10 的代码流程中 这个 age 是 Integer 类型的会进行 自动拆箱 为 int 类型进行 + 10 计算 然后再进行 装箱,这里会消耗很多时间
... | |
.map(new Function<Integer, Integer>() | |
{ | |
@Override | |
public Integer apply(Integer age) | |
{ | |
return age + 10; | |
} | |
}) |
使用 mapToInt 如下
private static void test27() | |
{ | |
List<Author> authors = getAuthors(); | |
authors.stream() | |
.map(author -> author.getAge()) | |
.mapToInt(new ToIntFunction<Integer>() | |
{ | |
@Override | |
public int applyAsInt(Integer age) | |
{ | |
return age + 10; | |
} | |
}) | |
.filter(age -> age > 18) | |
.map(age -> age + 2) | |
.forEach(System.out::println); | |
} |
# 并行流
当流中有大量元素时,我们可以使用并行流去提高操作的效率。其实并行流就是把任务分配给多个线程去完成。如果我们自己去用代码实现的话其实会非常的复杂,并且要求你对并发编程有足够的理解和认知。而如果我们使用 Stream 的话,我们只需要修改一个方法的调用就可以使用并行流来帮我们实现,从而提高效率。
下面是使用 parallel 转换为 并行流的执行结果
// 假设数据量很大 串行流 处理很慢 | |
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7); | |
Integer sum = stream | |
.parallel() // 转换为 并行流 多个线程 进行操作 | |
.peek(p -> System.out.println(p + " - " + Thread.currentThread().getName())) //stream api 中专门用于 调式的方法 相对于 forEach 它是中间操作不会终结后面的调用 打印流中的元素 | |
.filter(num -> num > 5) | |
.reduce((result, ele) -> result + ele) | |
.get(); | |
System.out.println("最终结果: " + sum); |
结果:
1 - ForkJoinPool.commonPool-worker-3
6 - ForkJoinPool.commonPool-worker-4
3 - ForkJoinPool.commonPool-worker-5
4 - ForkJoinPool.commonPool-worker-6
7 - ForkJoinPool.commonPool-worker-2
2 - ForkJoinPool.commonPool-worker-1
5 - main
最终结果: 13
不使用 parallel 转换的结果
// 假设数据量很大 串行流 处理很慢 | |
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7); | |
Integer sum = stream | |
.peek(p -> System.out.println(p + " - " + Thread.currentThread().getName())) //stream api 中专门用于 调式的方法 相对于 forEach 它是中间操作不会终结后面的调用 打印流中的元素 | |
.filter(num -> num > 5) | |
.reduce((result, ele) -> result + ele) | |
.get(); | |
System.out.println(sum); |
结果:
1 - main | |
2 - main | |
3 - main | |
4 - main | |
5 - main | |
6 - main | |
7 - main | |
13 |