# Java 爬取某网站所有图片案例
使用 maven 工程
引入依赖
<dependency> | |
<groupId>org.jsoup</groupId> | |
<artifactId>jsoup</artifactId> | |
<version>1.13.1</version> | |
</dependency> |
任务:
- 找到目标网址
- 通过浏览器控制台查看包含了图片的 html 元素标签
- 通过 java 代码请求 url 并且通过 jsoup 库来解析 html 标签获取想要的信息
开始编码:
public class ImageCrawlers { | |
public static void main(String[] args) { | |
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA"; | |
try { | |
// 获取页面的 document 对象 | |
Document document = Jsoup.parse(new URL(url), 100000); | |
// 获取元素对象 | |
Element content = document.getElementById("js_content"); | |
System.out.println(content); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} |
打印结果:
由于获取的内容太多了,下面打印的信息是我截取过的,能看出来成功了就行
<div class="rich_media_content js_underline_content
" id="js_content" style="visibility: hidden;">
<p data-mpa-powered-by="yiban.io"><img class="rich_pages js_insertlocalimg" data-ratio="0.75" data-s="300,640" data-type="jpeg" data-w="960" data-src="https://mmbiz.qpic.cn/sz_mmbiz_jpg/DVk7VUQZ3qGeicxDibu7SlxIT62BJb593CqZhaC2FQbtcUracbaAicPXVrTZmaqlPC3gibYRSzcJ7licU3ibDVibjWBng/640?wx_fmt=jpeg" style="text-align: center;"></p>
<section>
<section powered-by="xiumi.us">
<section>
<p style="text-align: center;"><img class="rich_pages js_insertlocalimg" data-ratio="0.5625" data-s="300,640" data-src="https://mmbiz.qpic.cn/sz_mmbiz_jpg/FJtasAibLFa6MScppd3RCMHwXCXbfduXo8cVtNz1WTPLCLz99V025BczdC8UBfzrmybo4j8RiarV15Fzq3KxBbyw/640?wx_fmt=jpeg" data-type="jpeg" data-w="1280" style=""></p>
<section data-mpa-template="t" mpa-from-tpl="t">
<section style="white-space: normal;box-sizing: border-box;font-size: 16px;" mpa-from-tpl="t">
<section powered-by="xiumi.us" style="margin-top: 0.5em;margin-bottom: 0.5em;box-sizing: border-box;" mpa-from-tpl="t">
<section style="border-top: 1px dashed rgb(37, 180, 170);box-sizing: border-box;line-height: 0;" mpa-from-tpl="t">
<section style="line-height: 0;width: 0px;" mpa-from-tpl="t">
<svg viewbox="0 0 1 1" style="vertical-align:top;" mpa-from-tpl="t"></svg>
</section>
</section>
<p style="white-space: normal;text-align: center;"><img class="rich_pages" data-ratio="0.275" data-s="300,640" data-type="jpeg" data-w="1280" data-src="https://mmbiz.qpic.cn/sz_mmbiz_jpg/FJtasAibLFa6jZOQXB4rNue2qGicGC67SUw4NAJ0Hv99GsCPgXY0sbrhibvApAKDJzib18TicD1Hia0S1716qRqHGuiaQ/640?wx_fmt=jpeg" style="width: 677px !important;height: auto !important;visibility: visible !important;"></p>
</section>
</section>
</section>
</section>
</section>
</div>
下一步我们继续编码,获取 content 对象里面所有的 img 标签
public class ImageCrawlers { | |
public static void main(String[] args) { | |
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA"; | |
try { | |
// 获取页面的 document 对象 | |
Document document = Jsoup.parse(new URL(url), 100000); | |
// 获取元素对象 | |
Element content = document.getElementById("js_content"); | |
// 通过上面的对象获取里面所有的 img 标签内容 | |
Elements imgs = content.getElementsByTag("img"); | |
System.out.println(imgs); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} |
打印结果:
图片太多了,下面打印是我截取过的数据
<img class="rich_pages js_insertlocalimg" data-ratio="0.75" data-s="300,640" data-type="jpeg" data-w="960" data-src="https://mmbiz.qpic.cn/sz_mmbiz_jpg/DVk7VUQZ3qGeicxDibu7SlxIT62BJb593CqZhaC2FQbtcUracbaAicPXVrTZmaqlPC3gibYRSzcJ7licU3ibDVibjWBng/640?wx_fmt=jpeg" style="text-align: center;">
<img class="rich_pages js_insertlocalimg" data-ratio="0.75" data-s="300,640" data-type="jpeg" data-w="960" data-src="https://mmbiz.qpic.cn/sz_mmbiz_jpg/DVk7VUQZ3qGeicxDibu7SlxIT62BJb593C28QsQKN9ib198mFLvyG6vhpMrdiaUAeDRlTWQ3othPaZA2TMKDaFQqiaQ/640?wx_fmt=jpeg" style="">
继续编码获取 data-src 属性里面的路径
public class ImageCrawlers { | |
public static void main(String[] args) { | |
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA"; | |
try { | |
// 获取页面的 document 对象 | |
Document document = Jsoup.parse(new URL(url), 100000); | |
// 获取元素对象 | |
Element content = document.getElementById("js_content"); | |
// 通过上面的对象获取里面所有的 img 标签内容 | |
Elements imgs = content.getElementsByTag("img"); | |
// 通过 stream 流遍历 里面对象调用 attr 获取 data-src 属性的值 并打印输出 | |
imgs.stream().forEach(element -> System.out.println(element.attr("data-src"))); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} |
打印结果:
是很多的图片路径
https://mmbiz.qpic.cn/sz_mmbiz_jpg/DVk7VUQZ3qGeicxDibu7SlxIT62BJb593COl353kWkzxwAckMU531UJ33KXD3YFYXYiaAnXo7M2cF22wZGG6Gib5sg/640?wx_fmt=jpeg
https://mmbiz.qpic.cn/sz_mmbiz_jpg/DVk7VUQZ3qGeicxDibu7SlxIT62BJb593CsoRbMW21hdjAjT9EpkU9XO6Uv22LrCmauG76NPW6l2zKjC6XCQ5uQQ/640?
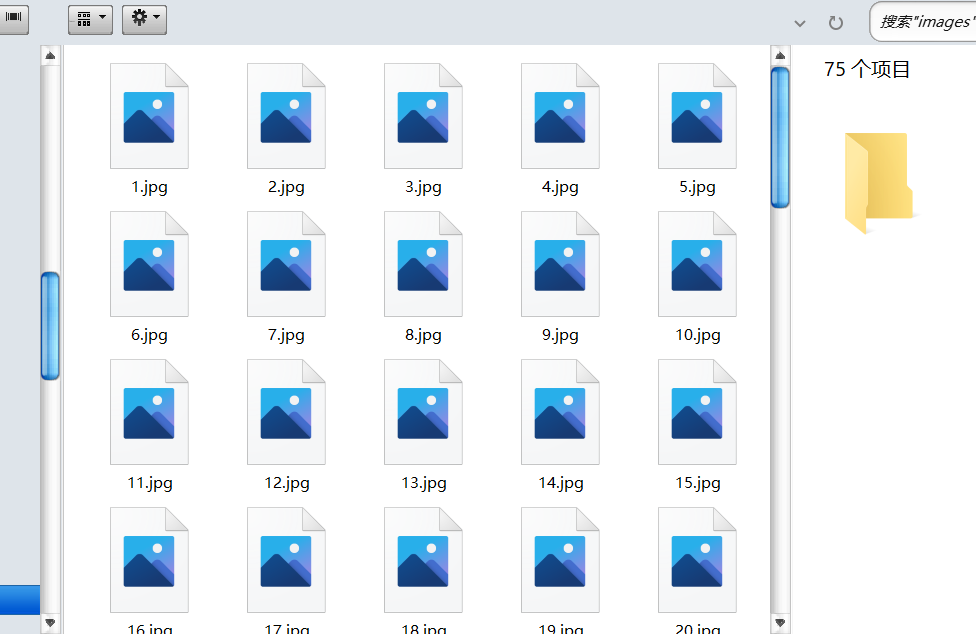
拿到了图片的路径我们就可以通过 URL 对象来进行 IO 操作了将所有图片下载到本地某个文件夹中,最终代码如下:
public class ImageCrawlers { | |
public static void main(String[] args) { | |
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA"; | |
try { | |
// 获取页面的 document 对象 | |
Document document = Jsoup.parse(new URL(url), 100000); | |
// 获取元素对象 | |
Element content = document.getElementById("js_content"); | |
// 通过上面的对象获取里面所有的 img 标签内容 | |
Elements imgs = content.getElementsByTag("img"); | |
// 通过 stream 流遍历 里面对象调用 attr 获取 data-src 属性的值 并打印输出 | |
AtomicInteger imgName = new AtomicInteger(); | |
imgs.stream().forEach(element -> { | |
String src = element.attr("data-src"); | |
FileOutputStream os = null; | |
InputStream is = null; | |
try { | |
URL target = new URL(src); | |
URLConnection urlConnection = target.openConnection(); | |
is = urlConnection.getInputStream(); | |
os = new FileOutputStream("E:\\images\\" + (imgName.incrementAndGet()) + ".jpg"); | |
byte[] bytes = new byte[1024]; | |
int i = 0; | |
while (((i = is.read(bytes)) != -1)) { | |
os.write(bytes, 0, i); | |
} | |
} catch (MalformedURLException e) { | |
throw new RuntimeException(e); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} finally { | |
try { | |
if (os != null) { | |
os.close(); | |
} | |
if (is != null) { | |
is.close(); | |
} | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
}); | |
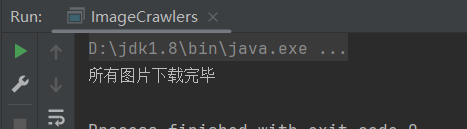
System.out.println("所有图片下载完毕"); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} |
效果: