# Base64
# Base64 介绍
疑惑:Base64 是什么,解决什么问题,Base64 字符串末尾的 = 是什么?
概述:
Base64 在日常开发中的出镜率还是比较高的,那你真的了解它吗?它是加密算法吗?它有什么作用?具体算法是怎么样的?为什么叫 Base64?
# Base64 是什么
Base64 是一种二进制到文本的编码方式。如果要具体一点的话,可以认为它是一种将 byte 数组编码为字符串的方法,而却编码出的字符串只包含 ASCII 基础字符。
例如字符串 ShuSheng007 对应的 Base64 为 U2h1U2hlbmcwMDc= 。其中那个 = 比较特殊,是填充符。
值得注意的是 Base64 不是加密算法,其仅仅是一种编码方式,算法也是公开的,所以不能依赖它进行加密。
# 为什么叫 Base64
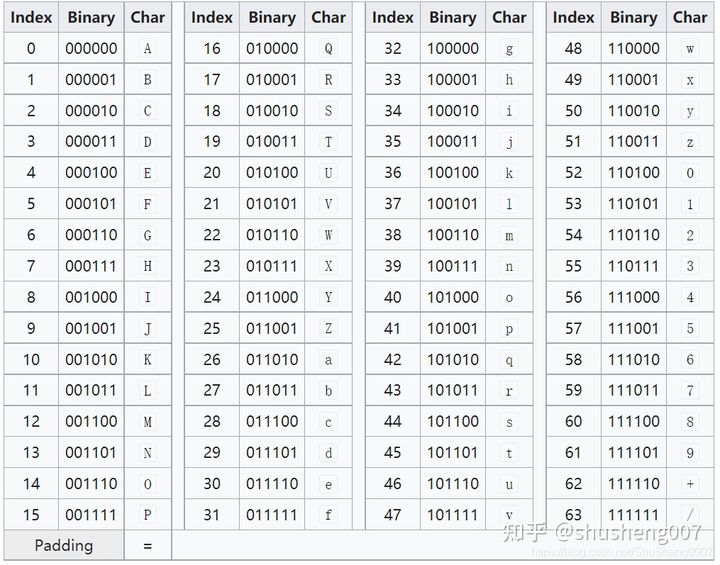
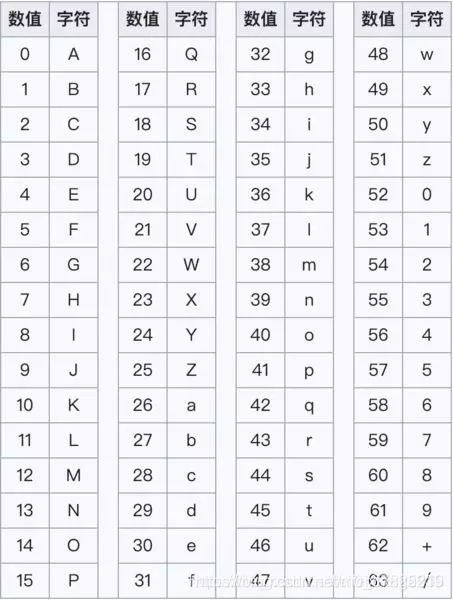
因为它是基于 (Base) 64 个字符的一种编码方式,使用其编码后的文本只包含 64 个 ASCII 码字符 (偶尔加一个填充符 = ),如下所示:
Base64 使用到的 64 个字符:
A-Z26 个a-z26 个0-910 个+1 个-1 个
下图是 Base64 码表,可以看到从 0 到 63 的每个数字都对应上面的一个字符。
# Base64 解决什么问题
这块还是比较难说清楚的,我们就抓住主要矛盾吧。
假设王二狗给牛翠花通过邮件发情书:
亲爱的牛翠花我爱你,就像老鼠爱大米... 你是我的心,你是我的肝,你是我生命中的四分之三...
我们首先要明白,网络中信息的传输只能传输 0 和 1 ,所以我们首先要将这封情书转成 01 序列,那怎么转呢?这就有涉及到了编码方式,这块展开说能说两天,这里就假设使用 utf-8 转成的 byte[] ,值 是我瞎写的 [100][11][1][13].... 这个 byte[] 里面的那些数字,传输时候是以二进制形式进行的,格式如下:
011001000001100100000001001101...
那么当牛翠花收到这串数字后再将其按照 utf-8 解码,就能看到王二狗的情书了。
如果一切都这么顺序就没 Base64 什么事了。由于信息从王二狗的电脑到牛翠花的电脑中间会经过好多路由器转发,牛翠花电脑上安装的邮件客户端也搞 幺蛾子。
其中一个叫 阿璐 的路由器发现现在使用的是文本传输协议,而且有个 byte 的值是 [13],而 13 在 ASCII 码中对应回车键,阿璐 一想,这玩意也表达不出个啥意思,算了给它省略了把,为下面的兄弟省点宽带,阿璐又看到一个 byte 值为 [07] 的又自作聪明,因为其在 ASCII 中表示铃声,又给省略了。这样等到 01 序列到达牛翠花的电脑时其实已经不是王二狗发出时的样子了,好死不死的牛翠花用的是 mac 电脑,邮件客户端也自作聪明,又给处理了好多 byte。最后导致的就是使用 utf-8 解码失败,或者解出来的内容不对。
如果是英文还好一点,因为被处理的都是那些 ASCII 中不可见的字符,那些话还是可以出来的,如果是张图片,牛翠花可能就打不开了。
所以,Base64 就是为了解决各系统以及传输协议中二进制不兼容的问题而生的。为啥使用 Base64 大家就兼容了呢?因为 Base64 满足了各方的需求,各方说了,俺们只保证支持 ASCII 中那些基础字符,其他的俺们不能保证,于是 Base64 就去从那些基础字符里挑了 64 个,所以大家都高兴了。
目前由于传输导致的二进制改变已经很少见了,各种系统对二进制的兼容性处理也越来越好。假如你告诉我这串 01 是一张 .jpg 格式的图片,那我就按照 .jpg 算法将其恢复成一张 .jpg 图片,所以大家都很高兴。
# ASCII 存在问题
地球人都知道计算机是欧美那帮人发明的,关键是这帮老外说的是英语,总共就 26 个字母。某一天一个老外在认真的设计 ASCII 码,他低头看了一眼手中的键盘,数了数按键,思考了一下,若有所思的加入了一些控制符,最后凑了 128 个字符 (后来进行了扩展),搞定收工,沃日,他把我们说汉语的直接忽略了... 因为人家看定是只想着自己的文字啊,它们可能在想:什么?中国人也有可能用电脑吗?他们有电脑吗?到时候说英语好啦,汉字就不要用了。
中国近 150 年来那叫一个矬 B 啊,落后愚昧,谁都能欺负。曾经的精英阶层(无论国共)均认为是中国的传统文化,以及汉语的复杂性导致了中国的全面衰落,大力提倡了汉字拉丁化,破四旧等等。足见咱们国家当年是多么的贫穷落后,把人的精神都逼成啥样了,准备放弃自己的文化了,但我们的祖国在近 20 年内迅速崛起了,虽然与西方仍然有较大的差距,但我们看到了光明的未来,这一点确实要感谢中国共产党。近年来文化也开始自信了,孔子学院也开到国外了,汉字也上了太空了,大部分妇女看到洋垃圾也不急着往回家捡了...
# 使用场景
- 证书
- 电子邮件的附件,因为附件往往有不可见字符
- xml 中如果想嵌入另一个 xml 文件,直接嵌入,往往 xml 标签就乱套了,不容易解析,因为,需要把 xml 编译成字节数组的字符串,编译成可见字符。
- 网页中的一些小图片,可以直接以 Base64 编码的方式嵌入,不用再链接请求消耗网络资源
- 较老的纯文本协议 SMTP,这些文本偶尔传输一个文件时,需要用 Base64
# Base64 算法
这里只做简单介绍,详细请参考相关技术文档
使用 Base64 进行编码,大致可以分为 4 步:
- 将原始数据每三个字符作为一组,每个字节是 8bit,所以一共是 24 个 bit
- 将 24 个 bit 分为四组,每组 6 个 bit
- 在每组前面补加
00,将其补全成四组 8 个 bit 到此步,原生数据的 3 个字节已经变成了 4 个字节了,增大了将近 30% - 根据 Base64 编码表得到扩展后每个字节的对应符号 (见下图)
下图是维基百科上面的一个例子:
假如我们的原文为 Man ,那么下图演示了如何按照上面的步骤将其编码为 Base64 字符串
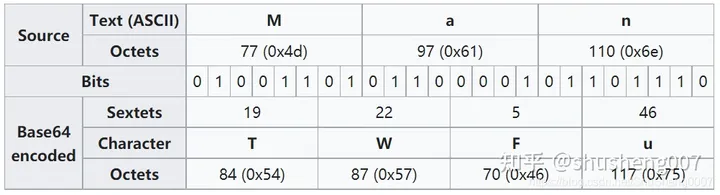
- Bits:是对应的 ASCII 里面的二进制数据
- Sextets:是当前二进制范围的值
- Character:对应如下 64 字符编码表的值
可以发现 Man 对应的 Base64 为 TWFu. 现在大家应该明白为什么只有 64 个字符了把?因为算法将 8bit 分割成 6bit 了,而 6bit 的取值范围为 0 ~ 63
# Base64 字符串末尾的 = 是什么
有时我们会在 Base64 字符末尾看到 = ,有时 1 个,有时 2 个,这时为啥?
通过上面的讲述,我们知道了 Base64 编码过程是 3 个字符一组的进行,如果原文长度不是 3 的倍数怎么办呢?例如我们的原文为 Man ,他不够 3 个,那么只能在编码后的字符串中补 = 了。缺一个字符补一个,缺两个补两个即可,所以有时你会看到 Base64 字符串结尾有 1 个或者 2 个 = 。
# Base64 DataURI 格式
有时你会发现 web 页面传给你的 Base64 字符串前面有类似下面的东西。
data:image/jpeg;base64, /9j/4AA |
这是 DataURI,大部分浏览器支持直接打开这类二进制数据,但是我们要格外注意,如果你只是想要真实的 Base64 内容就只需要取,后边的内容 /9j/4AA 。