# 码点,代码单元,lnegth,codePointCount
[TOC]
码点,代码单元,length (),codePointCount ()
下面是我在阅读 <<Java 核心技术卷 Ⅰ>> 中的两段代码
# length () 方法

Returns the length of this string. The length is equal to the number of Unicode code units in the string.
- 返回此字符串的长度,长度等于字符串中的 Unicode 代码单元数
# codePointCount () 方法
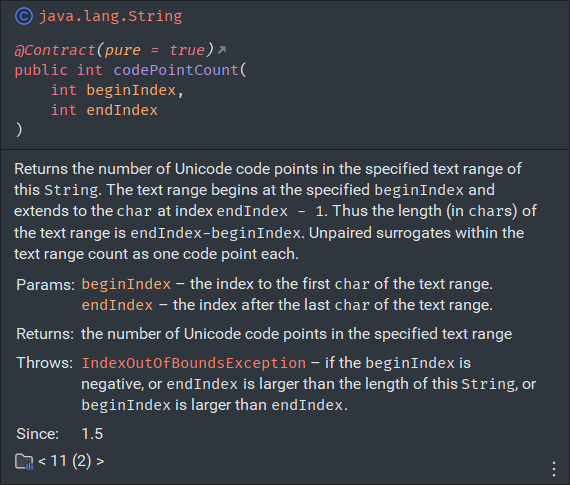
Returns the number of Unicode code points in the specified text range of this String.
- 返回此字符串指定文本范围内的 Unicode 码点数
# length () 方法和 codePointCount () 方法的区别
从返回值可以看出: length () 方法返回的是代码单元,codePointCount () 方法返回的是码点,而代码单元和码点究竟是什么呢?它们有什么区别呢?
| length() | codePointCount() |
|---|---|
| 返回此字符串的长度,长度等于字符串中的 Unicode 代码单元数 | 返回此字符串指定文本范围内的 Unicode 码点数 |
- 从下面这个例子的结果来看,码点和代码单元似乎没有区别
public class Test { | |
public static void main(String []args) { | |
String greeting = "Hello"; | |
int n = greeting.length(); | |
int cpCount = greeting.codePointCount(0, greeting.length()); | |
System.out.println(n); | |
System.out.println(cpCount); | |
} | |
} |
打印结果: 5
5
- 但是从这个例子就可以看出码点和代码单元的不同了,下面我们就来聊一下码点和代码单元
String greeting = "Hello"; | |
int n = greeting.length();//5 | |
int cpCount = greeting.codePointCount(0, greeting.length()); | |
System.out.println(n);//5 | |
System.out.println(cpCount);//5 | |
System.out.println("=-------------="); | |
String str = "😂"; | |
int r = str.length(); | |
System.out.println(r);//2 | |
int x = str.codePointCount(0,str.length()); | |
System.out.println(x);//1 |
打印结果: 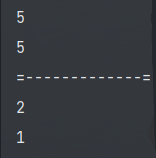
# 码点
码点就是你实际看到的每一个字符,比如:a,1,%,😂等都算一个码点
码点 (Code Point)
码点是指与一个编码表中的某个字符对应的值,在 Unicode 标准中,码点采用了十六进制书写,并加上前缀 U+, 例如 U+0041 就是拉丁字母 A 的码点,Unicode 的码点可以分成 17 个代码平面,第一个代码平面成为基本多语言平面,包括码点从 U+0000 到 U+FFFF 的经典 Unicode 代码,其余的 16 个平面的码点为从 U+10000 到 U+10FFFF, 包括辅助字符
---------- <<Java 核心技术卷 Ⅰ>>P33
# 代码单元
而代码单元就不一定是你实际看到的每一个字符,有可能你实际看到的字符是包含一个代码单元,也有可能包含两个代码单元,这是因为:
java 的字符串由 char 类型序列组成,而 char 类型原本是用来表示单个字符的,但是由于 Unicode 编码的机制,16 位的 char 类型已经无法满足描述所有的 Unicode 字符的需要了,那么有些 Unicode 字符就需要两个 char 值表示,则可对应上下文中的高亮字体: 一个代码单元时一个字符的编码
代码单元 (Code Unit)
UTF-16 编码采用不同长度的编码表示所有 Unicode 编码,在基本多语言平面中,每个字符用 1 位表示,称为代码单元,辅助字符编码为一对连续的代码单元,采用这种编码对表示的各个值落入基本多语言平面中未用的 2048 个值范围内,通常称为替代区域,这样设计十分巧妙,我们可以从中迅速知道一个代码单元时一个字符的编码,还是辅助字符的第一或第二部分
---------- <<Java 核心技术卷 Ⅰ>>P33
# 方法:
| 方法声明 | 功能介绍 |
|---|---|
| int offsetCodePoints(int index,int codePointoffset) | 返回此 String 中的索引,该索引从给定的 index 偏移 codePointoffset 码点,由 index 和 codePointoffset 给出的文本范围内的未配对代理计为每个代码点 |
| int codePointAt(int index) | 返回指定索引处的字符 (Unicode 代码点), 索引引用 char 值 (Unicode 代码单位), 范围从 0 到 lenth () - 1 |
| StringBuilder 方法 | |
| String appendCodePoint(int cp) | 追加一个码点,并将其转化为一个或者两个代码单元并返回 this |
String atest = "abcABC😀a"; | |
if("abcABC😀a".equals(atest)) { | |
int cp1 = atest.offsetByCodePoints(0,0); | |
int cp4 = atest.offsetByCodePoints(0, 3); | |
int cp5 = atest.offsetByCodePoints(0, 6); | |
int cp7 = atest.offsetByCodePoints(0, 7); | |
System.out.println("cp1 is "+cp1+" cp4 is "+ cp4+" cp5 is "+cp5+" cp7 is "+cp7); | |
int cp1unicode = atest.codePointAt(cp1); | |
int cp4unicode = atest.codePointAt(cp4); | |
int cp5unicode = atest.codePointAt(cp5); | |
int cp7unicode = atest.codePointAt(cp7); | |
System.out.println("a: "+cp1unicode+" A: "+cp4unicode+" 😀: "+cp5unicode+" a: "+cp7unicode); | |
} |
打印结果:
# offsetByCodePoints
public int offsetByCodePoints(int index,int codePointoffset)
这里的 index 就是你指定的任意第 i 个码点,假如你想知道距离第 i 个码点 x 个码点,(x 可正可负) 是相对于第 0 个码点第几个码点,则可以用 offsetByCodePoints (i,x) 得到的你想要的值,比方说
String astring = "abcdABCD"; | |
int cpcount = astring.offsetByCodePoints(7,-4)// 从 0 开始也就是 d | |
// 对应 ACSII 码值也就是 100 |
cpcount 的值应该是 3 (即表示 d 距离 a 3 个码点,也就是距离第 0 个位置 3 个位置)
# codePointAt
public int codePointAt(int index)
还是以上面那个例子,d 距离 a, 有 3 个位置,这个 3 通过 offsetByCodePoints () 得到,并且就可以看成是一个索引值,通过它你就能找到对应位置上是 d
String astring = "abcdABCD"; | |
int cpcount = astring.offsetByCodePoints(7,-4);// 从 0 开始也就是 d | |
// 对应 ACSII 码值也就是 100 | |
int dddunicode = astring.codePointAt(cpcount); | |
System.out.println(dddunicode); |
dddunicode = 100; 这其实是 ASCII 码值
# appendCodePoint
String appendCodePoint(int cp)
追加一个码点,并将其转化为一个或者两个代码单元并返回 this
String str = "hello"; | |
StringBuilder strbud = new StringBuilder(); | |
strbud.append(str); | |
System.out.println(strbud.appendCodePoint(97)); |
打印结果: