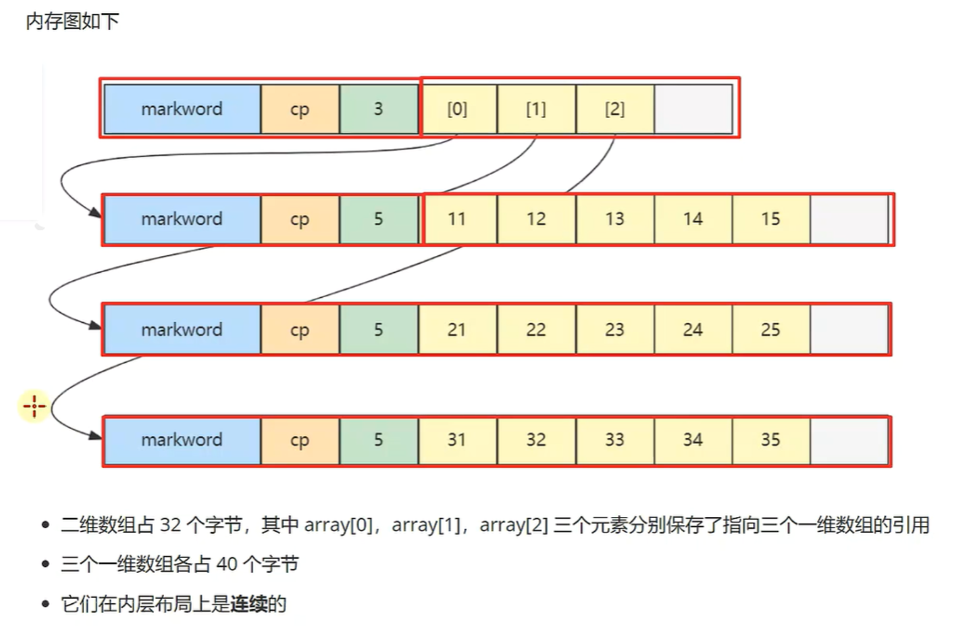
# 二维数组的局部性原理
int array[][] = { | |
{11, 12, 13, 14, 15}, | |
{21, 22, 23, 24, 25}, | |
{31, 32, 33, 34, 35} | |
}; |
# 局部性原理
这里只讨论空间局部性
- CPU 读取内存 (速度慢) 数据后,会将其放入高速缓存 (速度快) 当中,如果后来的计算再用到此数据,在缓存中能读到的话,就不必读内存了
- 缓存的最小存储单位是缓存行 (cacheline) ,一般是 64 bytes,一次读取的数据少了不划算,因此最少读 64 bytes 填满一个缓存行,因此读入某个数据时也会读取其邻近的数据,这就是所谓空间局部性
下面代码中 StopWatch 是 spring-core-5.2.3.RELEASE.jar 导入即可使用
public class TestCacheLine | |
{ | |
public static void ij(int a[][], int rows, int columns) | |
{ | |
long sum = 0L; | |
for (int i = 0; i < rows; i++) | |
{ | |
for (int j = 0; j < columns; j++) | |
{ | |
sum += a[i][j]; | |
} | |
} | |
System.out.println(sum); | |
} | |
public static void ji(int a[][], int rows, int columns) | |
{ | |
long sum = 0L; | |
for (int i = 0; i < columns; i++) | |
{ | |
for (int j = 0; j < rows; j++) | |
{ | |
sum += a[j][i]; | |
} | |
} | |
System.out.println(sum); | |
} | |
/* | |
CPU 缓存 内存 | |
皮秒 毫秒 | |
64 字节 | |
缓存行 cache line | |
空间局部性 | |
*/ | |
public static void main(String[] args) | |
{ | |
int rows = 1_000_000; | |
int columns = 14; | |
int a[][] = new int[rows][columns]; | |
StopWatch stopWatch = new StopWatch(); | |
stopWatch.start("ij"); | |
ij(a, rows, columns); | |
stopWatch.stop(); | |
stopWatch.start("ji"); | |
ji(a, rows, columns); | |
stopWatch.stop(); | |
System.out.println(stopWatch.prettyPrint()); | |
} | |
} |
打印结果:
0
0
StopWatch '': running time = 192431100 ns
---------------------------------------------
ns % Task name
---------------------------------------------
041449500 022% ij
150981600 078% ji
为什么两者之间有这么大的差异?
我们分析一下如下的代码:
public static void ij(int a[][], int rows, int columns) | |
{ | |
long sum = 0L; | |
for (int i = 0; i < rows; i++) | |
{ | |
for (int j = 0; j < columns; j++) | |
{ | |
sum += a[i][j]; | |
} | |
} | |
System.out.println(sum); | |
} |
当循环 a[0][0] 时,它除了读取 0,0 索引的元素外,还会将邻近的 (后续) 元素也顺便读取进来 (局部性原理) 凑读 64 个字节给它填满一个缓存行。所以不光读了 0,0 就连 0,1 到 0,13 也都读取进来了。
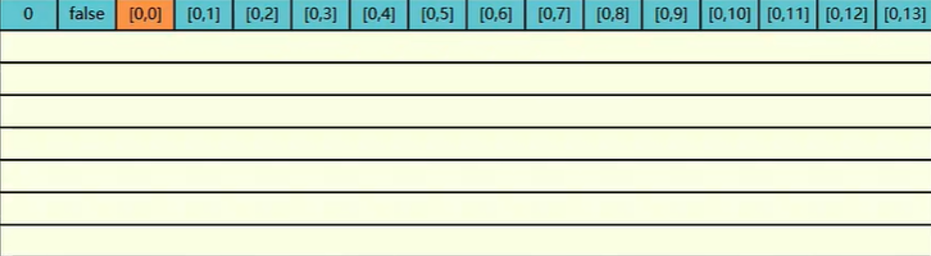
当读取 0,1 元素是也就是 a[0][1] 时,就不需要当内存中找了,因为已经缓存起来了所以直接找缓存就行了速度就比较快了
蓝色背景代表需要找内存,灰色背景代表不需要找内存直接找缓存,可以充分利用缓存来提高效率
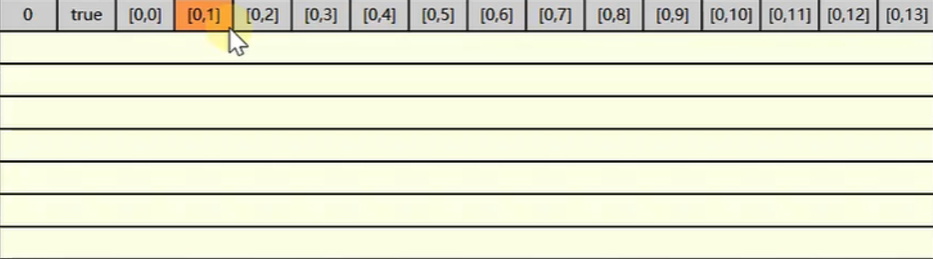
直到最后的 0,13,都直接找缓存中读取数据就可以了,速度很快
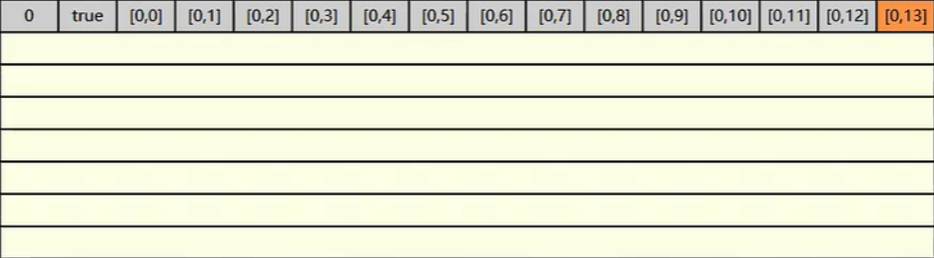
0~n 的这一轮就循环读取完毕了,该下一行了就是 1,0 了这时 缓存中是没有的就需要再到内存中读取了,同理读取一次后就会将邻近的元素都加载到缓存中去
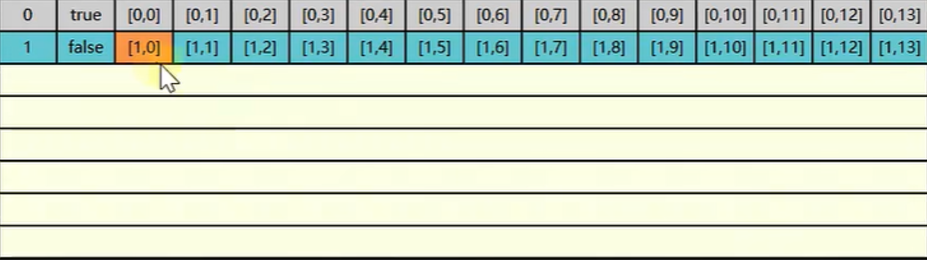
总结:
我们发现,外层循环数组行,内层循环数组列 就能充分利用提升读取效率
下面再分析速度比较慢的情况,就是外层循环数组列,内层循环数组行
public static void ji(int a[][], int rows, int columns) | |
{ | |
long sum = 0L; | |
for (int i = 0; i < columns; i++) | |
{ | |
for (int j = 0; j < rows; j++) | |
{ | |
sum += a[j][i]; | |
} | |
} | |
System.out.println(sum); | |
} |
第一次将 0,0 的元素和邻近的元素到 0,13 的所有元素都读取到缓存了
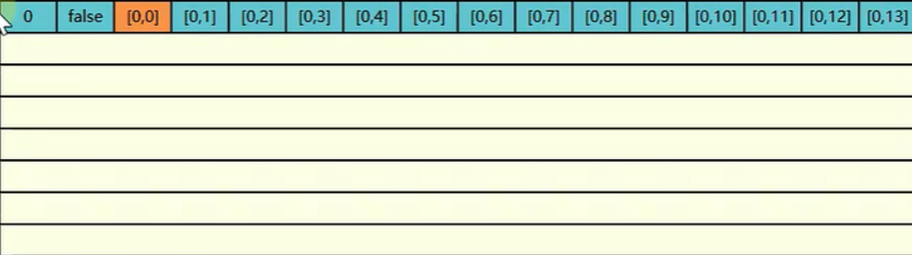
但是第二次读取的是 1,0 因为 i 不变 j 变 1 a[j][i] 也就是 a[1][0] 。这时缓存中并没有 1,0 又要去读取内存了
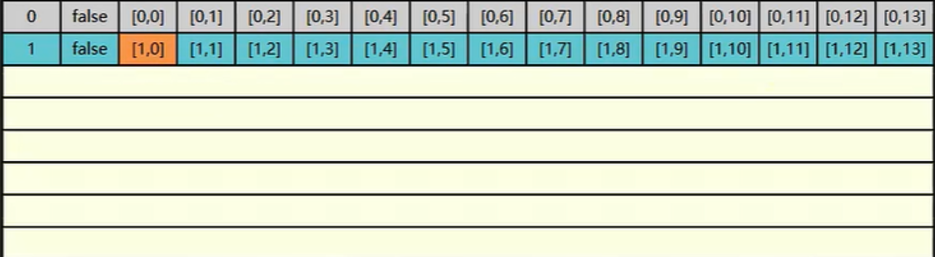
第三次读取 3,0。同样的缓存中没有需要找内存读取加载到缓存中。但是缓存是有限的,而缓存中的 0,1 1,1 2,1 都没有用上 ,数据没用上接下来超过了缓存的最大值后它就会把旧的数据被新的数据覆盖掉
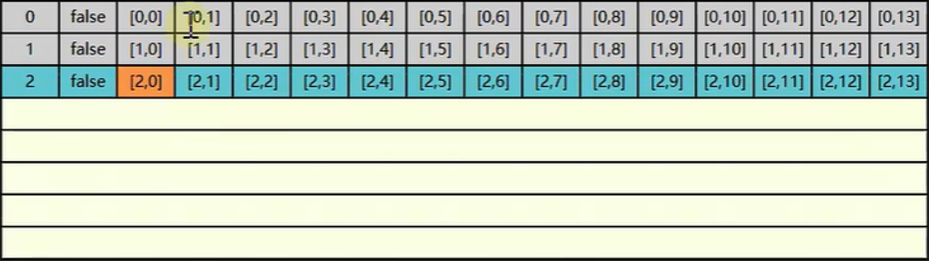
假设我们缓存最大值是 7 行数据,而我们需要遍历 10 行数据。此时超过缓存最大之后旧的数据就会被新的数据覆盖掉如下所示:
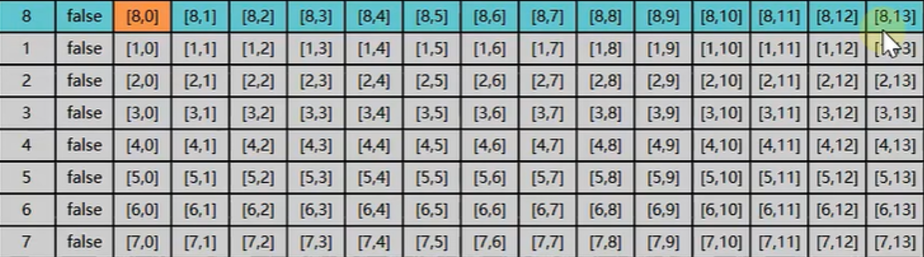
总结:
我们发现,外层循环数组列,内层循环数组行 会浪费掉每行缓存的数据 而 旧数据会被新数据覆盖因为缓存有限 这使得效率很低