# 请求🌗
编写 ServerSocket 来充当服务器
public class MyHttpServer { | |
public static void main(String...args){ | |
try{ | |
// 设置接收的端口号为:8080 | |
ServerSocket serverSocket = new ServerSocket(8080); | |
// 等待接收数据,程序执行此处就会阻塞等等接收数据 | |
Socket socket = serverSocket.accept(); | |
// 打印接收到的数据对象 | |
System.out.println(socket); | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
} |
通过浏览器访问 ServerSocket
http://localhost:8080 |
访问后控制台打印结果:
Socket[addr=/0:0:0:0:0:0:0:1,port=7104,localport=8080] |
通过 Socket 调用 getInputStream () 来获取输入流打印浏览器请求体的信息
public class MyHttpServer { | |
public static void main(String...args){ | |
try{ | |
ServerSocket serverSocket = new ServerSocket(8080); | |
while(true){ | |
Socket socket = serverSocket.accept(); | |
System.out.println(socket); | |
InputStream is = socket.getInputStream(); | |
OutputStream os = socket.getOutputStream(); | |
byte[] by = new byte[1024 * 1024]; | |
int len = is.read(by); | |
System.out.println("读取到的字节数是: "+len); | |
System.out.println(new String(by,0,len)); | |
} | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
} |
访问浏览器后,控制台的打印 请求头 信息:
Socket[addr=/0:0:0:0:0:0:0:1,port=7268,localport=8080] | |
读取到的字节数是: 810 | |
GET / HTTP/1.1 | |
Host: localhost:8080 | |
Connection: keep-alive | |
Cache-Control: max-age=0 | |
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24" | |
sec-ch-ua-mobile: ?0 | |
sec-ch-ua-platform: "Windows" | |
Upgrade-Insecure-Requests: 1 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 | |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 | |
Sec-Fetch-Site: none | |
Sec-Fetch-Mode: navigate | |
Sec-Fetch-User: ?1 | |
Sec-Fetch-Dest: document | |
Accept-Encoding: gzip, deflate, br | |
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 | |
Cookie: Idea-8296eb31=16c5dc07-6155-413d-b308-90f5c8fb55fe; JSESSIONID=F024A5B2C3183BCEFD841682047E6907 |
我们通过浏览器请求本地的 ServerSocket 浏览器就会一直等待响应,因为使用无限循环让服务器一直保持开启的状态
# 响应😋
使用 Java 中的 ServerSocket 通过 OutputStream 来实现将内容相应到浏览器的页面上。
- 创建 ServerSocket 服务器套接字,并使用 try {} catch (){} 捕获异常。
- 创建线程池 Executors.newCachedThreadPool,serverSocket 调用 accept (); 阻塞程序等待接收数据报,注意:不要写在子线程中 (
executorService.execute) 去执行它否则性能爆炸。 - 无限循环保持启动状态开启使用子线程 executorService.execute ,执行内部的操作。
- 创建 InputStream 和 OutputStream,is 读取请求 HTTP 时的请求体信息,定义缓冲区数组一次性读取多个。
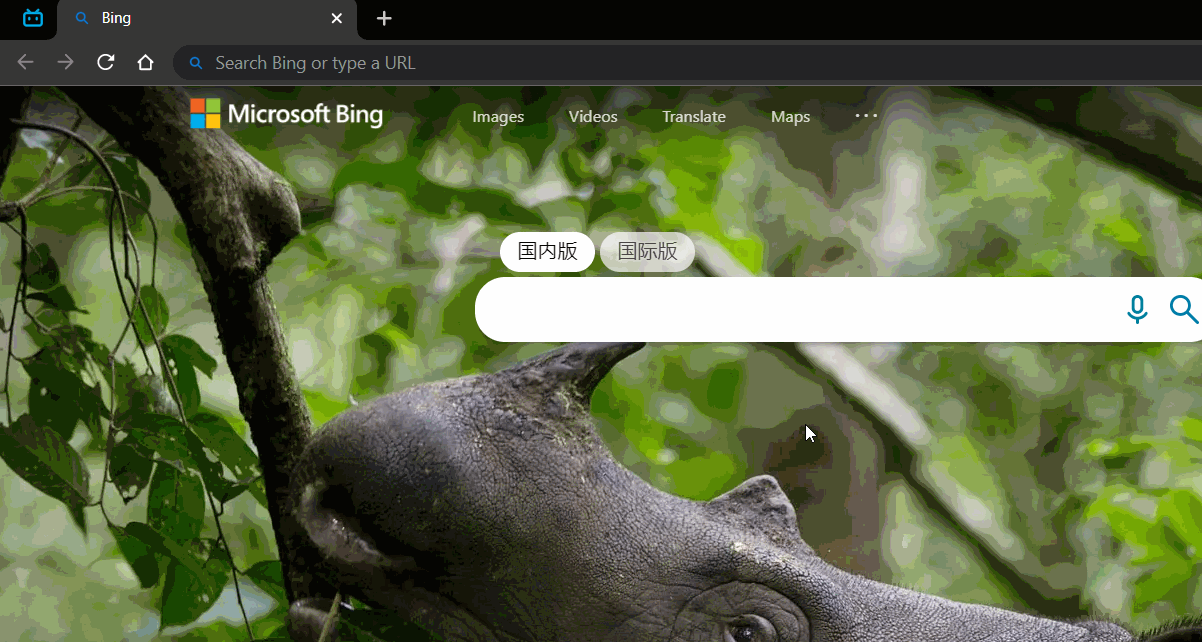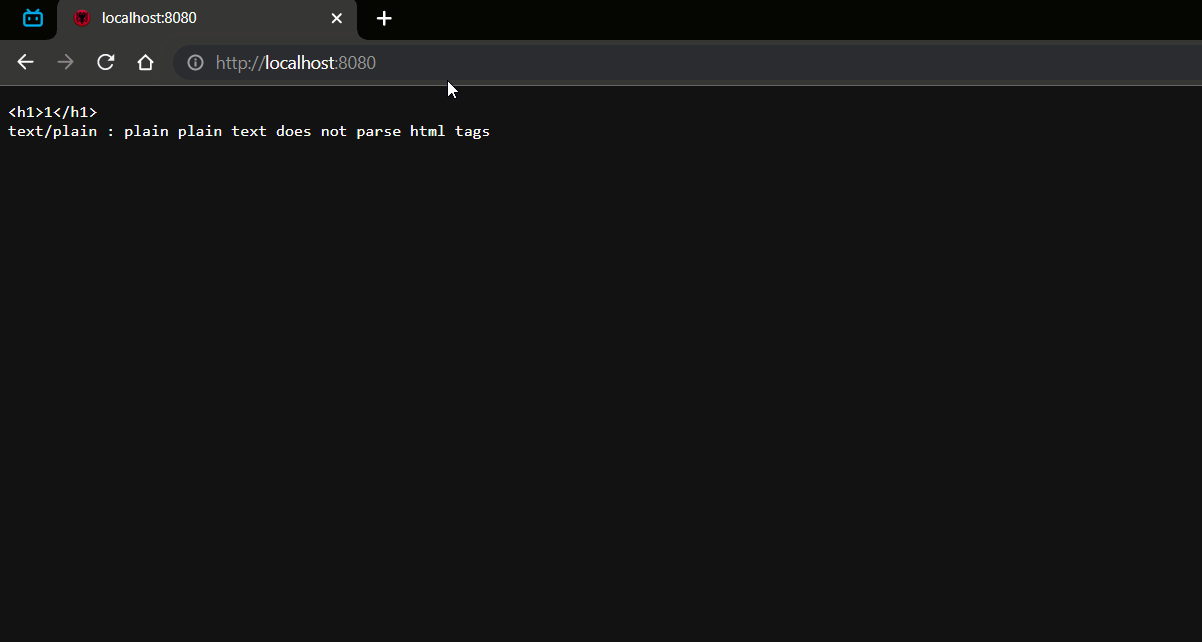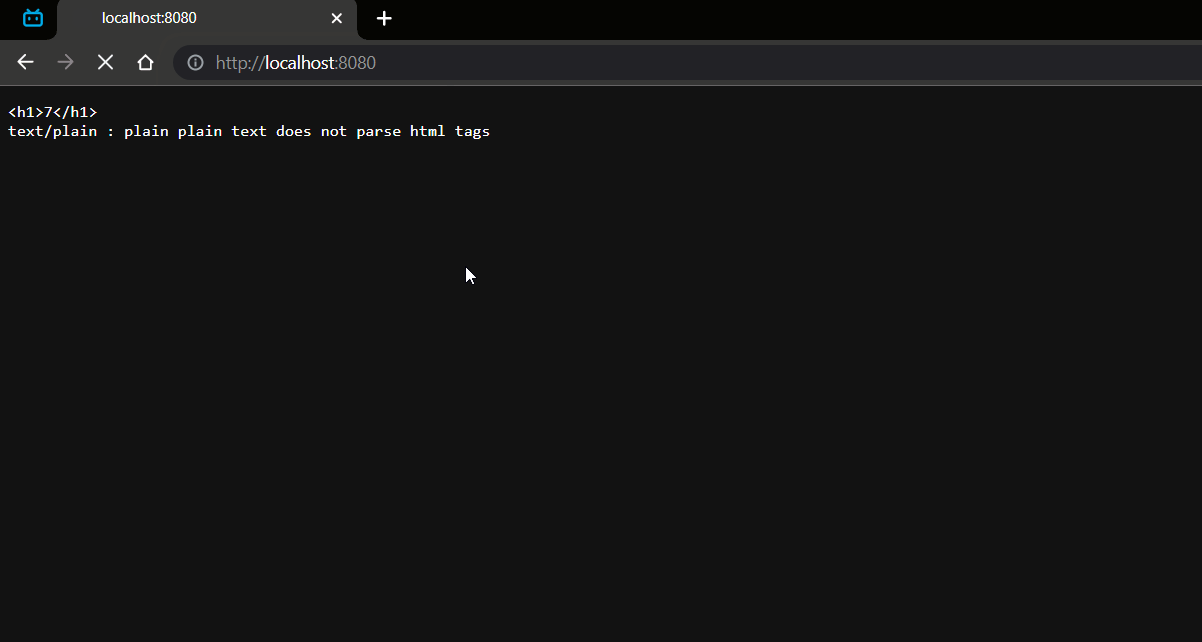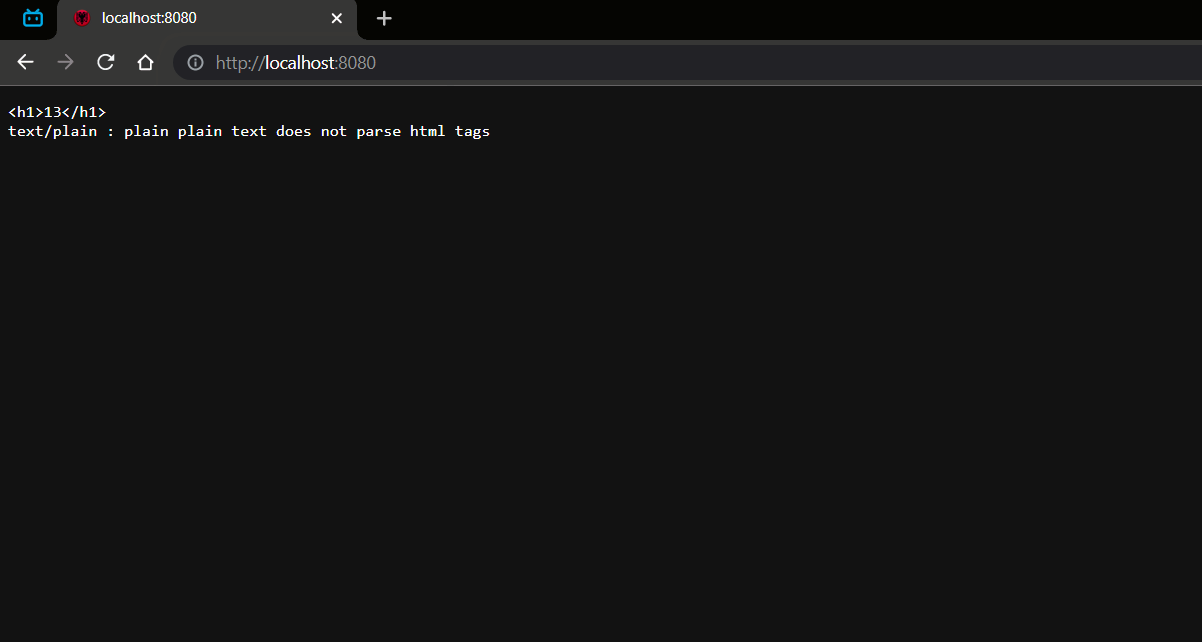
- 定义字符串赋值一个 h1 标签内容是成员字段自增值,在定义字符串赋值 HTTP 协议的请求信息和请求类型。
- 再定义 HTTP 协议的字符串中拼接上内容字符串 ("<h1>"+count+"<h1/>") ,在每段请求信息的后面都要使用 " 空格换行 " 进行分隔否则后面数据发送不到。
- 将 response 拼接好信息的字符串通过输出流 os.write () 写出到浏览器中。
- 所有操作都完毕后关闭流,释放资源否则不会写出数据到页面中。
public class MyHttpServer { | |
private static int count = 1; | |
public static void main(String... args) { | |
try { | |
ServerSocket serverSocket = new ServerSocket(8080); | |
System.out.println("服务器已经启动,监听端口为:8080 ..."); | |
ExecutorService executorService = Executors.newCachedThreadPool(); | |
while (true) { | |
Socket socket = serverSocket.accept(); | |
executorService.execute(() -> { | |
InputStream is = null; | |
OutputStream os = null; | |
try { | |
System.out.println(socket); | |
is = socket.getInputStream(); | |
os = socket.getOutputStream(); | |
byte[] by = new byte[1024 * 1024]; | |
int len = is.read(by); | |
if (len != -1) { | |
System.out.println("读取到的字节数是: " + len); | |
System.out.println(new String(by, 0, len)); | |
// 响应给浏览器需要使用 Http 协议 | |
String body = "<h1>" + count + "</h1>"; | |
//http 协议 / 版本 状态码 状态 后面的格式必须是 \r\n 不能乱写否则报错 | |
String response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本的内容大小 | |
"Content-Length: " + body.getBytes().length + "\r\n" + | |
// 告诉浏览器文本类型:普通文本 /plain 不解析 html 标签代码 | |
"Content-Type: text/plain; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n" +// 回车换行,否则后面的数据接收不到 | |
//body 响应浏览器内容 | |
// 要返回给浏览器的文本正文 (内容) | |
body + "\r\n";// 回车换行,否则后面的数据接收不到 | |
// 将上面的 HTTP 协议信息和响应的数据写出到浏览器中 | |
os.write(response.getBytes()); | |
count++; | |
} else { | |
System.out.println("没有读取到数据"); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
}finally{ | |
try{ | |
if(os != null){ | |
os.flush();// 将数据刷出 | |
} | |
if(socket != null){ | |
// 上一段对话已经结束进行下一段对话 | |
socket.shutdownOutput(); | |
socket.close();// 关闭套接字资源 | |
} | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
}); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
} | |
} | |
} |
效果:
# 请求信息十六进制显示⚡️
将 HTTP 请求头的信息转换为十六进制显示类似如下:

思路:
定义传入二进制数据转换为十六进制的方法.
传入一个二进制的数据到 byte2Hex 方法中进行地位和高位的计算转换为对应的十六进制数据,地位计算出一个值为 char 数组成员字段的下标值,高位也是组成一个十六进制的值
二进制转十六进制数 规则:
从低位开始,将二进制数每四位一组,转成对应的六进制数即可:
例子:
地位:进行 & 操作计算出地位要转换的数据
高位:先进行 & 操作计算出高位要转换的数据然后进行运算符右移让其从高位变地位来计算,如果不懂需要细读 二进制转十六进制的规则计算出结果后通过值来获取 char 数组成员字段下标对应十六进制的值
定义成员变量来记录十六进制的数据组
private static final char[] arr = {'0','1','2','3','4','5','6','7','8','9','A', | |
'B','C','D','E','F'}; |
定义方法将传入的二进制数据转换为十六进制
/** | |
* 3a -> "3A" | |
* a5 -> "A5" | |
* @param bt | |
* @return | |
*/ | |
private static String byte2Hex(byte bt){ | |
/** | |
* 00111111:形参 | |
* & | |
* 00001111 | |
* 操作: | |
* 00001111 | |
* 结果:15 对应成员变量下标结果: F | |
*/ | |
// 计算地位 | |
int lo = bt & 0b00001111; | |
/** | |
* 00111111:形参 | |
* & | |
* 11110000 | |
* 操作: | |
* 00110000 | |
* 结果: | |
* 48 | |
* >> 4 | |
* 结果: | |
* 24 12 6 3 | |
* 最终结果: | |
* 3 对应成员变量下标结果: 3 | |
*/ | |
// 计算高位 | |
// 运算右移 4 位是因为让高位变地位重新开始计算而不是继续计算 | |
int hi = (bt & 0b11110000) >> 4; | |
char clo = arr[lo]; | |
char chi = arr[hi]; | |
// 转换为字符串类型拼接返回 | |
return chi + "" + clo; | |
} |
测试代码:
//f:15 1111:15 11:3 -> 111111 48 56 60 63 最终实参为:63 | |
//byte 会将 0x3f 转换为二进制数据:63 传入形参中 | |
byte b = 0x3f; | |
String Hex = byte2Hex(b); | |
System.out.println(Hex); | |
----------------------------Result---------------------------- | |
3F |
上面的代码通过测试能返回一个二进制数转为十六进制数据对应的数据但是我们想要的不是只有一个。
# 将多个二进制转十六进制的数据拼接打印☢️
定义接收 byte 数组的方法 bytesArr2HexStr 将数组中二进制数据转换为多个十六进制显示:
思路:
接收一个二进制数组和数据的大小,循环数据大小,定义 StringBuffer 使用 append 追加每次循环传入 byte2Hex 转换方法中返回的十六进制数据并在每段数据后拼接空格,if 判断每 8 段数据多拼接一个空格,if 判断每 16 段数据空格换行,最终返回 sb.toString () 将 StringBuffer 转换为字符串类型返回。
/** | |
* 将传入的整个二进制数据全部转换为十六进制的数据 | |
* @param by 接收字节数组 | |
* @param len 数据的大小 | |
* @return | |
*/ | |
private static String bytesArr2HexStr(byte[] by,int len){ | |
// 使用 StringBuffer 来接收转换后的十六进制数据 | |
StringBuffer sb = new StringBuffer(); | |
for(int i = 0;i < len;i ++){ | |
// 每追加一个十六进制数据就拼接一个空格 | |
sb.append(byte2Hex(by[i])+" "); | |
// 判断每第 8 个多追加一个空格 i+1 避免第一个就满足条件 | |
if((i + 1) % 8 == 0) | |
sb.append(" "); | |
// 判断每 16 个进行换行空格 i+1 避免第一个就满足条件 | |
if((i + 1) % 16 == 0) | |
sb.append("\r\n"); | |
} | |
// 将 StringBuffer 转换为字符串并返回 | |
return sb.toString(); | |
} |
在 main 方法中:InputStream 中读取 请求体 的二进制数据并将二进制数据传入十六进制转换方法中进行转换:
// 从 Socket 中读取 HTTP 请求信息 | |
is = socket.getInputStream(); | |
os = socket.getOutputStream(); | |
// 字节缓冲区 | |
byte[] by = new byte[1024 * 1024]; | |
// 将读取到的字节数据赋值给变量 len | |
int len = is.read(by); | |
// 判断是否读取到末尾 | |
if (len != -1) { | |
// 调用方法进行转换为十六进制 | |
String hexMsg = bytesArr2HexStr(by,len); | |
System.out.println(hexMsg); | |
----------------------------Result---------------------------- | |
47 45 54 20 2F 66 61 76 69 63 6F 6E 2E 69 63 6F | |
20 48 54 54 50 2F 31 2E 31 0D 0A 48 6F 73 74 3A | |
20 6C 6F 63 61 6C 68 6F 73 74 3A 38 30 38 30 0D | |
0A 43 6F 6E 6E 65 63 74 69 6F 6E 3A 20 6B 65 65 | |
70 2D 61 6C 69 76 65 0D 0A 73 65 63 2D 63 68 2D | |
75 61 3A 20 22 47 6F 6F 67 6C 65 20 43 68 72 6F | |
6D 65 22 3B 76 3D 22 31 31 33 22 2C 20 22 43 68 | |
72 6F 6D 69 75 6D 22 3B 76 3D 22 31 31 33 22 2C | |
20 22 4E 6F 74 2D 41 2E 42 72 61 6E 64 22 3B 76 | |
3D 22 32 34 22 0D 0A 73 65 63 2D 63 68 2D 75 61 | |
2D 6D 6F 62 69 6C 65 3A 20 3F 30 0D 0A 55 73 65 | |
72 2D 41 67 65 6E 74 3A 20 4D 6F 7A 69 6C 6C 61 | |
2F 35 2E 30 20 28 57 69 6E 64 6F 77 73 20 4E 54 | |
20 31 30 2E 30 3B 20 57 69 6E 36 34 3B 20 78 36 | |
34 29 20 41 70 70 6C 65 57 65 62 4B 69 74 2F 35 | |
33 37 2E 33 36 20 28 4B 48 54 4D 4C 2C 20 6C 69 | |
6B 65 20 47 65 63 6B 6F 29 20 43 68 72 6F 6D 65 | |
2F 31 31 33 2E 30 2E 30 2E 30 20 53 61 66 61 72 | |
69 2F 35 33 37 2E 33 36 0D 0A 73 65 63 2D 63 68 | |
2D 75 61 2D 70 6C 61 74 66 6F 72 6D 3A 20 22 57 | |
69 6E 64 6F 77 73 22 0D 0A 41 63 63 65 70 74 3A | |
20 69 6D 61 67 65 2F 61 76 69 66 2C 69 6D 61 67 | |
65 2F 77 65 62 70 2C 69 6D 61 67 65 2F 61 70 6E | |
67 2C 69 6D 61 67 65 2F 73 76 67 2B 78 6D 6C 2C | |
69 6D 61 67 65 2F 2A 2C 2A 2F 2A 3B 71 3D 30 2E | |
38 0D 0A 53 65 63 2D 46 65 74 63 68 2D 53 69 74 | |
65 3A 20 73 61 6D 65 2D 6F 72 69 67 69 6E 0D 0A | |
53 65 63 2D 46 65 74 63 68 2D 4D 6F 64 65 3A 20 | |
6E 6F 2D 63 6F 72 73 0D 0A 53 65 63 2D 46 65 74 | |
63 68 2D 44 65 73 74 3A 20 69 6D 61 67 65 0D 0A | |
52 65 66 65 72 65 72 3A 20 68 74 74 70 3A 2F 2F | |
6C 6F 63 61 6C 68 6F 73 74 3A 38 30 38 30 2F 0D | |
0A 41 63 63 65 70 74 2D 45 6E 63 6F 64 69 6E 67 | |
3A 20 67 7A 69 70 2C 20 64 65 66 6C 61 74 65 2C | |
20 62 72 0D 0A 41 63 63 65 70 74 2D 4C 61 6E 67 | |
75 61 67 65 3A 20 65 6E 2D 55 53 2C 65 6E 3B 71 | |
3D 30 2E 39 2C 7A 68 2D 43 4E 3B 71 3D 30 2E 38 | |
2C 7A 68 3B 71 3D 30 2E 37 0D 0A 43 6F 6F 6B 69 | |
65 3A 20 49 64 65 61 2D 38 32 39 36 65 62 33 31 | |
3D 31 36 63 35 64 63 30 37 2D 36 31 35 35 2D 34 | |
31 33 64 2D 62 33 30 38 2D 39 30 66 35 63 38 66 | |
62 35 35 66 65 0D 0A 0D 0A | |
--------------------------------------------------------------------------- | |
GET /favicon.ico HTTP/1.1 | |
Host: localhost:8080 | |
Connection: keep-alive | |
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24" | |
sec-ch-ua-mobile: ?0 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 | |
sec-ch-ua-platform: "Windows" | |
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8 | |
Sec-Fetch-Site: same-origin | |
Sec-Fetch-Mode: no-cors | |
Sec-Fetch-Dest: image | |
Referer: http://localhost:8080/ | |
Accept-Encoding: gzip, deflate, br | |
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 | |
Cookie: Idea-8296eb31=16c5dc07-6155-413d-b308-90f5c8fb55fe |
# 请求头信息 ASCII 码显示🌓
编写判断十六进制可展示范围的字符
思路:
- 定义四个 StringBuffer:sb:主体,sbLeft:左边数据,sbRight:右边展示 ASCII 字符,fenge:展示 ... 。
- 循环字节数据大小,将循环到的字节数据传入到 byte2Hex 方法中进行十六进制转换并在每个数据后拼接空格然后追加到 sbLeft 中 。
- 判断当前循环的二进制字节数据的字符可见范围可对照 ASCII 码表查看满足条件则转换为字符追加到 sbRight 中,如果没有则追加
.进行分隔。 - 判断 i+1 从 1 开始 %8 是否等于 0,也就是每 8 位一组多追加一个空格进去。
- 判断 i+1 从 1 开始 %16 是否等于 0,也就是每 16 位将:分隔,sbLeft,分隔,sbRight,空格换行追加到主体 sb 中,并重新创建 sbLeft,sbRight,fenge 的 StringBuffer 清空之前的数据,因为之前的数据存入 sb 中了再存就重复了。
- 追后执行完了循环在进行一次所有 StringBuffer 向 sb 中追加,追加进去最后一条数据
- 返回 sb.toString () 转换为字符串类型返回
/** | |
* 将传入的整个二进制数据全部转换为十六进制的数据 | |
* @param by 接收字节数组 | |
* @param len 数据的大小 | |
* @return | |
*/ | |
private static String bytesArr2HexStr(byte[] by,int len){ | |
// 使用 StringBuffer 来接收转换后的十六进制数据 | |
StringBuffer sb = new StringBuffer(); | |
StringBuffer sbLeft = new StringBuffer(); | |
StringBuffer fenge = new StringBuffer(); | |
StringBuffer sbRight = new StringBuffer(); | |
for(int i = 0;i < len;i ++){ | |
// 每追加一个十六进制数据就拼接一个空格 | |
sbLeft.append(byte2Hex(by[i])+" "); | |
// 判断可见字符的范围 | |
if(by[i] >= 0x20 && by[i] <= 0x7e){ | |
// 将二进制数据转换为 char 字符拼接到 StringBuffer 中 | |
sbRight.append((char)by[i]); | |
}else{ | |
// 如果不在可见范围内则追加一个。即可 | |
sbRight.append("."); | |
} | |
// 判断每第 8 个多追加一个空格 i+1 避免第一个就满足条件 | |
if((i + 1) % 8 == 0) | |
sbLeft.append(" "); | |
// 判断每 16 个进行换行空格 i+1 避免第一个就满足条件 | |
if(i % 16 == 0){ | |
fenge.append("......."); | |
} | |
if((i + 1) % 16 == 0){ | |
sb.append(fenge).append(sbLeft).append(fenge).append(sbRight).append("\r\n"); | |
sbLeft = new StringBuffer(); | |
sbRight = new StringBuffer(); | |
fenge = new StringBuffer(); | |
} | |
} | |
// 将最后的数据追加到 SpringBuffer 中 | |
sb.append(fenge).append(sbLeft).append(" ").append(fenge).append(sbRight).append("\r\n"); | |
// 将 StringBuffer 转换为字符串并返回 | |
return sb.toString(); | |
} | |
--------------------------------Result-------------------------------- | |
Socket[addr=/0:0:0:0:0:0:0:1,port=12171,localport=8080] | |
Socket[addr=/0:0:0:0:0:0:0:1,port=12172,localport=8080] | |
.......47 45 54 20 2F 20 48 54 54 50 2F 31 2E 31 0D 0A .......GET / HTTP/1.1.. | |
.......48 6F 73 74 3A 20 6C 6F 63 61 6C 68 6F 73 74 3A .......Host: localhost: | |
.......38 30 38 30 0D 0A 43 6F 6E 6E 65 63 74 69 6F 6E .......8080..Connection | |
.......3A 20 6B 65 65 70 2D 61 6C 69 76 65 0D 0A 43 61 .......: keep-alive..Ca | |
.......63 68 65 2D 43 6F 6E 74 72 6F 6C 3A 20 6D 61 78 .......che-Control: max | |
.......2D 61 67 65 3D 30 0D 0A 73 65 63 2D 63 68 2D 75 .......-age=0..sec-ch-u | |
.......61 3A 20 22 47 6F 6F 67 6C 65 20 43 68 72 6F 6D .......a: "Google Chrom | |
.......65 22 3B 76 3D 22 31 31 33 22 2C 20 22 43 68 72 .......e";v="113", "Chr | |
.......6F 6D 69 75 6D 22 3B 76 3D 22 31 31 33 22 2C 20 .......omium";v="113", | |
.......22 4E 6F 74 2D 41 2E 42 72 61 6E 64 22 3B 76 3D ......."Not-A.Brand";v= | |
.......22 32 34 22 0D 0A 73 65 63 2D 63 68 2D 75 61 2D ......."24"..sec-ch-ua- | |
.......6D 6F 62 69 6C 65 3A 20 3F 30 0D 0A 73 65 63 2D .......mobile: ?0..sec- | |
.......63 68 2D 75 61 2D 70 6C 61 74 66 6F 72 6D 3A 20 .......ch-ua-platform: | |
.......22 57 69 6E 64 6F 77 73 22 0D 0A 55 70 67 72 61 ......."Windows"..Upgra | |
.......64 65 2D 49 6E 73 65 63 75 72 65 2D 52 65 71 75 .......de-Insecure-Requ | |
.......65 73 74 73 3A 20 31 0D 0A 55 73 65 72 2D 41 67 .......ests: 1..User-Ag | |
.......65 6E 74 3A 20 4D 6F 7A 69 6C 6C 61 2F 35 2E 30 .......ent: Mozilla/5.0 | |
.......20 28 57 69 6E 64 6F 77 73 20 4E 54 20 31 30 2E ....... (Windows NT 10. | |
.......30 3B 20 57 69 6E 36 34 3B 20 78 36 34 29 20 41 .......0; Win64; x64) A | |
.......70 70 6C 65 57 65 62 4B 69 74 2F 35 33 37 2E 33 .......ppleWebKit/537.3 | |
.......36 20 28 4B 48 54 4D 4C 2C 20 6C 69 6B 65 20 47 .......6 (KHTML, like G | |
.......65 63 6B 6F 29 20 43 68 72 6F 6D 65 2F 31 31 33 .......ecko) Chrome/113 | |
.......2E 30 2E 30 2E 30 20 53 61 66 61 72 69 2F 35 33 ........0.0.0 Safari/53 | |
.......37 2E 33 36 0D 0A 41 63 63 65 70 74 3A 20 74 65 .......7.36..Accept: te | |
.......78 74 2F 68 74 6D 6C 2C 61 70 70 6C 69 63 61 74 .......xt/html,applicat | |
.......69 6F 6E 2F 78 68 74 6D 6C 2B 78 6D 6C 2C 61 70 .......ion/xhtml+xml,ap | |
.......70 6C 69 63 61 74 69 6F 6E 2F 78 6D 6C 3B 71 3D .......plication/xml;q= | |
.......30 2E 39 2C 69 6D 61 67 65 2F 61 76 69 66 2C 69 .......0.9,image/avif,i | |
.......6D 61 67 65 2F 77 65 62 70 2C 69 6D 61 67 65 2F .......mage/webp,image/ | |
.......61 70 6E 67 2C 2A 2F 2A 3B 71 3D 30 2E 38 2C 61 .......apng,*`/`*;q=0.8,a | |
.......70 70 6C 69 63 61 74 69 6F 6E 2F 73 69 67 6E 65 .......pplication/signe | |
.......64 2D 65 78 63 68 61 6E 67 65 3B 76 3D 62 33 3B .......d-exchange;v=b3; | |
.......71 3D 30 2E 37 0D 0A 53 65 63 2D 46 65 74 63 68 .......q=0.7..Sec-Fetch | |
.......2D 53 69 74 65 3A 20 6E 6F 6E 65 0D 0A 53 65 63 .......-Site: none..Sec | |
.......2D 46 65 74 63 68 2D 4D 6F 64 65 3A 20 6E 61 76 .......-Fetch-Mode: nav | |
.......69 67 61 74 65 0D 0A 53 65 63 2D 46 65 74 63 68 .......igate..Sec-Fetch | |
.......2D 55 73 65 72 3A 20 3F 31 0D 0A 53 65 63 2D 46 .......-User: ?1..Sec-F | |
.......65 74 63 68 2D 44 65 73 74 3A 20 64 6F 63 75 6D .......etch-Dest: docum | |
.......65 6E 74 0D 0A 41 63 63 65 70 74 2D 45 6E 63 6F .......ent..Accept-Enco | |
.......64 69 6E 67 3A 20 67 7A 69 70 2C 20 64 65 66 6C .......ding: gzip, defl | |
.......61 74 65 2C 20 62 72 0D 0A 41 63 63 65 70 74 2D .......ate, br..Accept- | |
.......4C 61 6E 67 75 61 67 65 3A 20 65 6E 2D 55 53 2C .......Language: en-US, | |
.......65 6E 3B 71 3D 30 2E 39 2C 7A 68 2D 43 4E 3B 71 .......en;q=0.9,zh-CN;q | |
.......3D 30 2E 38 2C 7A 68 3B 71 3D 30 2E 37 0D 0A 43 .......=0.8,zh;q=0.7..C | |
.......6F 6F 6B 69 65 3A 20 49 64 65 61 2D 38 32 39 36 .......ookie: Idea-8296 | |
.......65 62 33 31 3D 31 36 63 35 64 63 30 37 2D 36 31 .......eb31=16c5dc07-61 | |
.......35 35 2D 34 31 33 64 2D 62 33 30 38 2D 39 30 66 .......55-413d-b308-90f | |
.......35 63 38 66 62 35 35 66 65 0D 0A 0D 0A .......5c8fb55fe.... | |
读取到的字节数是: 765 | |
GET / HTTP/1.1 | |
Host: localhost:8080 | |
Connection: keep-alive | |
Cache-Control: max-age=0 | |
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24" | |
sec-ch-ua-mobile: ?0 | |
sec-ch-ua-platform: "Windows" | |
Upgrade-Insecure-Requests: 1 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 | |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*`/`*;q=0.8,application/signed-exchange;v=b3;q=0.7 | |
Sec-Fetch-Site: none | |
Sec-Fetch-Mode: navigate | |
Sec-Fetch-User: ?1 | |
Sec-Fetch-Dest: document | |
Accept-Encoding: gzip, deflate, br | |
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 | |
Cookie: Idea-8296eb31=16c5dc07-6155-413d-b308-90f5c8fb55fe | |
.......47 45 54 20 2F 66 61 76 69 63 6F 6E 2E 69 63 6F .......GET /favicon.ico | |
.......20 48 54 54 50 2F 31 2E 31 0D 0A 48 6F 73 74 3A ....... HTTP/1.1..Host: | |
.......20 6C 6F 63 61 6C 68 6F 73 74 3A 38 30 38 30 0D ....... localhost:8080. | |
.......0A 43 6F 6E 6E 65 63 74 69 6F 6E 3A 20 6B 65 65 ........Connection: kee | |
.......70 2D 61 6C 69 76 65 0D 0A 73 65 63 2D 63 68 2D .......p-alive..sec-ch- | |
.......75 61 3A 20 22 47 6F 6F 67 6C 65 20 43 68 72 6F .......ua: "Google Chro | |
.......6D 65 22 3B 76 3D 22 31 31 33 22 2C 20 22 43 68 .......me";v="113", "Ch | |
.......72 6F 6D 69 75 6D 22 3B 76 3D 22 31 31 33 22 2C .......romium";v="113", | |
.......20 22 4E 6F 74 2D 41 2E 42 72 61 6E 64 22 3B 76 ....... "Not-A.Brand";v | |
.......3D 22 32 34 22 0D 0A 73 65 63 2D 63 68 2D 75 61 .......="24"..sec-ch-ua | |
.......2D 6D 6F 62 69 6C 65 3A 20 3F 30 0D 0A 55 73 65 .......-mobile: ?0..Use | |
.......72 2D 41 67 65 6E 74 3A 20 4D 6F 7A 69 6C 6C 61 .......r-Agent: Mozilla | |
.......2F 35 2E 30 20 28 57 69 6E 64 6F 77 73 20 4E 54 ......./5.0 (Windows NT | |
.......20 31 30 2E 30 3B 20 57 69 6E 36 34 3B 20 78 36 ....... 10.0; Win64; x6 | |
.......34 29 20 41 70 70 6C 65 57 65 62 4B 69 74 2F 35 .......4) AppleWebKit/5 | |
.......33 37 2E 33 36 20 28 4B 48 54 4D 4C 2C 20 6C 69 .......37.36 (KHTML, li | |
.......6B 65 20 47 65 63 6B 6F 29 20 43 68 72 6F 6D 65 .......ke Gecko) Chrome | |
.......2F 31 31 33 2E 30 2E 30 2E 30 20 53 61 66 61 72 ......./113.0.0.0 Safar | |
.......69 2F 35 33 37 2E 33 36 0D 0A 73 65 63 2D 63 68 .......i/537.36..sec-ch | |
.......2D 75 61 2D 70 6C 61 74 66 6F 72 6D 3A 20 22 57 .......-ua-platform: "W | |
.......69 6E 64 6F 77 73 22 0D 0A 41 63 63 65 70 74 3A .......indows"..Accept: | |
.......20 69 6D 61 67 65 2F 61 76 69 66 2C 69 6D 61 67 ....... image/avif,imag | |
.......65 2F 77 65 62 70 2C 69 6D 61 67 65 2F 61 70 6E .......e/webp,image/apn | |
.......67 2C 69 6D 61 67 65 2F 73 76 67 2B 78 6D 6C 2C .......g,image/svg+xml, | |
.......69 6D 61 67 65 2F 2A 2C 2A 2F 2A 3B 71 3D 30 2E .......image/*,*/*;q=0. | |
.......38 0D 0A 53 65 63 2D 46 65 74 63 68 2D 53 69 74 .......8..Sec-Fetch-Sit | |
.......65 3A 20 73 61 6D 65 2D 6F 72 69 67 69 6E 0D 0A .......e: same-origin.. | |
.......53 65 63 2D 46 65 74 63 68 2D 4D 6F 64 65 3A 20 .......Sec-Fetch-Mode: | |
.......6E 6F 2D 63 6F 72 73 0D 0A 53 65 63 2D 46 65 74 .......no-cors..Sec-Fet | |
.......63 68 2D 44 65 73 74 3A 20 69 6D 61 67 65 0D 0A .......ch-Dest: image.. | |
.......52 65 66 65 72 65 72 3A 20 68 74 74 70 3A 2F 2F .......Referer: http:// | |
.......6C 6F 63 61 6C 68 6F 73 74 3A 38 30 38 30 2F 0D .......localhost:8080/. | |
.......0A 41 63 63 65 70 74 2D 45 6E 63 6F 64 69 6E 67 ........Accept-Encoding | |
.......3A 20 67 7A 69 70 2C 20 64 65 66 6C 61 74 65 2C .......: gzip, deflate, | |
.......20 62 72 0D 0A 41 63 63 65 70 74 2D 4C 61 6E 67 ....... br..Accept-Lang | |
.......75 61 67 65 3A 20 65 6E 2D 55 53 2C 65 6E 3B 71 .......uage: en-US,en;q | |
.......3D 30 2E 39 2C 7A 68 2D 43 4E 3B 71 3D 30 2E 38 .......=0.9,zh-CN;q=0.8 | |
.......2C 7A 68 3B 71 3D 30 2E 37 0D 0A 43 6F 6F 6B 69 .......,zh;q=0.7..Cooki | |
.......65 3A 20 49 64 65 61 2D 38 32 39 36 65 62 33 31 .......e: Idea-8296eb31 | |
.......3D 31 36 63 35 64 63 30 37 2D 36 31 35 35 2D 34 .......=16c5dc07-6155-4 | |
.......31 33 64 2D 62 33 30 38 2D 39 30 66 35 63 38 66 .......13d-b308-90f5c8f | |
.......62 35 35 66 65 0D 0A 0D 0A .......b55fe.... | |
读取到的字节数是: 665 | |
GET /favicon.ico HTTP/1.1 | |
Host: localhost:8080 | |
Connection: keep-alive | |
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24" | |
sec-ch-ua-mobile: ?0 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 | |
sec-ch-ua-platform: "Windows" | |
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8 | |
Sec-Fetch-Site: same-origin | |
Sec-Fetch-Mode: no-cors | |
Sec-Fetch-Dest: image | |
Referer: http://localhost:8080/ | |
Accept-Encoding: gzip, deflate, br | |
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 | |
Cookie: Idea-8296eb31=16c5dc07-6155-413d-b308-90f5c8fb55fe |
# 回显主页和 favicon🍨
主页在项目结构中创建一个 index.html 文件和 icon 图标文件,在程序中读取并解析
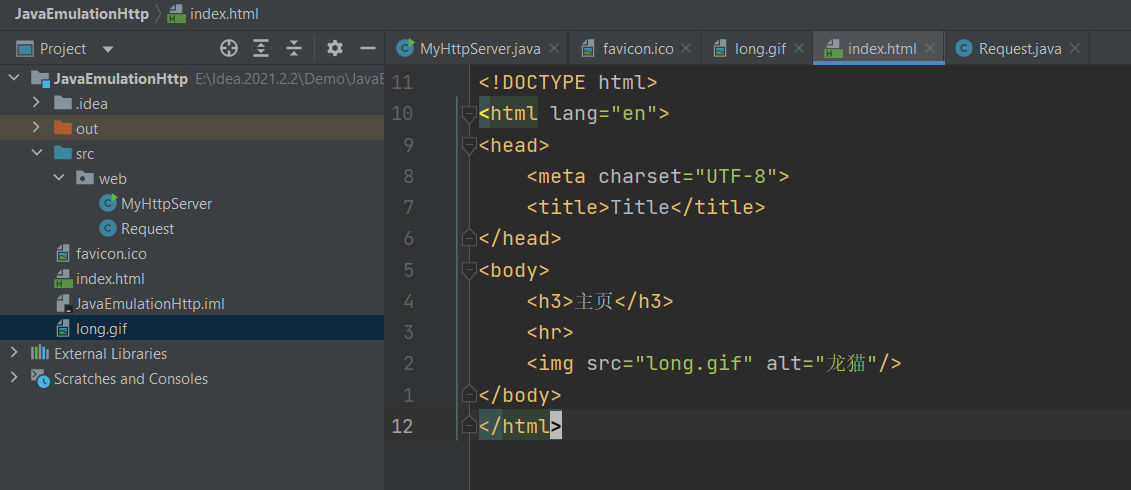
<font style="color:red">index,favicon,long.gif 是在项目的根目录下不是在 src 下 </font>.
创建封装请求的类
/** | |
* 把请求的字符串封装成请求的类 | |
* 请求的类 | |
*/ | |
public class Request { | |
// 请求方式 | |
private String method; | |
// 请求的 url | |
private String uri; | |
public String getMethod() { | |
return method; | |
} | |
public void setMethod(String method) { | |
this.method = method; | |
} | |
public String getUri() { | |
return uri; | |
} | |
public void setUri(String uri) { | |
this.uri = uri; | |
} | |
} |
HttpServer 类中定义解析请求方法
/** | |
* 解析请求 | |
* @param msg | |
* @return | |
*/ | |
private static Request parseRequest(String msg){ | |
Request request = new Request(); | |
String[] split = msg.split("\r\n"); | |
// 解析第一行 | |
//GET /favicon.ico HTTP/1.1 | |
String[] split0 = split[0].split(" "); | |
request.setMethod(split0[0]);//method: GET | |
request.setUri(split0[1]);//uri: / 或者 /favicon.ico | |
return request; | |
} |
main:
public static void main(String... args) { | |
try { | |
ServerSocket serverSocket = new ServerSocket(8080); | |
System.out.println("服务器已经启动,监听端口为:8080 ..."); | |
ExecutorService executorService = Executors.newCachedThreadPool(); | |
while (true) { | |
Socket socket = serverSocket.accept(); | |
executorService.execute(() -> { | |
InputStream is = null; | |
OutputStream os = null; | |
try { | |
System.out.println(socket); | |
is = socket.getInputStream(); | |
os = socket.getOutputStream(); | |
byte[] by = new byte[1024 * 1024]; | |
int len = is.read(by); | |
if (len != -1) { | |
String hexMsg = bytesArr2HexStr(by,len); | |
System.out.println(hexMsg); | |
System.out.println("读取到的字节数是: " + len); | |
String msg = new String(by, 0, len); | |
System.out.println(msg); | |
Request request = parseRequest(msg); | |
// 响应给浏览器需要使用 Http 协议 | |
String body = "<h1>" + count + "</h1>"+"\r\n"+"text/plain : plain plain text does not parse html tags"; | |
//http 协议 / 版本 状态码 状态 后面的格式必须是 \r\n 不能乱写否则报错 | |
String response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本的内容大小 | |
"Content-Length: " + body.getBytes().length + "\r\n" + | |
// 告诉浏览器文本类型:普通文本 /plain 不解析 html 标签代码 设置字符集 | |
"Content-Type: text/plain; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n" +// 回车换行,否则后面的数据接收不到 | |
//body 响应浏览器内容 | |
// 要返回给浏览器的文本正文 (内容) | |
body + "\r\n";// 回车换行,否则后面的数据接收不到 | |
String file = null; | |
// 判断 1:读取 index.html 文件 | |
// 判断 2:读取 /favicon.icon 图标文件 | |
// 判断请求路径是否带有 index.html,有则执行 | |
// 请求并不是一次全部请求资源而是一个一个请求所以使用 if else if 先判断 index.html 然后 favicon.icon 再然后 long.gif (图片) | |
if(/*request.getUri().equals("/") || */request.getUri().equals("/index.html")){ | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:文本 /html 解析 html 标签代码 | |
"Content-Type: text/html; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
// 判断是否请求了 favicon.ico,请求则执行 | |
}else if(request.getUri().equals("/favicon.ico")){ | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:图片 /x-icon 设置字符集 | |
"Content-Type: image/x-icon; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
} | |
// 将 HTTP 协议信息写出到浏览器中 (响应回去) | |
os.write(response.getBytes()); | |
// 判断如果 file 不为空,那么请求的就是 index.html 页面或者 favicon.icon 则执行方法体 | |
if(file != null){ | |
// 文件输入流读取文件 | |
FileInputStream fis = new FileInputStream(file); | |
while((len = fis.read(by)) != -1){ | |
// 将读取到的页面字节数据写出到浏览器 | |
os.write(by,0,len); | |
} | |
}else{ | |
// 将上面的 HTTP 协议信息和响应的数据写出到浏览器中 | |
os.write(response.getBytes()); | |
count++; | |
} | |
} else { | |
System.out.println("没有读取到数据"); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
}finally{ | |
try{ | |
if(os != null){ | |
os.flush();// 将数据刷出 | |
} | |
if(socket != null){ | |
// 上一段对话已经结束进行下一段对话 | |
socket.shutdownOutput(); | |
socket.close();// 关闭套接字资源 | |
} | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
}); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
} | |
} |
效果:
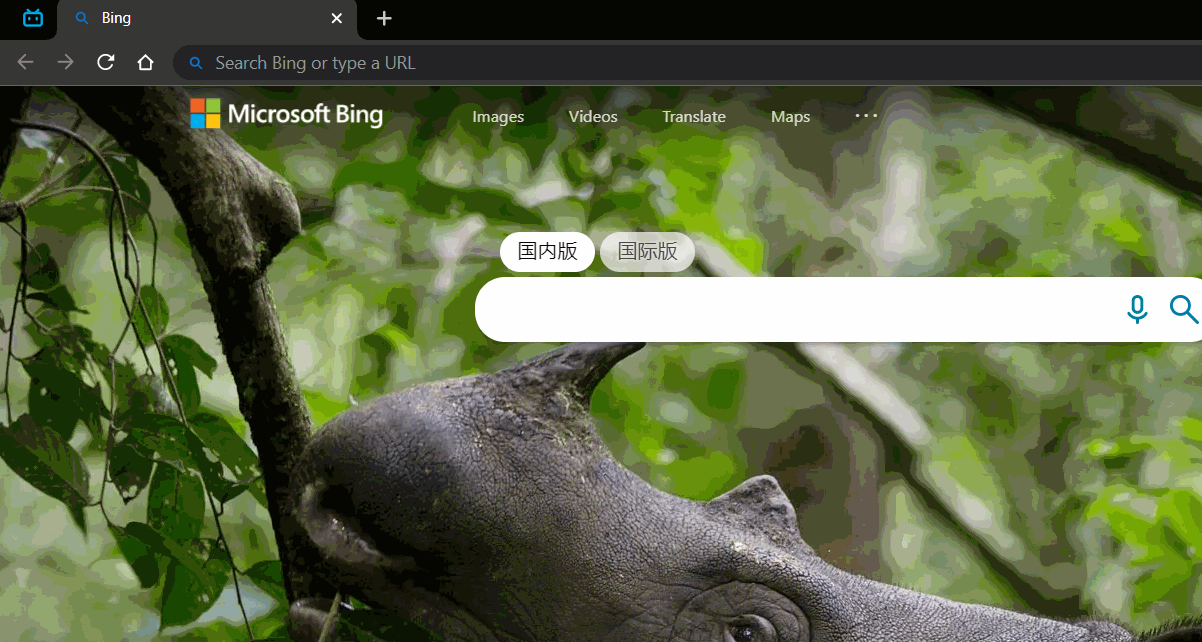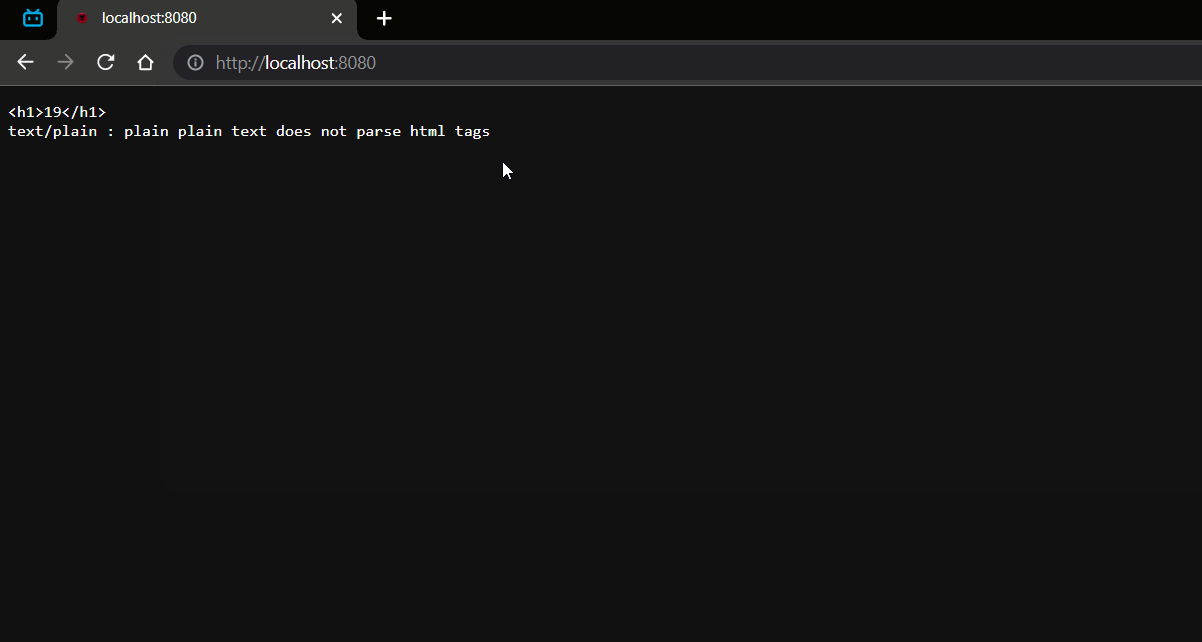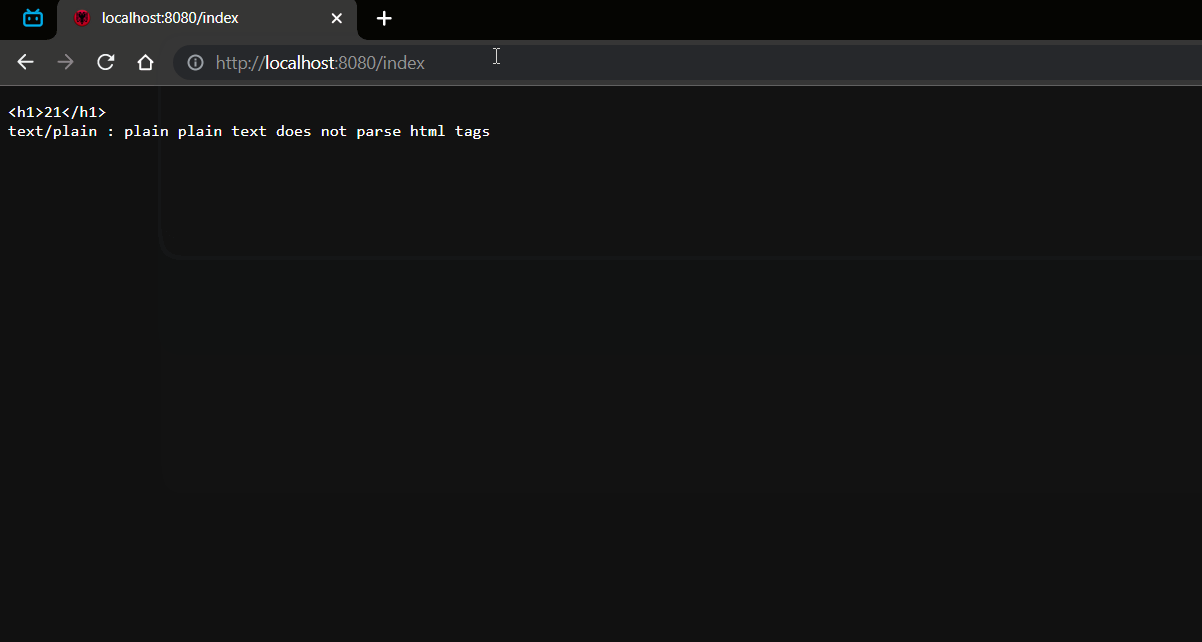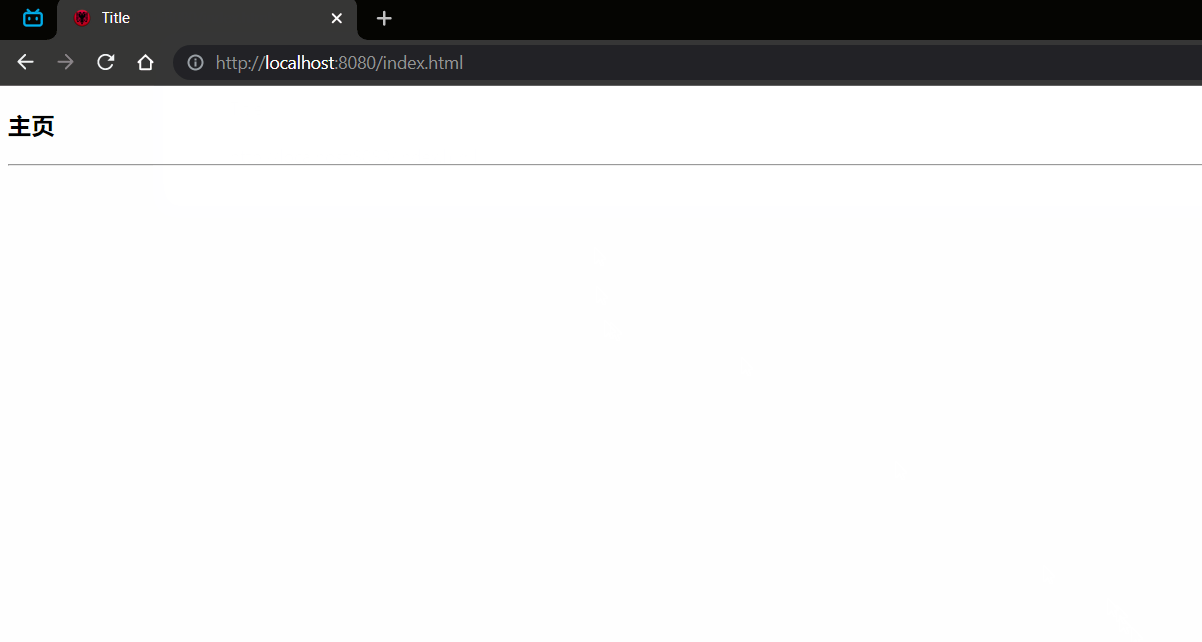
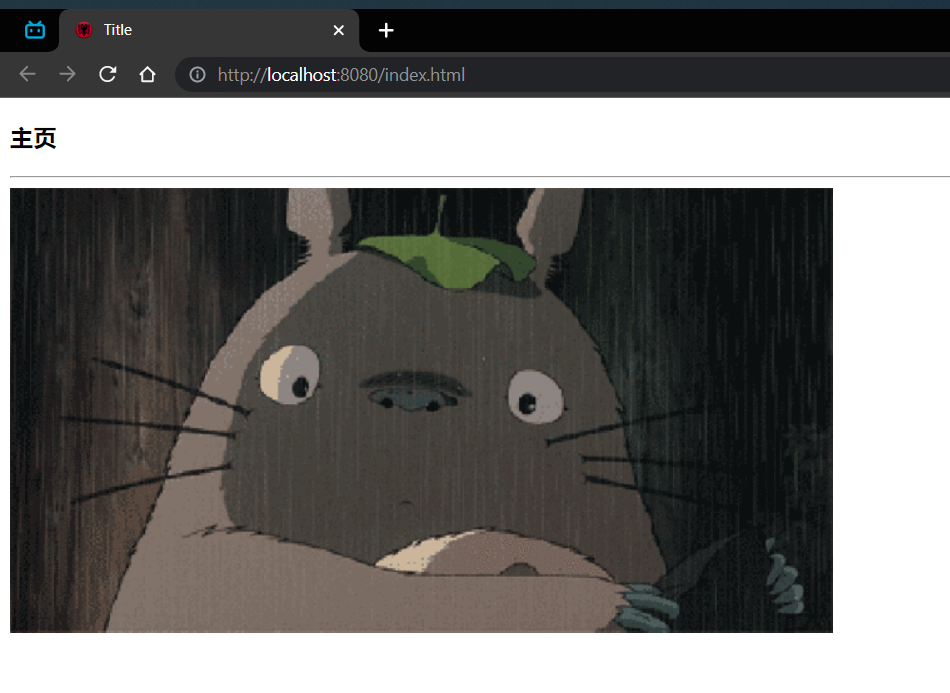
# 主页中有 img 图片标签🏒
index.html
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<title>Title</title> | |
</head> | |
<body> | |
<h3>主页</h3> | |
<hr> | |
<img src="long.gif" alt="龙猫"/> | |
</body> | |
</html> |
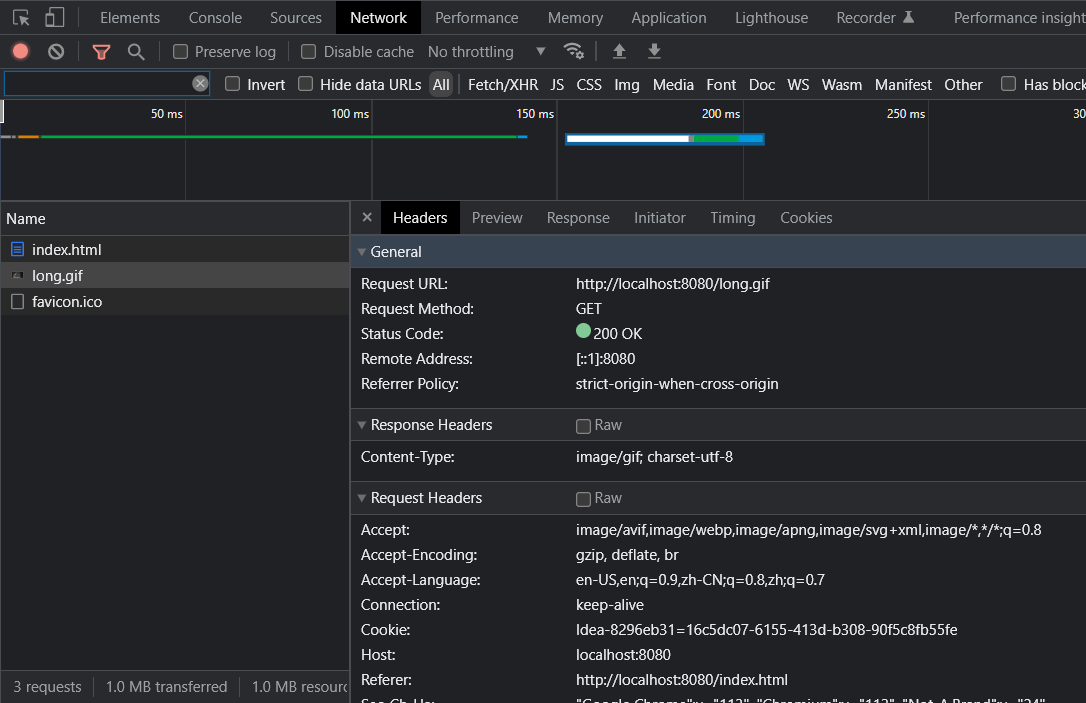
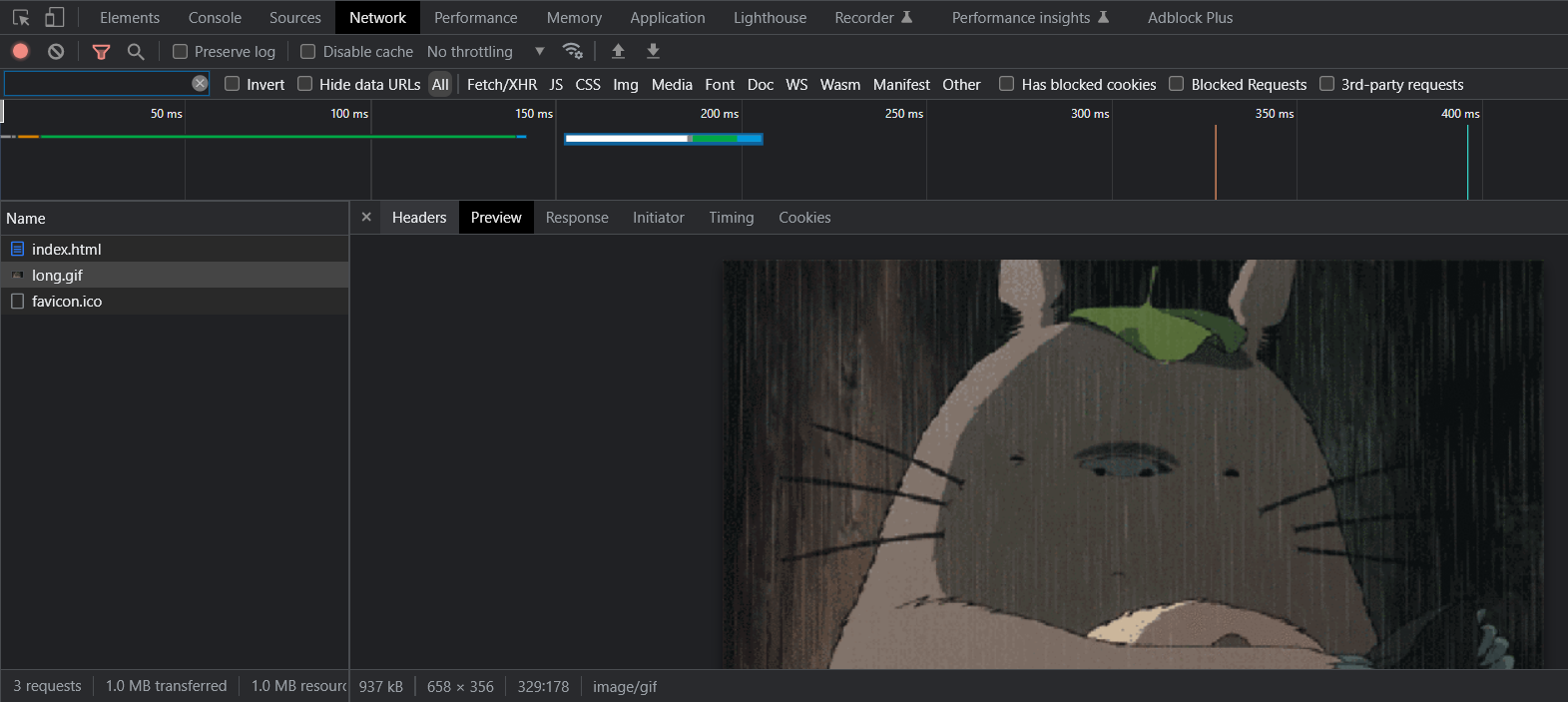
在 http 中并不是一次性请求全部的 html 资源的 img 会发送一次请来获取图片资源,favicon.icon 也会发送一次请求。
第一次请求:/index.html
.......47 45 54 20 2F 69 6E 64 65 78 2E 68 74 6D 6C 20 .......GET /index.html | |
读取到的字节数是: 775 | |
GET /index.html HTTP/1.1 |
第二次请求:/img/long.gif
.......47 45 54 20 2F 6C 6F 6E 67 2E 67 69 66 20 48 54 .......GET /long.gif HT | |
读取到的字节数是: 724 | |
GET /long.gif HTTP/1.1 |
第三次请求:/favicon.ico
.......47 45 54 20 2F 66 61 76 69 63 6F 6E 2E 69 63 6F .......GET /favicon.ico | |
读取到的字节数是: 675 | |
GET /favicon.ico HTTP/1.1 |
编写请求图片资源代码
public static void main(String... args) { | |
try { | |
ServerSocket serverSocket = new ServerSocket(8080); | |
System.out.println("服务器已经启动,监听端口为:8080 ..."); | |
ExecutorService executorService = Executors.newCachedThreadPool(); | |
while (true) { | |
Socket socket = serverSocket.accept(); | |
executorService.execute(() -> { | |
InputStream is = null; | |
OutputStream os = null; | |
try { | |
System.out.println(socket); | |
is = socket.getInputStream(); | |
os = socket.getOutputStream(); | |
byte[] by = new byte[1024 * 1024]; | |
int len = is.read(by); | |
if (len != -1) { | |
String hexMsg = bytesArr2HexStr(by,len); | |
System.out.println(hexMsg); | |
System.out.println("读取到的字节数是: " + len); | |
String msg = new String(by, 0, len); | |
System.out.println(msg); | |
Request request = parseRequest(msg); | |
// 响应给浏览器需要使用 Http 协议 | |
String body = "<h1>" + count + "</h1>"+"\r\n"+"text/plain : plain plain text does not parse html tags"; | |
//http 协议 / 版本 状态码 状态 后面的格式必须是 \r\n 不能乱写否则报错 | |
String response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本的内容大小 | |
"Content-Length: " + body.getBytes().length + "\r\n" + | |
// 告诉浏览器文本类型:普通文本 /plain 不解析任何代码语义 | |
"Content-Type: text/plain; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n" +// 回车换行,否则后面的数据接收不到 | |
//body 响应浏览器内容 | |
// 要返回给浏览器的文本正文 (内容) | |
body + "\r\n";// 回车换行,否则后面的数据接收不到 | |
String file = null; | |
// 判断请求的是否是 index.html 页面 | |
if(request.getUri().equals("/index.html")){ | |
//file 赋值为 index.html 文件的路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:文本 /html html 页面,解析标签 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
// 判断请求是否为 favicon.icon | |
}else if(request.getUri().equals("/favicon.ico")){ | |
// 将 file 赋值为 icon 的图标路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:图片类型 /x-icon 设置字符集 | |
"Content-Type: image/x-icon; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
// 判断请求的文件后缀名是否为.gif | |
}else if(request.getUri().endsWith(".gif")){ | |
//file 赋值为 gif 图片的路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
//HTTP 请求 / 版本 状态码 状态 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求的类型: 图片 /gif 格式 设置字符集 | |
"Content-Type: image/gif; charset-utf-8\r\n"+ | |
"\r\n"; | |
} | |
// 将 HTTP 协议信息写出到浏览器中 (响应回去) | |
os.write(response.getBytes()); | |
// 判断如果 file 不为空,那么请求的就是 index.html 页面则执行方法体 | |
if(file != null){ | |
// 文件输入流读取文件 | |
FileInputStream fis = new FileInputStream(file); | |
while((len = fis.read(by)) != -1){ | |
// 将读取到的页面字节数据写出到浏览器 | |
os.write(by,0,len); | |
} | |
}else{ | |
// 将上面的 HTTP 协议信息和响应的数据写出到浏览器中 | |
os.write(response.getBytes()); | |
count++; | |
} | |
} else { | |
System.out.println("没有读取到数据"); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
}finally{ | |
try{ | |
if(os != null){ | |
os.flush();// 将数据刷出 | |
} | |
if(socket != null){ | |
// 上一段对话已经结束进行下一段对话 | |
socket.shutdownOutput(); | |
socket.close();// 关闭套接字资源 | |
} | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
}); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
} | |
} |
效果:
# 主页跳转到登录页面🕋
在 index.html 页面中添加一个 跳转到 (login.html) 另一个页面的 a 标签
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<title>Title</title> | |
</head> | |
<body> | |
<h3>主页</h3> | |
<a href="login.html" target="_self">登录</a> | |
<hr> | |
<img src="long.gif" alt="龙猫"/> | |
</body> | |
</html> |
在 <font style="color:red"> 项目根目录 </font> 下创建一个 login.html 页面
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<title>Title</title> | |
</head> | |
<body> | |
<h3>登录</h3> | |
<form> | |
<p>账号:<input type="text" name="account"></p> | |
<p>密码:<input type="password" name="password"></p> | |
<p><input type="submit" value="登录"></p> | |
</form> | |
</body> | |
</html> |
继续在判断资源路径的后面编写跳转时请求另一个页面的代码,当请求以后缀名为.html 文件时则执行方法体给 file 赋值 login.html 通过 substring (1); 从下标 1 开始截取值结果为 login.html
else if(request.getUri().endsWith(".html")){ | |
//file 赋值为请求的名称后缀名为 html 的文件名称去掉前面的 / | |
file = request.getUri().substring(1);//login.html | |
// 设置 HTTP 协议 | |
// 协议 / 版本 状态码 状态 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求的类型:文本 /html 解析 html 标签代码 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n"+ | |
// 必须设置换行空格 | |
"\r\n"; | |
} |
# 表单登录回显文本🍔
编写 login.html 文件给 form 标签加上提交信息和方式,使用 后缀名.do 或者.action 来区分其它文件的后缀名跳转
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<title>Title</title> | |
</head> | |
<body> | |
<h3>登录</h3> | |
<!-- 假设 账号:123 密码:admin , 允许登录 一般选择.do .action--> | |
<!-- 我们要避开程序中已经写过的后缀名写法 --> | |
<form action="login.do" method="get"> | |
<p>账号:<input type="text" name="account"></p> | |
<p>密码:<input type="password" name="password"></p> | |
<p><input type="submit" value="登录"></p> | |
</form> | |
</body> | |
</html> |
查看 login.html 点击登录后提交的路径信息
提交信息为:/login.do?account=admin&password=123
Socket[addr=/0:0:0:0:0:0:0:1,port=8531,localport=8080] | |
.......47 45 54 20 2F 6C 6F 67 69 6E 2E 64 6F 3F 61 63 .......GET /login.do?ac | |
.......63 6F 75 6E 74 3D 61 64 6D 69 6E 26 70 61 73 73 .......count=admin&pass | |
.......77 6F 72 64 3D 31 32 33 20 48 54 54 50 2F 31 2E .......word=123 HTTP/1. | |
.......31 0D 0A 48 6F 73 74 3A 20 6C 6F 63 61 6C 68 6F .......1..Host: localho | |
.......73 74 3A 38 30 38 30 0D 0A 43 6F 6E 6E 65 63 74 .......st:8080..Connect | |
.......69 6F 6E 3A 20 6B 65 65 70 2D 61 6C 69 76 65 0D .......ion: keep-alive. | |
.......0A 73 65 63 2D 63 68 2D 75 61 3A 20 22 47 6F 6F ........sec-ch-ua: "Goo | |
.......67 6C 65 20 43 68 72 6F 6D 65 22 3B 76 3D 22 31 .......gle Chrome";v="1 | |
.......31 33 22 2C 20 22 43 68 72 6F 6D 69 75 6D 22 3B .......13", "Chromium"; | |
.......76 3D 22 31 31 33 22 2C 20 22 4E 6F 74 2D 41 2E .......v="113", "Not-A. | |
.......42 72 61 6E 64 22 3B 76 3D 22 32 34 22 0D 0A 73 .......Brand";v="24"..s | |
.......65 63 2D 63 68 2D 75 61 2D 6D 6F 62 69 6C 65 3A .......ec-ch-ua-mobile: | |
.......20 3F 30 0D 0A 73 65 63 2D 63 68 2D 75 61 2D 70 ....... ?0..sec-ch-ua-p | |
.......6C 61 74 66 6F 72 6D 3A 20 22 57 69 6E 64 6F 77 .......latform: "Window | |
.......73 22 0D 0A 55 70 67 72 61 64 65 2D 49 6E 73 65 .......s"..Upgrade-Inse | |
.......63 75 72 65 2D 52 65 71 75 65 73 74 73 3A 20 31 .......cure-Requests: 1 | |
.......0D 0A 55 73 65 72 2D 41 67 65 6E 74 3A 20 4D 6F .........User-Agent: Mo | |
.......7A 69 6C 6C 61 2F 35 2E 30 20 28 57 69 6E 64 6F .......zilla/5.0 (Windo | |
.......77 73 20 4E 54 20 31 30 2E 30 3B 20 57 69 6E 36 .......ws NT 10.0; Win6 | |
.......34 3B 20 78 36 34 29 20 41 70 70 6C 65 57 65 62 .......4; x64) AppleWeb | |
.......4B 69 74 2F 35 33 37 2E 33 36 20 28 4B 48 54 4D .......Kit/537.36 (KHTM | |
.......4C 2C 20 6C 69 6B 65 20 47 65 63 6B 6F 29 20 43 .......L, like Gecko) C | |
.......68 72 6F 6D 65 2F 31 31 33 2E 30 2E 30 2E 30 20 .......hrome/113.0.0.0 | |
.......53 61 66 61 72 69 2F 35 33 37 2E 33 36 0D 0A 41 .......Safari/537.36..A | |
.......63 63 65 70 74 3A 20 74 65 78 74 2F 68 74 6D 6C .......ccept: text/html | |
.......2C 61 70 70 6C 69 63 61 74 69 6F 6E 2F 78 68 74 .......,application/xht | |
.......6D 6C 2B 78 6D 6C 2C 61 70 70 6C 69 63 61 74 69 .......ml+xml,applicati | |
.......6F 6E 2F 78 6D 6C 3B 71 3D 30 2E 39 2C 69 6D 61 .......on/xml;q=0.9,ima | |
.......67 65 2F 61 76 69 66 2C 69 6D 61 67 65 2F 77 65 .......ge/avif,image/we | |
.......62 70 2C 69 6D 61 67 65 2F 61 70 6E 67 2C 2A 2F .......bp,image/apng,*/ | |
.......2A 3B 71 3D 30 2E 38 2C 61 70 70 6C 69 63 61 74 .......*;q=0.8,applicat | |
.......69 6F 6E 2F 73 69 67 6E 65 64 2D 65 78 63 68 61 .......ion/signed-excha | |
.......6E 67 65 3B 76 3D 62 33 3B 71 3D 30 2E 37 0D 0A .......nge;v=b3;q=0.7.. | |
.......53 65 63 2D 46 65 74 63 68 2D 53 69 74 65 3A 20 .......Sec-Fetch-Site: | |
.......73 61 6D 65 2D 6F 72 69 67 69 6E 0D 0A 53 65 63 .......same-origin..Sec | |
.......2D 46 65 74 63 68 2D 4D 6F 64 65 3A 20 6E 61 76 .......-Fetch-Mode: nav | |
.......69 67 61 74 65 0D 0A 53 65 63 2D 46 65 74 63 68 .......igate..Sec-Fetch | |
.......2D 55 73 65 72 3A 20 3F 31 0D 0A 53 65 63 2D 46 .......-User: ?1..Sec-F | |
.......65 74 63 68 2D 44 65 73 74 3A 20 64 6F 63 75 6D .......etch-Dest: docum | |
.......65 6E 74 0D 0A 52 65 66 65 72 65 72 3A 20 68 74 .......ent..Referer: ht | |
.......74 70 3A 2F 2F 6C 6F 63 61 6C 68 6F 73 74 3A 38 .......tp://localhost:8 | |
.......30 38 30 2F 6C 6F 67 69 6E 2E 68 74 6D 6C 0D 0A .......080/login.html.. | |
.......41 63 63 65 70 74 2D 45 6E 63 6F 64 69 6E 67 3A .......Accept-Encoding: | |
.......20 67 7A 69 70 2C 20 64 65 66 6C 61 74 65 2C 20 ....... gzip, deflate, | |
.......62 72 0D 0A 41 63 63 65 70 74 2D 4C 61 6E 67 75 .......br..Accept-Langu | |
.......61 67 65 3A 20 65 6E 2D 55 53 2C 65 6E 3B 71 3D .......age: en-US,en;q= | |
.......30 2E 39 2C 7A 68 2D 43 4E 3B 71 3D 30 2E 38 2C .......0.9,zh-CN;q=0.8, | |
.......7A 68 3B 71 3D 30 2E 37 0D 0A 43 6F 6F 6B 69 65 .......zh;q=0.7..Cookie | |
.......3A 20 49 64 65 61 2D 38 32 39 36 65 62 33 31 3D .......: Idea-8296eb31= | |
.......31 36 63 35 64 63 30 37 2D 36 31 35 35 2D 34 31 .......16c5dc07-6155-41 | |
.......33 64 2D 62 33 30 38 2D 39 30 66 35 63 38 66 62 .......3d-b308-90f5c8fb | |
.......35 35 66 65 0D 0A 0D 0A .......55fe.... | |
读取到的字节数是: 824 | |
GET /login.do?account=admin&password=123 HTTP/1.1 | |
Host: localhost:8080 | |
Connection: keep-alive | |
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24" | |
sec-ch-ua-mobile: ?0 | |
sec-ch-ua-platform: "Windows" | |
Upgrade-Insecure-Requests: 1 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 | |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 | |
Sec-Fetch-Site: same-origin | |
Sec-Fetch-Mode: navigate | |
Sec-Fetch-User: ?1 | |
Sec-Fetch-Dest: document | |
Referer: http://localhost:8080/login.html | |
Accept-Encoding: gzip, deflate, br | |
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 | |
Cookie: Idea-8296eb31=16c5dc07-6155-413d-b308-90f5c8fb55fe |
解析请求:
切割路径:
- 将 /login.html?account=admin&password=123 以?进行切割分为两段
- 拿到请求 uri:/login.html 设置到 封装请求类的 Uri 成员字段中
- 拿到 account=admin&password=123,再进行切割以 & 进行切割分为两段
- 拿到的切割后的数据为 account=admin 和 password=123,遍历 String 数组
- 在 for 中使用 indexOf ("="); 获取 = 的下标值,再使用 substring (0,index) 获取前面的 account,使用 substring (index) 获取后面的 admin,并以键值对的形式存入 Map 集合中
/** | |
* 解析请求 | |
* @param msg | |
* @return | |
*/ | |
private static Request parseRequest(String msg){ | |
Request request = new Request(); | |
String[] split = msg.split("\r\n"); | |
// 解析第一行 | |
//GET /favicon.ico HTTP/1.1 | |
String[] split0 = split[0].split(" "); | |
request.setMethod(split0[0]);//method : GET | |
// 判断请求路径中是否包含?号 | |
if(split0[1].contains("?")){ | |
///login.do?account=admin&password=123, 以?号进行切割 | |
String[] split1 = split0[1].split("[?]"); | |
// /login.do | |
request.setUri(split1[0]); | |
// account=admin&password=123 | |
String[] split2 = split1[1].split("[&]"); | |
/** | |
* 循环数据 | |
* account=admin | |
* password=123 | |
*/ | |
for(String i:split2){ | |
// 获取 = 的索引值 | |
int idx = i.indexOf("="); | |
// 将 account=admin 和 password=123 拆分为 key,value 存储到 Map 集合中 key 为:将 account,value:admin | |
request.getParamMap().put(i.substring(0,idx),i.substring(idx+1)); | |
} | |
}else{ | |
request.setUri(split0[1]);//uri : / 或者 /favicon.ico | |
} | |
return request; | |
} |
在封装请求的类中定义一个成员字段:Map 集合用于存储用户登录提交的信息:
/** | |
* 把请求的字符串封装成请求的类 | |
* 请求的类 | |
*/ | |
public class Request { | |
// 请求方式 | |
private String method; | |
// 请求的 url | |
private String uri; | |
// 以键值对的形式存储用户提交账号和密码的信息 | |
private Map<String,String> paramMap = new HashMap<>();// 存放参数 例如:account=admin&password=123 | |
public String getMethod() { | |
return method; | |
} | |
public void setMethod(String method) { | |
this.method = method; | |
} | |
public String getUri() { | |
return uri; | |
} | |
public void setUri(String uri) { | |
this.uri = uri; | |
} | |
public Map<String, String> getParamMap() { | |
return paramMap; | |
} | |
public void setParamMap(Map<String, String> paramMap) { | |
this.paramMap = paramMap; | |
} | |
} |
在 HttpServer 类中的 main 方法中继续编写请求处理代码:
else if(request.getUri().equals("/login.do")){ | |
// 通过 key 获取 value 获取账号 | |
String account = request.getParamMap().get("account"); | |
// 通过 key 获取 value 获取密码 | |
String password = request.getParamMap().get("password"); | |
// 协议 / 版本 状态码 状态 空格换行 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求类型:文本 /html 解析 html 标签代码 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n"+ | |
// 空格换行 | |
"\r\n"; | |
os.write(response.getBytes()); | |
// 判断账号和密码是否是我们期望的 | |
if("admin".equals(account) && "123".equals(password)){ | |
os.write("<h1>Login successful<h1>".getBytes()); | |
}else{ | |
os.write("<h1>Login failed<h1>".getBytes()); | |
} | |
// 结束方法 | |
return; | |
} |
# 转发和重定向⚡️
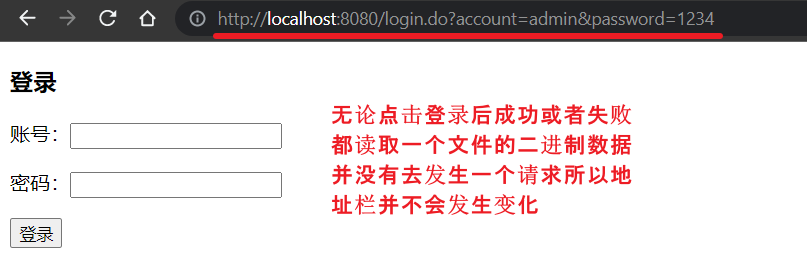
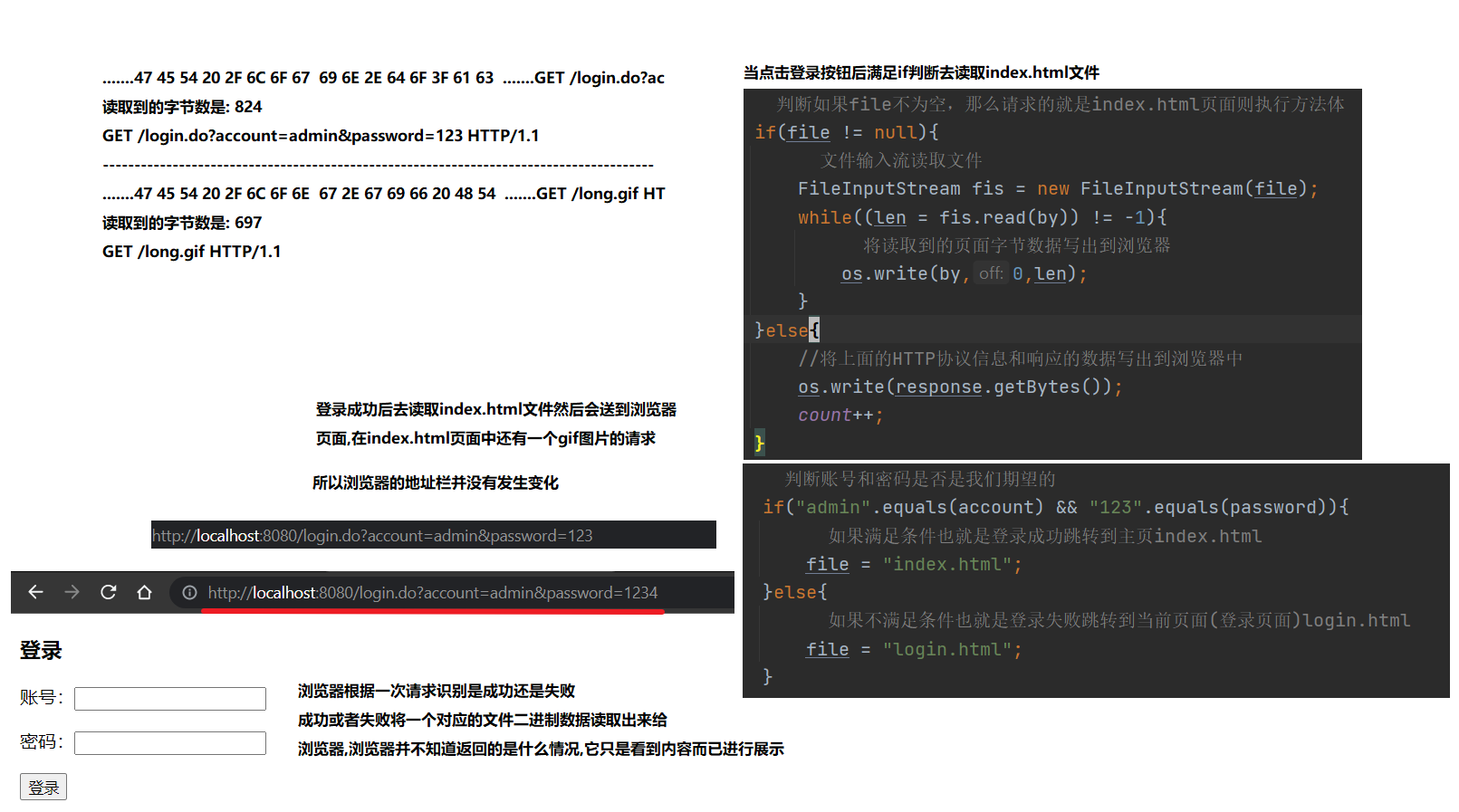
当我们点击登录,登录成功后地址栏不会发生变化这种情况是不合适的,因为当我们点击刷新的时候都是在请求那个 Uri。
清空控制台。
<img src="https://raw.githubusercontent.com/PigPigLetsGo/imeages/master/202312311215781.png" alt="image-20230519221531747" style="zoom: 50%;" />
刷新请求页面:
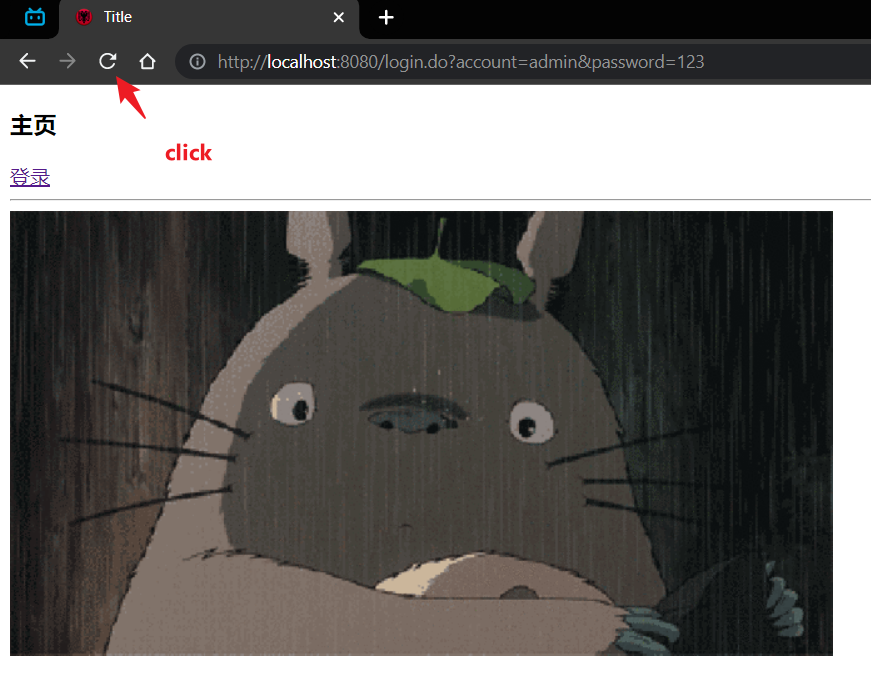
查看控制台请求信息:
.......47 45 54 20 2F 6C 6F 67 69 6E 2E 64 6F 3F 61 63 .......GET /login.do?ac | |
读取到的字节数是: 850 | |
GET /login.do?account=admin&password=123 HTTP/1.1 |
.......47 45 54 20 2F 6C 6F 6E 67 2E 67 69 66 20 48 54 .......GET /long.gif HT | |
读取到的字节数是: 697 | |
GET /long.gif HTTP/1.1 |
.......47 45 54 20 2F 66 61 76 69 63 6F 6E 2E 69 63 6F .......GET /favicon.ico | |
读取到的字节数是: 700 | |
GET /favicon.ico HTTP/1.1 |
# HTTP 响应代码⚡️
302 Found
HTTP 302 Found 重定向状态码表名请求的资源被暂时的移动到了由 Location 头部指定的 URL 上。浏览器会重定向到这个 URL,但是搜索引擎不会对该资源的链接进行更新 (In SEO-speak,it is said that the link-juic is not sent to the new URL)。
状态:
302 Found
Location
Location 首部指定的是需要将页面重定向至的地址,一般在响应码为 3xx 的响应中才会有意义。
发送新请求,获取 Location 指向的新页面所采用的方法与初始请求使用的方法以及重定向的类型相关;
- 303 (See Also) 始终引致请求使用
GET方法,而 307 (Temporary Redirect) 和 308 (Permanent Redirect) 则不转变初始请求中的所使用的方法; - 301 (Permanent Redirect) 和 302 (Found) 在大多数情况下不会转变初始请求中的方法,不过一些比较早的用户代理可能会引发方法的变更 (所以你基本上不知道这一点)。
状态码为上述之一的所有相应都会带有一个 Location 首部。
除了重定向相应之外,状态码为 201 (Created) 的消息也会带有 Location 首部,它指向的是新创建的资源的地址。
语法:
Location: <url>
修改登录请求 login.do 的处理方式:
当 if 判断登录成功后响应一个 302 Found 的状态码 (重定向) 让浏览器主动申请一次请求 到 index.html 页面
// 判断请求路径是否为 /login.do | |
}else if(request.getUri().equals("/login.do")){ | |
// 通过 key 获取 value 获取账号 | |
String account = request.getParamMap().get("account"); | |
// 通过 key 获取 value 获取密码 | |
String password = request.getParamMap().get("password"); | |
// 协议 / 版本 状态码 状态 空格换行 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求类型:文本 /html 解析 html 标签代码 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n"+ | |
// 空格换行 | |
"\r\n"; | |
// 判断账号和密码是否是我们期望的 | |
if("admin".equals(account) && "123".equals(password)){ | |
// 如果满足条件也就是登录成功跳转到主页 index.html | |
// 重定向状态码 | |
response = "HTTP/1.1 302 Found\r\n"+ | |
// 成功,重定向到,index.html | |
// 让浏览器主动申请一次页面 | |
"Location: index.html\r\n"+ | |
// 空格换行 | |
"\r\n"; | |
}else{ | |
// 如果不满足条件也就是登录失败跳转到当前页面 (登录页面) login.html | |
// 登录失败转发到 login.html 页面 | |
file = "login.html";// 服务器内部读取一个文件,返回给浏览器 | |
} | |
} |
效果:
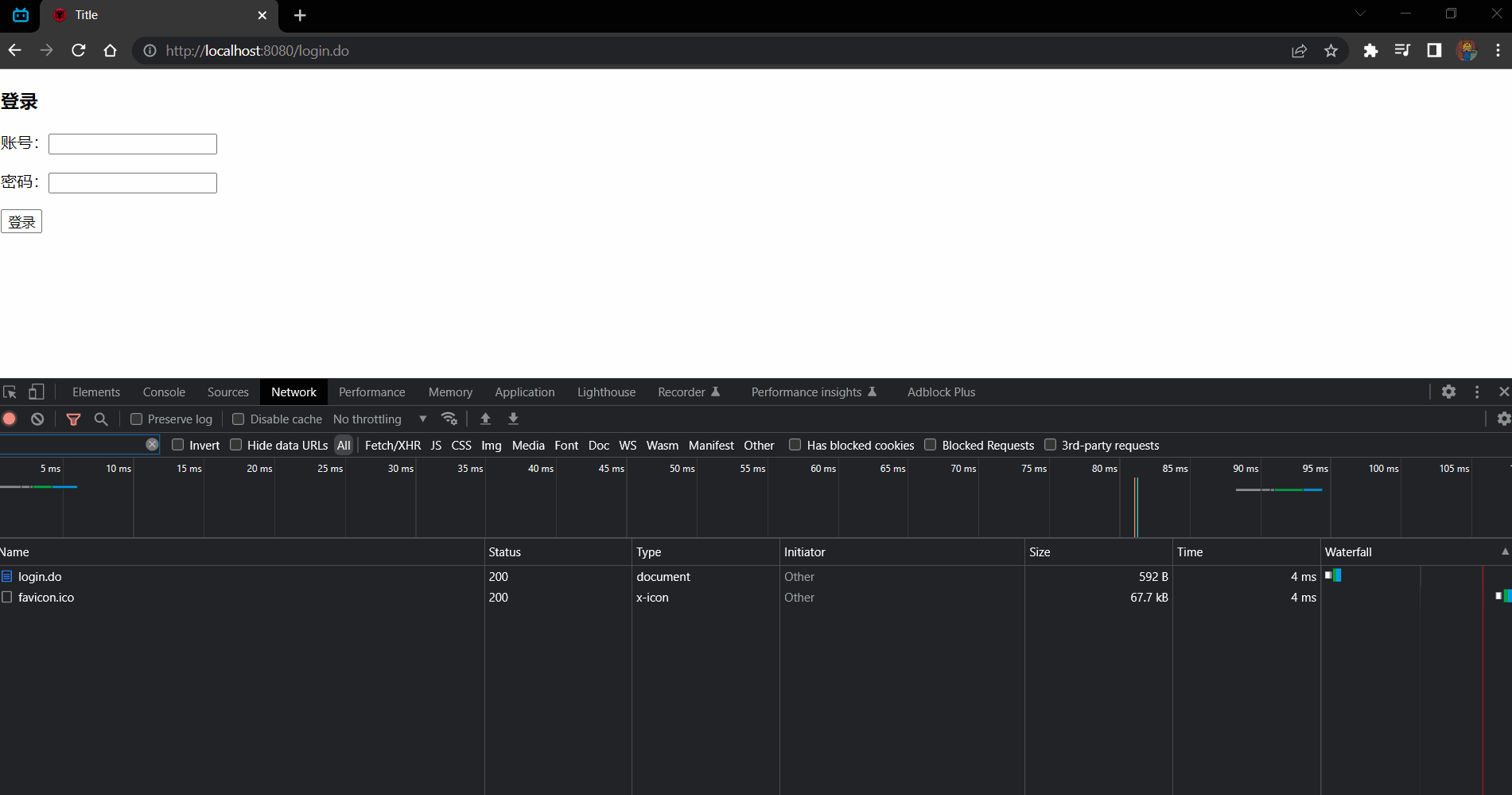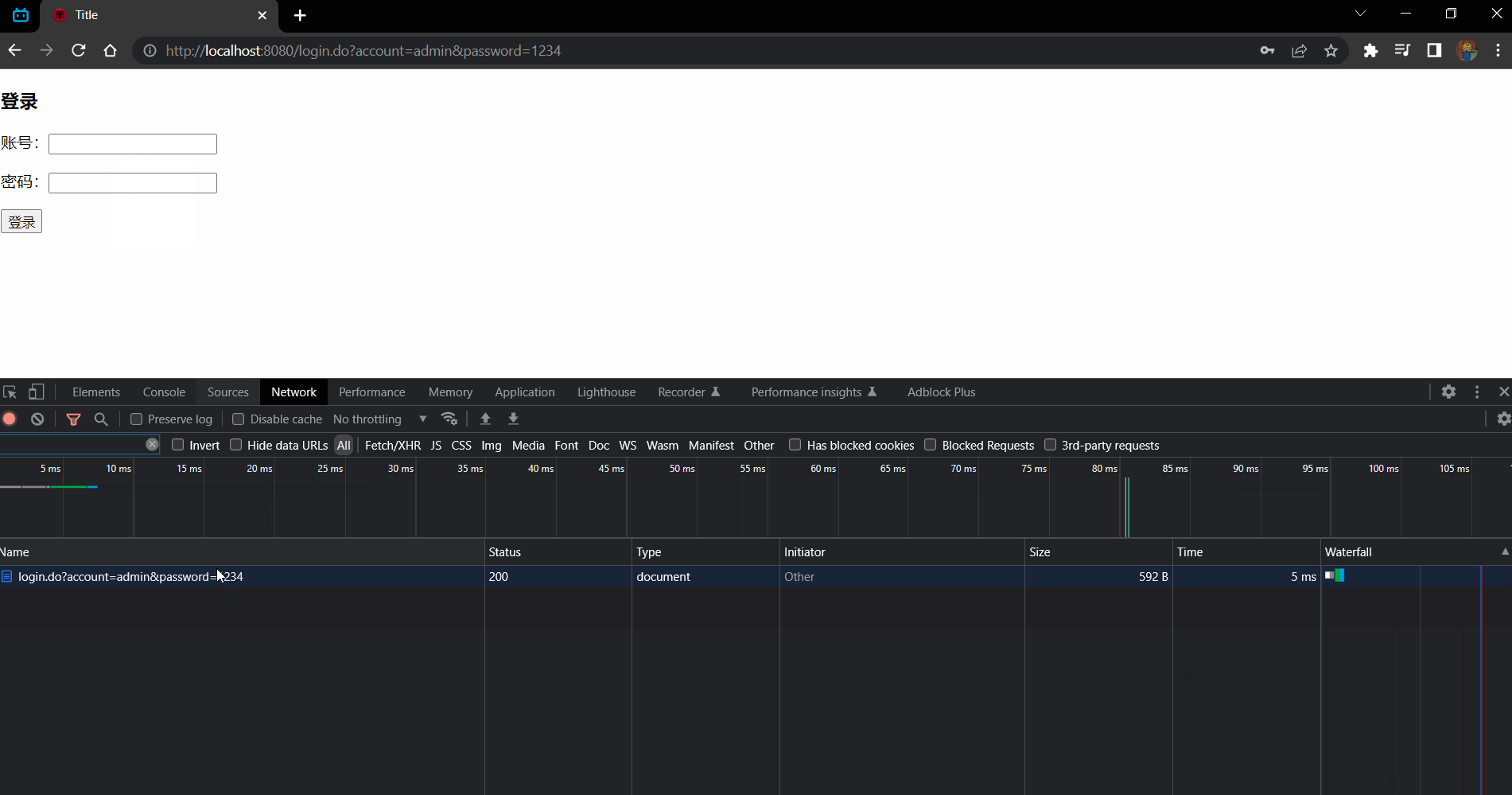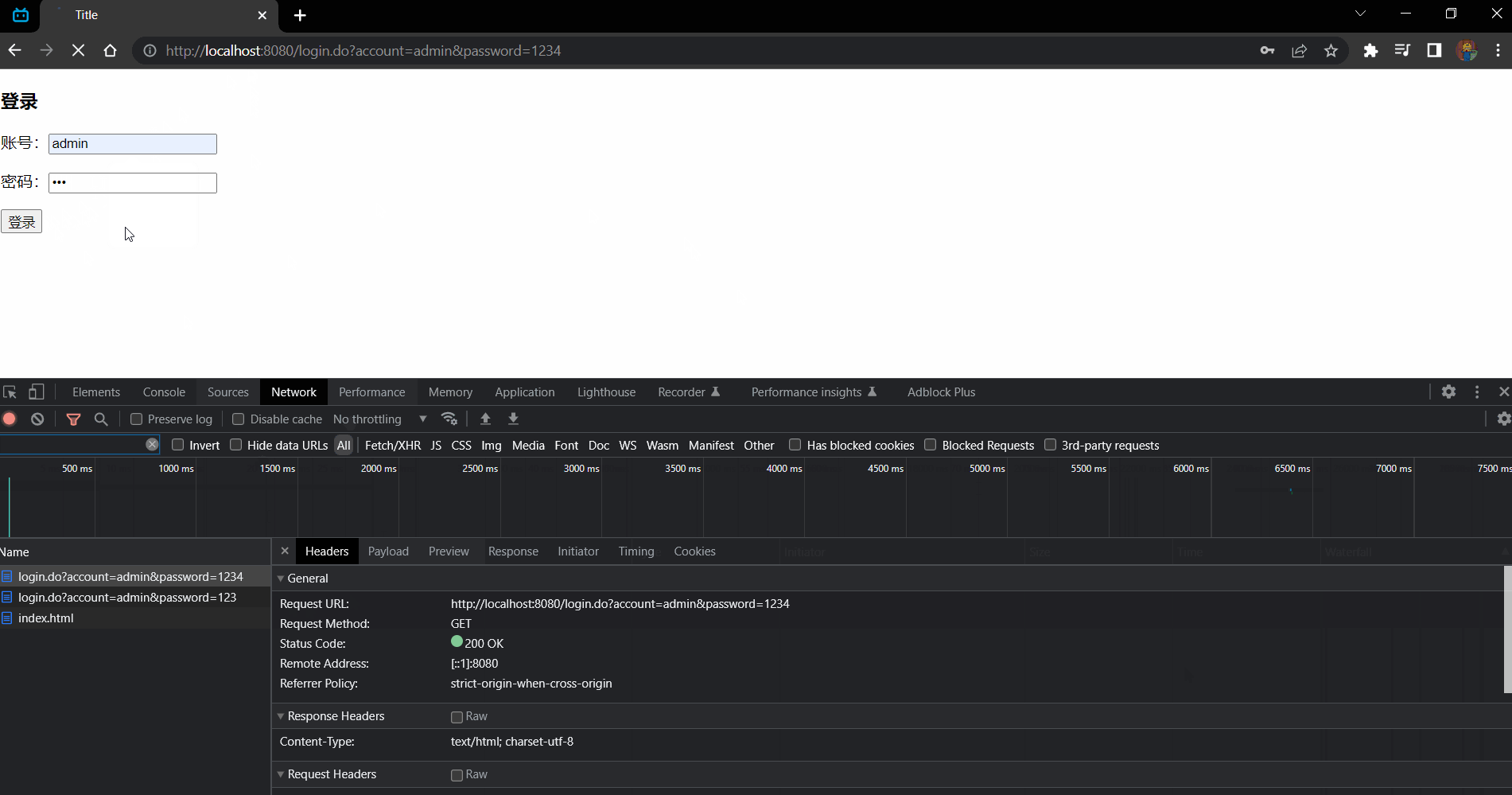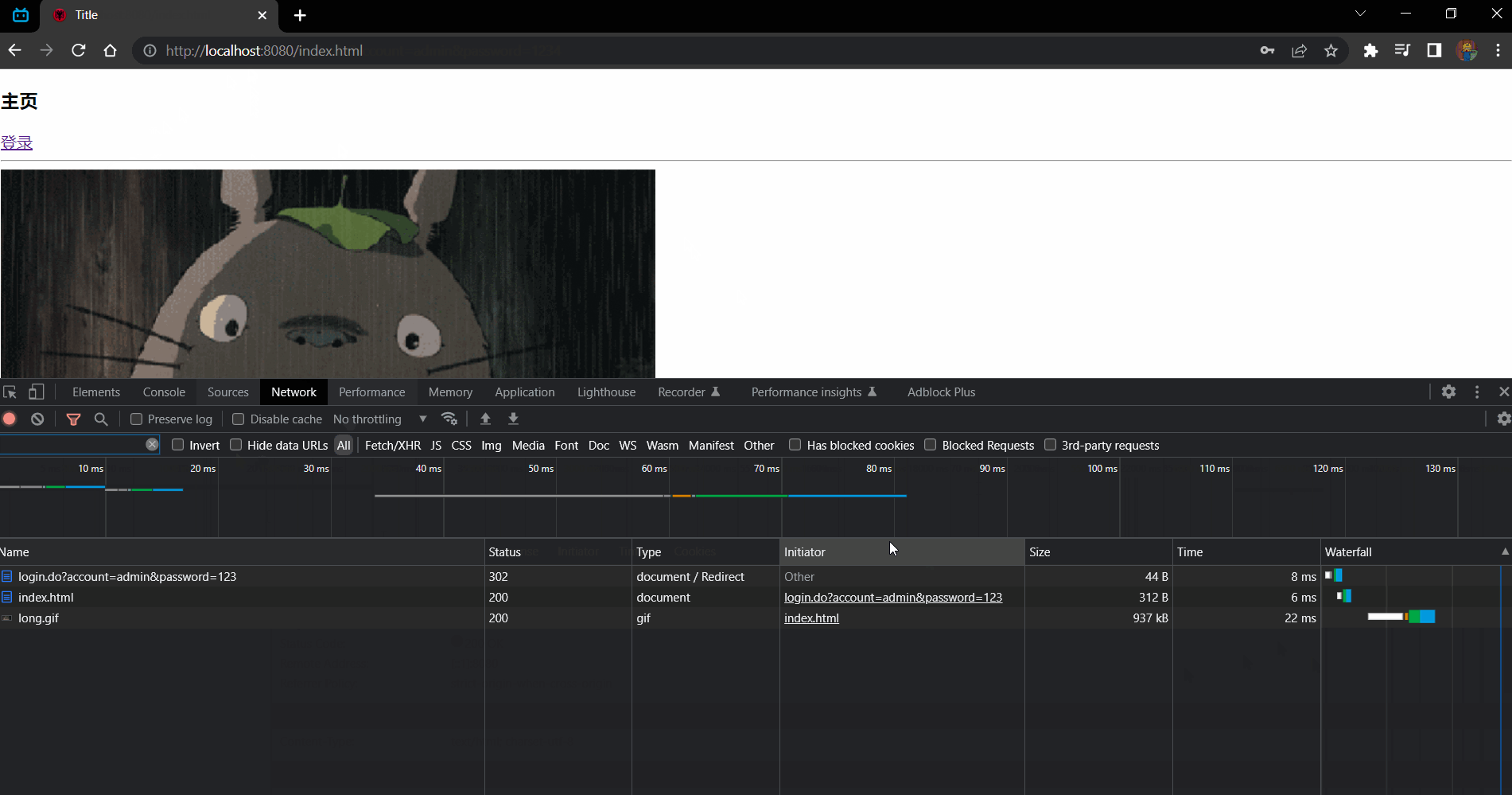
请求的信息:
请求 /login.do 到 login.html 页面中,第一次请求账号和密码都是 null 所以走 else 将 file 赋值为 login.html
.......47 45 54 20 2F 6C 6F 67 69 6E 2E 64 6F 20 48 54 .......GET /login.do HT | |
读取到的字节数是: 773 | |
GET /login.do HTTP/1.1 |
.......47 45 54 20 2F 66 61 76 69 63 6F 6E 2E 69 63 6F .......GET /favicon.ico | |
读取到的字节数是: 673 | |
GET /favicon.ico HTTP/1.1 |
登录错误的请求读取 login.html 页面二进制数据展示页面:此时地址栏不发生改变,服务器处理

.......47 45 54 20 2F 6C 6F 67 69 6E 2E 64 6F 3F 61 63 .......GET /login.do?ac | |
读取到的字节数是: 823 | |
GET /login.do?account=admin&password=1234 HTTP/1.1 |
登录成功请求 HTTP 协议状态码为 302 Found 重定向到 Location:index.html 浏览器主动申请 index.html 页面
.......47 45 54 20 2F 6C 6F 67 69 6E 2E 64 6F 3F 61 63 .......GET /login.do?ac | |
读取到的字节数是: 850 | |
GET /login.do?account=admin&password=123 HTTP/1.1 |
.......47 45 54 20 2F 69 6E 64 65 78 2E 68 74 6D 6C 20 .......GET /index.html | |
读取到的字节数是: 825 | |
GET /index.html HTTP/1.1 |
.......47 45 54 20 2F 6C 6F 6E 67 2E 67 69 66 20 48 54 .......GET /long.gif HT | |
读取到的字节数是: 672 | |
GET /long.gif HTTP/1.1 |
# 使用 POST 方式提交表单☔️
将 login.html 页面的请求方式改为 method = "post"
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<title>Title</title> | |
</head> | |
<body> | |
<h3>登录</h3> | |
<!-- 假设 账号:123 密码:admin , 允许登录 一般选择.do .action--> | |
<!-- 我们要避开程序中已经写过的后缀名写法 --> | |
<form action="login.do" method="post"> | |
<p>账号:<input type="text" name="account"></p> | |
<p>密码:<input type="password" name="password"></p> | |
<p><input type="submit" value="登录"></p> | |
</form> | |
</body> | |
</html> |
查看登录后的请求结果:
登录后地址栏不会显示账号和密码,账号密码在请求体中显示
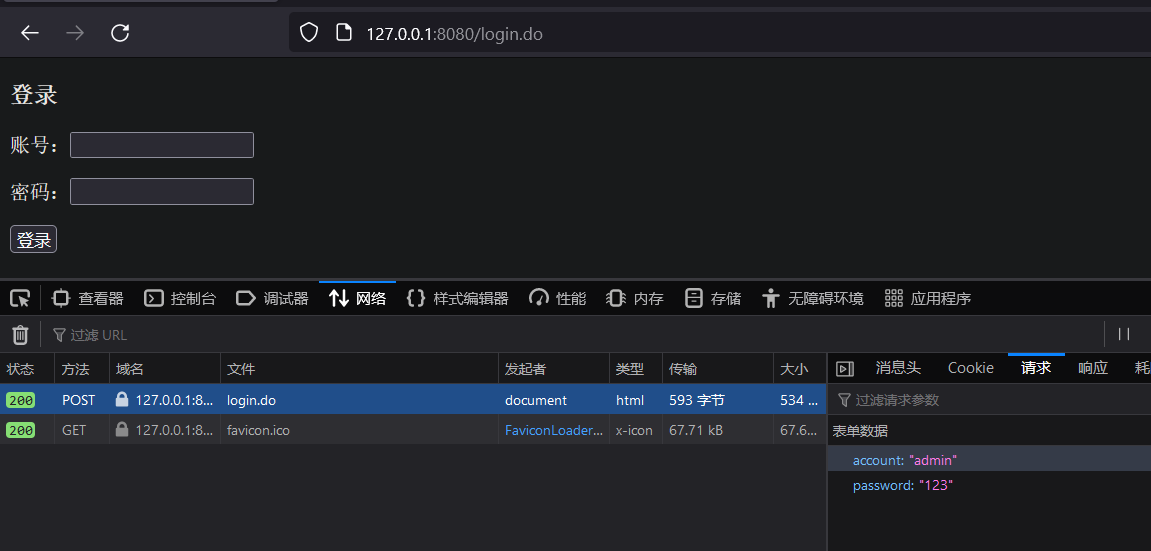
在最后一行 (请求体) 中显示 账号和密码信息:
.......50 4F 53 54 20 2F 6C 6F 67 69 6E 2E 64 6F 20 48 .......POST /login.do H | |
.......54 54 50 2F 31 2E 31 0D 0A 48 6F 73 74 3A 20 31 .......TTP/1.1..Host: 1 | |
.......32 37 2E 30 2E 30 2E 31 3A 38 30 38 30 0D 0A 55 .......27.0.0.1:8080..U | |
.......73 65 72 2D 41 67 65 6E 74 3A 20 4D 6F 7A 69 6C .......ser-Agent: Mozil | |
.......6C 61 2F 35 2E 30 20 28 57 69 6E 64 6F 77 73 20 .......la/5.0 (Windows | |
.......4E 54 20 31 30 2E 30 3B 20 57 69 6E 36 34 3B 20 .......NT 10.0; Win64; | |
.......78 36 34 3B 20 72 76 3A 31 30 39 2E 30 29 20 47 .......x64; rv:109.0) G | |
.......65 63 6B 6F 2F 32 30 31 30 30 31 30 31 20 46 69 .......ecko/20100101 Fi | |
.......72 65 66 6F 78 2F 31 31 33 2E 30 0D 0A 41 63 63 .......refox/113.0..Acc | |
.......65 70 74 3A 20 74 65 78 74 2F 68 74 6D 6C 2C 61 .......ept: text/html,a | |
.......70 70 6C 69 63 61 74 69 6F 6E 2F 78 68 74 6D 6C .......pplication/xhtml | |
.......2B 78 6D 6C 2C 61 70 70 6C 69 63 61 74 69 6F 6E .......+xml,application | |
.......2F 78 6D 6C 3B 71 3D 30 2E 39 2C 69 6D 61 67 65 ......./xml;q=0.9,image | |
.......2F 61 76 69 66 2C 69 6D 61 67 65 2F 77 65 62 70 ......./avif,image/webp | |
.......2C 2A 2F 2A 3B 71 3D 30 2E 38 0D 0A 41 63 63 65 .......,*/*;q=0.8..Acce | |
.......70 74 2D 4C 61 6E 67 75 61 67 65 3A 20 7A 68 2D .......pt-Language: zh- | |
.......43 4E 2C 7A 68 3B 71 3D 30 2E 38 2C 7A 68 2D 54 .......CN,zh;q=0.8,zh-T | |
.......57 3B 71 3D 30 2E 37 2C 7A 68 2D 48 4B 3B 71 3D .......W;q=0.7,zh-HK;q= | |
.......30 2E 35 2C 65 6E 2D 55 53 3B 71 3D 30 2E 33 2C .......0.5,en-US;q=0.3, | |
.......65 6E 3B 71 3D 30 2E 32 0D 0A 41 63 63 65 70 74 .......en;q=0.2..Accept | |
.......2D 45 6E 63 6F 64 69 6E 67 3A 20 67 7A 69 70 2C .......-Encoding: gzip, | |
.......20 64 65 66 6C 61 74 65 2C 20 62 72 0D 0A 43 6F ....... deflate, br..Co | |
.......6E 74 65 6E 74 2D 54 79 70 65 3A 20 61 70 70 6C .......ntent-Type: appl | |
.......69 63 61 74 69 6F 6E 2F 78 2D 77 77 77 2D 66 6F .......ication/x-www-fo | |
.......72 6D 2D 75 72 6C 65 6E 63 6F 64 65 64 0D 0A 43 .......rm-urlencoded..C | |
.......6F 6E 74 65 6E 74 2D 4C 65 6E 67 74 68 3A 20 32 .......ontent-Length: 2 | |
.......36 0D 0A 4F 72 69 67 69 6E 3A 20 68 74 74 70 3A .......6..Origin: http: | |
.......2F 2F 31 32 37 2E 30 2E 30 2E 31 3A 38 30 38 30 .......//127.0.0.1:8080 | |
.......0D 0A 43 6F 6E 6E 65 63 74 69 6F 6E 3A 20 6B 65 .........Connection: ke | |
.......65 70 2D 61 6C 69 76 65 0D 0A 52 65 66 65 72 65 .......ep-alive..Refere | |
.......72 3A 20 68 74 74 70 3A 2F 2F 31 32 37 2E 30 2E .......r: http://127.0. | |
.......30 2E 31 3A 38 30 38 30 2F 6C 6F 67 69 6E 2E 64 .......0.1:8080/login.d | |
.......6F 0D 0A 55 70 67 72 61 64 65 2D 49 6E 73 65 63 .......o..Upgrade-Insec | |
.......75 72 65 2D 52 65 71 75 65 73 74 73 3A 20 31 0D .......ure-Requests: 1. | |
.......0A 53 65 63 2D 46 65 74 63 68 2D 44 65 73 74 3A ........Sec-Fetch-Dest: | |
.......20 64 6F 63 75 6D 65 6E 74 0D 0A 53 65 63 2D 46 ....... document..Sec-F | |
.......65 74 63 68 2D 4D 6F 64 65 3A 20 6E 61 76 69 67 .......etch-Mode: navig | |
.......61 74 65 0D 0A 53 65 63 2D 46 65 74 63 68 2D 53 .......ate..Sec-Fetch-S | |
.......69 74 65 3A 20 73 61 6D 65 2D 6F 72 69 67 69 6E .......ite: same-origin | |
.......0D 0A 53 65 63 2D 46 65 74 63 68 2D 55 73 65 72 .........Sec-Fetch-User | |
.......3A 20 3F 31 0D 0A 50 72 61 67 6D 61 3A 20 6E 6F .......: ?1..Pragma: no | |
.......2D 63 61 63 68 65 0D 0A 43 61 63 68 65 2D 43 6F .......-cache..Cache-Co | |
.......6E 74 72 6F 6C 3A 20 6E 6F 2D 63 61 63 68 65 0D .......ntrol: no-cache. | |
.......0A 0D 0A 61 63 63 6F 75 6E 74 3D 61 64 6D 69 6E ..........account=admin | |
.......26 70 61 73 73 77 6F 72 64 3D 31 32 33 .......&password=123 | |
读取到的字节数是: 717 | |
POST /login.do HTTP/1.1 | |
Host: 127.0.0.1:8080 | |
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0 | |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 | |
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 | |
Accept-Encoding: gzip, deflate, br | |
Content-Type: application/x-www-form-urlencoded | |
Content-Length: 26 | |
Origin: http://127.0.0.1:8080 | |
Connection: keep-alive | |
Referer: http://127.0.0.1:8080/login.do | |
Upgrade-Insecure-Requests: 1 | |
Sec-Fetch-Dest: document | |
Sec-Fetch-Mode: navigate | |
Sec-Fetch-Site: same-origin | |
Sec-Fetch-User: ?1 | |
Pragma: no-cache | |
Cache-Control: no-cache | |
account=admin&password=123 |
登录成功后没有重定向页面是因为并没有解析到账号和密码原来的解析方式是 get 方式的 post 方式解析不到。
思路:
无论有没有请求体,请求头与请求体之间都要带有一个 "\r\n\r\n" ,先通过 indexOf 获取到 "\r\n\r\n" 的下标位置,然后通过 substring (index1+4) 获取 "\r\n\r\n",之后的字符串,再判断字符串中是否包含 "=",因为 无论有没有请求体,请求头与请求体之间都要带有一个 "\r\n\r\n",所以在请求 index.html 的时候没有 account=admin&password=123,因此后面的代码操作就会报错 ArrayIndexOutOfBoundsException,所以要判断"="来判断后面是否有 account=admin&password=123 数据,然后通过"&"将"\r\n\r\n"之后的字符串进行切割分为两段,account=admin 和 password=123,循环切割后的数据,通过 indexOf ("=") 获取"="的下标位置,在通过 request.getParamMap ().put (i.substring (0,index1),i.substring (index1+1));,从 0 开始到"="的前位置的字符串也就是 account 和从"=" 下标位置 + 1 的位置开始到末尾也就是 admin,以 key,value 的形式存储到 Map 集合中。

编写解析方法:
/** | |
* 解析请求 | |
* @param msg | |
* @return | |
*/ | |
private static Request parseRequest(String msg){ | |
Request request = new Request(); | |
String[] split = msg.split("\r\n"); | |
// 解析第一行 | |
//GET /favicon.ico HTTP/1.1 | |
String[] split0 = split[0].split(" "); | |
request.setMethod(split0[0]);//method : GET | |
// 判断请求路径中是否包含?号 | |
if(split0[1].contains("?")){ | |
///login.do?account=admin&password=123, 以?号进行切割 | |
String[] split1 = split0[1].split("[?]"); | |
// /login.do | |
request.setUri(split1[0]); | |
// account=admin&password=123 | |
String[] split2 = split1[1].split("[&]"); | |
for(String i:split2){ | |
int idx = i.indexOf("="); | |
request.getParamMap().put(i.substring(0,idx),i.substring(idx+1)); | |
} | |
}else{ | |
request.setUri(split0[1]);//uri : / 或者 /favicon.ico | |
// 获取请求头与请求体之间的位置 | |
int idx1 = msg.indexOf("\r\n\r\n"); | |
// 截取请求头与请求体之后字符串 m = account=admin&password=123 | |
String m = msg.substring(idx1+4); | |
// 判断 m 截取的字符串中是否包含 = , 因为即使没有请求体也会有它们之间的空格换行空格换行存在,判断 = 是判断是否存在后面 account=admin&password=123 的数据 | |
if(m.contains("=")){ | |
// 判断是否有请求头与请求体之间的空格 | |
if(idx1 != -1){ | |
// 将 account=admin&password=123 之间以 & amp; 进行切割 | |
String[] spli = m.split("[&]"); | |
// 循环切割后的数据 | |
for(String i:spli){ | |
// 获取 = 的位置下标 | |
int index1 = i.indexOf("="); | |
// 以键值对的形式获取 = 分隔开的数据存储到 map 集合中 | |
request.getParamMap().put(i.substring(0,index1),i.substring(index1+1)); | |
} | |
} | |
} | |
} | |
return request; | |
} |
完整代码:MyHttpServer
package web; | |
import java.io.FileInputStream; | |
import java.io.IOException; | |
import java.io.InputStream; | |
import java.io.OutputStream; | |
import java.net.ServerSocket; | |
import java.net.Socket; | |
import java.util.concurrent.ExecutorService; | |
import java.util.concurrent.Executors; | |
public class MyHttpServer { | |
private static int count = 1; | |
private static final char[] arr = {'0','1','2','3','4','5','6','7','8','9','A', | |
'B','C','D','E','F'}; | |
public static void main(String... args) { | |
try { | |
ServerSocket serverSocket = new ServerSocket(8080); | |
System.out.println("服务器已经启动,监听端口为:8080 ..."); | |
ExecutorService executorService = Executors.newCachedThreadPool(); | |
while (true) { | |
Socket socket = serverSocket.accept(); | |
executorService.execute(() -> { | |
InputStream is = null; | |
OutputStream os = null; | |
try { | |
System.out.println(socket); | |
is = socket.getInputStream(); | |
os = socket.getOutputStream(); | |
byte[] by = new byte[1024 * 1024]; | |
int len = is.read(by); | |
if (len != -1) { | |
String hexMsg = bytesArr2HexStr(by,len); | |
System.out.println(hexMsg); | |
System.out.println("读取到的字节数是: " + len); | |
String msg = new String(by, 0, len); | |
System.out.println(msg); | |
Request request = parseRequest(msg); | |
// 响应给浏览器需要使用 Http 协议 | |
String body = "<h1>" + count + "</h1>"+"\r\n"+"text/plain : plain plain text does not parse html tags"; | |
//http 协议 / 版本 状态码 状态 后面的格式必须是 \r\n 不能乱写否则报错 | |
String response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本的内容大小 | |
"Content-Length: " + body.getBytes().length + "\r\n" + | |
// 告诉浏览器文本类型:普通文本 /plain 不解析任何代码语义 | |
"Content-Type: text/plain; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n" +// 回车换行,否则后面的数据接收不到 | |
//body 响应浏览器内容 | |
// 要返回给浏览器的文本正文 (内容) | |
body + "\r\n";// 回车换行,否则后面的数据接收不到 | |
String file = null; | |
// 判断请求的是否是 index.html 页面 | |
if(request.getUri().equals("/index.html")){ | |
//file 赋值为 index.html 文件的路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:文本 /html html 页面,解析标签 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
// 判断请求是否为 favicon.icon | |
}else if(request.getUri().equals("/favicon.ico")){ | |
// 将 file 赋值为 icon 的图标路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
/** | |
* 如果读取 index 文件则重新赋值 response 变量将里面的 body 内容去掉还有读取大小也没必须设置了 | |
* 必须设置 HTTP 协议信息 | |
*/ | |
response = "HTTP/1.1 200 OK\r\n" +//HTTP1.1 协议 状态码:200 正确 回车换行 | |
// 告诉浏览器文本类型:图片类型 /x-icon 设置字符集 | |
"Content-Type: image/x-icon; charset-utf- 8\r\n" +// 内容类型是普通文本 回车换行 字符集 | |
// 固定写法,必须要写的空格换行 (必须要写一个空行) | |
"\r\n"; | |
// 判断请求的文件后缀名是否为.gif | |
}else if(request.getUri().endsWith(".gif")){ | |
//file 赋值为 gif 图片的路径 | |
// 获取请求的 uri 并截取丢弃前面的 / | |
file = request.getUri().substring(1); | |
//HTTP 请求 / 版本 状态码 状态 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求的类型: 图片 /gif 格式 设置字符集 | |
"Content-Type: image/gif; charset-utf-8\r\n"+ | |
"\r\n"; | |
}else if(request.getUri().endsWith(".html")){ | |
//file 赋值为请求的名称后缀名为 html 的文件名称去掉前面的 / | |
file = request.getUri().substring(1); | |
// 设置 HTTP 协议 | |
// 协议 / 版本 状态码 状态 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求的类型:文本 /html 解析 html 标签代码 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n"+ | |
// 必须设置换行空格 | |
"\r\n"; | |
// 判断请求路径是否为 /login.do | |
}else if(request.getUri().equals("/login.do")){ | |
// 通过 key 获取 value 获取账号 | |
String account = request.getParamMap().get("account"); | |
// 通过 key 获取 value 获取密码 | |
String password = request.getParamMap().get("password"); | |
// 协议 / 版本 状态码 状态 空格换行 | |
response = "HTTP/1.1 200 OK\r\n"+ | |
// 告诉浏览器请求类型:文本 /html 解析 html 标签代码 设置字符集 | |
"Content-Type: text/html; charset-utf-8\r\n"+ | |
// 空格换行 | |
"\r\n"; | |
// 判断账号和密码是否是我们期望的 | |
if("admin".equals(account) && "123".equals(password)){ | |
// 如果满足条件也就是登录成功跳转到主页 index.html | |
// 重定向状态码 | |
response = "HTTP/1.1 302 Found\r\n"+ | |
// 成功,重定向到,index.html | |
// 让浏览器主动申请一次页面 | |
"Location: index.html\r\n"+ | |
// 空格换行 | |
"\r\n"; | |
}else{ | |
// 如果不满足条件也就是登录失败跳转到当前页面 (登录页面) login.html | |
// 登录失败转发到 login.html 页面 | |
file = "login.html";// 服务器内部读取一个文件,返回给浏览器 | |
} | |
} | |
// 将 HTTP 协议信息写出到浏览器中 (响应回去) | |
os.write(response.getBytes()); | |
// 判断如果 file 不为空,那么请求的就是 index.html 页面则执行方法体 | |
if(file != null){ | |
// 文件输入流读取文件 | |
FileInputStream fis = new FileInputStream(file); | |
while((len = fis.read(by)) != -1){ | |
// 将读取到的页面字节数据写出到浏览器 | |
os.write(by,0,len); | |
} | |
}else{ | |
// 将上面的 HTTP 协议信息和响应的数据写出到浏览器中 | |
os.write(response.getBytes()); | |
count++; | |
} | |
} else { | |
System.out.println("没有读取到数据"); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
}finally{ | |
try{ | |
if(os != null){ | |
os.flush();// 将数据刷出 | |
} | |
if(socket != null){ | |
// 上一段对话已经结束进行下一段对话 | |
socket.shutdownOutput(); | |
socket.close();// 关闭套接字资源 | |
} | |
}catch(IOException e){ | |
e.printStackTrace(); | |
} | |
} | |
}); | |
} | |
} catch (IOException e) { | |
e.printStackTrace(); | |
} | |
} | |
/** | |
* 解析请求 | |
* @param msg | |
* @return | |
*/ | |
private static Request parseRequest(String msg){ | |
Request request = new Request(); | |
String[] split = msg.split("\r\n"); | |
// 解析第一行 | |
//GET /favicon.ico HTTP/1.1 | |
String[] split0 = split[0].split(" "); | |
request.setMethod(split0[0]);//method : GET | |
// 判断请求路径中是否包含?号 | |
if(split0[1].contains("?")){ | |
///login.do?account=admin&password=123, 以?号进行切割 | |
String[] split1 = split0[1].split("[?]"); | |
// /login.do | |
request.setUri(split1[0]); | |
// account=admin&password=123 | |
String[] split2 = split1[1].split("[&]"); | |
for(String i:split2){ | |
int idx = i.indexOf("="); | |
request.getParamMap().put(i.substring(0,idx),i.substring(idx+1)); | |
} | |
}else{ | |
request.setUri(split0[1]);//uri : / 或者 /favicon.ico | |
// 获取请求头与请求体之间的位置 | |
int idx1 = msg.indexOf("\r\n\r\n"); | |
// 截取请求头与请求体之后字符串 m = account=admin&password=123 | |
String m = msg.substring(idx1+4); | |
// 判断 m 截取的字符串中是否包含 = , 因为即使没有请求体也会有它们之间的空格换行空格换行存在,判断 = 是判断是否存在后面 account=admin&password=123 的数据 | |
if(m.contains("=")){ | |
// 判断是否有请求头与请求体之间的空格 | |
if(idx1 != -1){ | |
// 将 account=admin&password=123 之间以 & amp; 进行切割 | |
String[] spli = m.split("[&]"); | |
// 循环切割后的数据 | |
for(String i:spli){ | |
// 获取 = 的位置下标 | |
int index1 = i.indexOf("="); | |
// 以键值对的形式获取 = 分隔开的数据存储到 map 集合中 | |
request.getParamMap().put(i.substring(0,index1),i.substring(index1+1)); | |
} | |
} | |
} | |
} | |
return request; | |
} | |
/** | |
* 将传入的整个二进制数据全部转换为十六进制的数据 | |
* @param by 接收字节数组 | |
* @param len 数据的大小 | |
* @return | |
*/ | |
private static String bytesArr2HexStr(byte[] by,int len){ | |
// 使用 StringBuffer 来接收转换后的十六进制数据 | |
StringBuffer sb = new StringBuffer(); | |
StringBuffer sbLeft = new StringBuffer(); | |
StringBuffer fenge = new StringBuffer(); | |
StringBuffer sbRight = new StringBuffer(); | |
for(int i = 0;i < len;i ++){ | |
// 每追加一个十六进制数据就拼接一个空格 | |
sbLeft.append(byte2Hex(by[i])+" "); | |
// 判断可见字符的范围 | |
if(by[i] >= 0x20 && by[i] <= 0x7e){ | |
// 将二进制数据转换为 char 字符拼接到 StringBuffer 中 | |
sbRight.append((char)by[i]); | |
}else{ | |
// 如果不在可见范围内则追加一个。即可 | |
sbRight.append("."); | |
} | |
// 判断每第 8 个多追加一个空格 i+1 避免第一个就满足条件 | |
if((i + 1) % 8 == 0) | |
sbLeft.append(" "); | |
// 判断每 16 个进行换行空格 i+1 避免第一个就满足条件 | |
if(i % 16 == 0){ | |
fenge.append("......."); | |
} | |
if((i + 1) % 16 == 0){ | |
sb.append(fenge).append(sbLeft).append(fenge).append(sbRight).append("\r\n"); | |
sbLeft = new StringBuffer(); | |
sbRight = new StringBuffer(); | |
fenge = new StringBuffer(); | |
} | |
} | |
sb.append(fenge).append(sbLeft).append(" ").append(fenge).append(sbRight).append("\r\n"); | |
// 将 StringBuffer 转换为字符串并返回 | |
return sb.toString(); | |
} | |
/** | |
* 3a -> "3A" | |
* a5 -> "A5" | |
* @param bt | |
* @return | |
*/ | |
private static String byte2Hex(byte bt){ | |
/** | |
* 00111111 | |
* & | |
* 00001111 | |
* 操作: | |
* 00001111 | |
* 结果:15 对应结果: F | |
*/ | |
int lo = bt & 0b00001111; | |
/** | |
* 00111111 | |
* & | |
* 11110000 | |
* 操作: | |
* 00110000 | |
* 结果: | |
* 48 | |
* >> 4 | |
* 结果: | |
* 24 12 6 3 | |
* 最终结果: | |
* 3 对应结果 3 | |
*/ | |
int hi = (bt & 0b11110000) >> 4; | |
char clo = arr[lo]; | |
char chi = arr[hi]; | |
return chi + "" + clo; | |
} | |
} |