# 多线程下载器
项目简介:
多线程下载器小项目的主要目的是让学完 java se 的同学对多线程知识做一些运用,该项目应用的知识点包括下面内容:
- RandomAccessFile 类的运用
- HttpURLConnection 类的运用
- 线程池的使用
- 原子类 LongAdder 的运用
- CountDownLatch 类的运用
- ScheduledExecutorService 类的运用
通过学习本项目,有利于加深对多线程知识的理解
环境:
工具:Idea
Jdk:8
# 1 文件下载
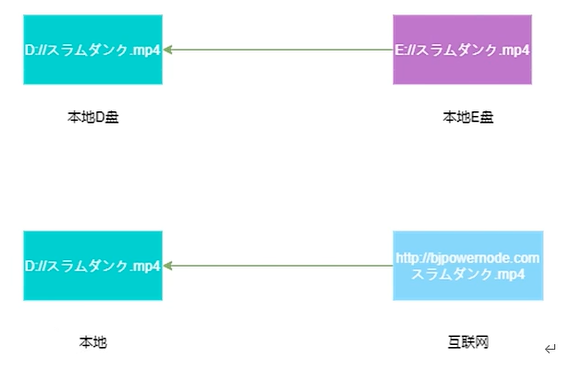
从互联网下载文件有点类似于我们将本地某个文件复制到另一个目录下,也会利用 I/O 流进行操作。对于互联网下载,还需要将本地和下载文件所在的服务器建立连接。
# 2 文件下载器的基础代码
# 2.1 HttpURLConnection
从互联网下载文件的话,需要与文件所在的服务器建立连接,这里可以使用 jdk 提供的 java.net.HttpURLConnection 类来帮助我们完成这个操作。jdk11 中有提供 java.net.http.HttpClient 类来替代 HttpURLConnection,由于现在使用的是 jdk8,因此先不用 jdk11 中的 HttpClient。除此之外还有一些其它第三方提供类可以执行类似的操作,这里就不多赘述了。
# 2.2 用户标识
我们通过浏览器访问某个网站的时候,会将当前浏览器的版本,操作系统版本等信息的标识发送到网站所在的服务器中。当用程序代码去访问网站时,需要将这个标识发送过去。下面的标识大家可以拷贝到程序中。
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1
代码:
由于我们要将下载的文件先存储到同一个位置,但是这个路径一直编写很麻烦所以就创建一个常量类来记录一下路径
// 常量类 | |
public class Constant { | |
public static final String PATH = "E://下载器演示目录/"; | |
} |
HttpUtils:通过 HttpURLConnection 来获取下载地址的连接的 getHttpURLConnection 方法,和获取文件名称的 getHttpFileName 方法
// Http 相关工具类 | |
public class HttpUtils { | |
/** | |
* 获取 HttpURLConnection 链接对象 | |
* @param url 文件下载地址 | |
* @return | |
*/ | |
public static HttpURLConnection getHttpURLConnection(String url) { | |
URL urlOne = null; | |
HttpURLConnection httpURLConnection = null; | |
try { | |
// 创建 URL 对象 构造参数为 想要访问的资源地址 | |
urlOne = new URL(url); | |
// 通过 openConnection 返回对象并进行强转为 HttpURLConnection 对象 | |
httpURLConnection = (HttpURLConnection) urlOne.openConnection(); | |
} catch (Exception e) { | |
throw new RuntimeException(e); | |
} | |
// 向目标服务器发送标识信息 | |
httpURLConnection.setRequestProperty("User-Agent", | |
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)" + | |
" Chrome/14.0.835.163 Safari/535.1"); | |
// 返回 HttpURLConnection 对象 | |
return httpURLConnection; | |
} | |
/** | |
* 获取下载文件的名字 | |
* @param url | |
* @return | |
*/ | |
public static String getHttpFileName(String url) { | |
// 返回 文件的名称 | |
return url.substring(url.lastIndexOf("/") + 1); | |
} | |
} |
日志工具类:
// 日志工具类 | |
public class LogUtils { | |
// 对外公开的 info 日志级别的函数 | |
public static void info(String msg, Object... args) { | |
print(msg, "-info-", args); | |
} | |
// 对外公开的 error 日志级别的函数 | |
public static void error(String msg, Object... args) { | |
print(msg, "-error-", args); | |
} | |
// 日志处理函数 | |
private static void print(String msg, String level, Object... args) { | |
if (args != null && args.length > 0) { | |
String.format(msg.replace("{}", "%s"), args); | |
} | |
String name = Thread.currentThread().getName(); | |
System.out.println(LocalTime.now().format(DateTimeFormatter.ofPattern("hh:mm:ss")) + " thread:" | |
+ name + " level:" + level + " msg:" + msg); | |
} | |
} |
下载器类:
// 下载器 | |
public class Downloader { | |
public void download(String url) { | |
// 获取文件名 | |
String httpFileName = HttpUtils.getHttpFileName(url); | |
// 文件下载到本地路径 | |
httpFileName = Constant.PATH + httpFileName; | |
// 获取连接对象 | |
HttpURLConnection httpURLConnection = HttpUtils.getHttpURLConnection(url); | |
InputStream inputStream = null; | |
BufferedInputStream bufferedInputStream = null; | |
FileOutputStream fileOutputStream = null; | |
BufferedOutputStream bufferedOutputStream = null; | |
try { | |
// 读取请求信息 | |
inputStream = httpURLConnection.getInputStream(); | |
bufferedInputStream = new BufferedInputStream(inputStream); | |
// 创建输出流将文件写出到指定位置 | |
fileOutputStream = new FileOutputStream(httpFileName); | |
bufferedOutputStream = new BufferedOutputStream(fileOutputStream); | |
int i = -1; | |
while (((i = bufferedInputStream.read()) != -1)) { | |
bufferedOutputStream.write(i); | |
} | |
} catch (Exception e) { | |
LogUtils.error(e.getMessage()+"{}", url); | |
} finally { | |
// 关闭连接对象 | |
try { | |
if (bufferedOutputStream != null) { | |
bufferedOutputStream.close(); | |
} | |
if (fileOutputStream != null) { | |
fileOutputStream.close(); | |
} | |
if (bufferedInputStream != null) { | |
bufferedInputStream.close(); | |
} | |
if (inputStream != null) { | |
inputStream.close(); | |
} | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} | |
} |
# 3 下载信息
# 3.1 计划任务
文件下载的时候最好能够展示出下载的速度,已下载文件大小等信息。这里可以每隔一段时间来获取文件的下载信息,比如间隔 1 秒获取一次,然后将信息打印到控制台。文件下载是一个独立的线程,另外还需要再开启一个线程来间隔获取文件的信息。java.util.concurrent.ScheduledExecutorService,这个类可以帮助我们实现此功能。
# 3.2 ScheduledExecutorService
在该类中提供了一些方法可以帮助开发者实现间隔执行的效果,下面列出一些常见的方法
# 3.2.1 schedule 方法
该方法是重载的,这两个重载的方法都是有 3 个形参,只是第一个形参不同。
- Runnable/Callable<V> 可以传入这两个类型的任务
- long delay 时间数量
- TimeUnit unit 时间单位
该方法的作用是让任务按照指定的时间延时执行
代码:
// ScheduledExecutorService | |
public class TestDemo { | |
public static void main(String[] args) { | |
// 1:线程数量 | |
ScheduledExecutorService s = Executors.newScheduledThreadPool(1); | |
s.schedule(() -> | |
System.out.println(Thread.currentThread().getName()) | |
,2 , TimeUnit.SECONDS); | |
// 结束线程 | |
s.shutdown(); | |
} | |
} |
效果演示:
并不是周期性的
# 3.2.2 scheduleAtFixedRate 方法
该方法的作用是按照指定的时间延时执行,并且每隔一段时间再继续执行
- Runnable command 执行的任务
- long initialDelay 延时的时间数量
- long period 间隔的时间数量
- TimeUnit unit 时间单位
倘若在执行任务的时候,耗时超过了间隔时间,则执行任务结束后直接再次执行,而不是在等待间隔时间执行
代码:
// ScheduledExecutorService | |
public class TestDemo { | |
public static void main(String[] args) { | |
ScheduledExecutorService s = Executors.newScheduledThreadPool(1); | |
s.scheduleAtFixedRate(() -> { | |
System.out.println(Thread.currentThread().getName()); | |
try { | |
// 当程序执行该线程的任务时 该任务睡眠了 6 秒而该线程的间隔时间会继续计算着,所以等待 6 秒过去后就会直接执行该线程任务 | |
TimeUnit.SECONDS.sleep(6); | |
} catch (InterruptedException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
, 2, 3, TimeUnit.SECONDS); | |
} | |
} |
演示效果:
# 3.2.3 scheduleWithFixedDelay 方法
该方法的作用是按照指定的时间延时执行,并且每隔一段时间再继续执行
- Runnable command 执行的任务
- long initialDelay 延时的时间数量
- long period 间隔的时间数量
- TimeUnit unit 时间单位
在执行任务的时候,无论耗时多久,任务执行结束之后都会等待间隔时间之后再继续下次任务
代码:
public class TestDemo { | |
public static void main(String[] args) { | |
ScheduledExecutorService s = Executors.newScheduledThreadPool(1); | |
s.scheduleWithFixedDelay(() -> { | |
System.out.println(Thread.currentThread().getName()); | |
try { | |
// 该线程任务中睡眠了 6 秒不会计算间隔时间 当执行下次任务时还是需要等待间隔时间 | |
TimeUnit.SECONDS.sleep(6); | |
} catch (InterruptedException e) { | |
throw new RuntimeException(e); | |
} | |
}, 2, 3, TimeUnit.SECONDS); | |
} | |
} |
效果就不演示了
了解了上面的线程池的作用下面开始写代码
在常量类中添加一个常量:
// 常量类 | |
public class Constant { | |
public static final String PATH = "E://下载器演示目录/"; | |
public static final double MB = 1024d * 1024d; | |
} |
创建打印下载信息的线程类:
// 展示下载信息 | |
public class DownloadInfoThread implements Runnable{ | |
// 下载文件总大小 | |
private long httpFileContentLength; | |
// 本地已下载文件的大小 | |
public double finishedSize; | |
// 本次积累下载的大小 volatile 强制从主内存中读数据 | |
public volatile double downSize; | |
// 前一次下载的大小 | |
public double prevSize; | |
public DownloadInfoThread(int contentLength) { | |
this.httpFileContentLength = contentLength; | |
} | |
@Override | |
public void run() { | |
// 计算文件总大小 单位:mb (兆) | |
String httpFileSize = String.format("%.2f", httpFileContentLength / Constant.MB); | |
// 计算每秒下载速度 | |
int speed = (int) (downSize - prevSize) / 1024; | |
// 把当前下载大小赋值给 前一次的下载大小 | |
prevSize = downSize; | |
// 剩余文件的大小 | |
double remainSize = httpFileContentLength - finishedSize - downSize; | |
// 计算剩余时间 | |
String remainTime = String.format("%.1f", remainSize / 1024 / speed); | |
// 如果是无限大数字的话就让他展示为一个 - | |
if ("Infinity".equalsIgnoreCase(remainTime)) { | |
remainTime = "-"; | |
} | |
// 已下载大小 | |
String currentFileSize = String.format("%.2f", (downSize - finishedSize) / Constant.MB); | |
String downInfo = String.format("已下载 %smb/%smb, 速度 %skb/s, 剩余时间 %ss", currentFileSize, | |
httpFileSize, speed, remainTime); | |
// 这里不能使用 System.out.println (); 使用的话就会逐行打印信息 | |
// 如果使用如下方式打印 就会只在一行中显示信息 | |
System.out.print("\r"); | |
System.out.print(downInfo); | |
} | |
} |
编写获取本地文件大小的工具类:
在 下载器类中 我们需要通过该工具类传入文件的路径来获取文件的大小。
public class FileUtils { | |
// 获取本地文件的大小 | |
public static long getFileContentLength(String path) { | |
File file = new File(path); | |
// 判断当前目录是否存在 和 是否是文件 | |
return file.exists() && file.isFile() ? file.length() : 0; | |
} | |
} |
再到常量类中添加一个常量:
因为 Buffered 中提供的默认缓冲大小为 8192 在网上较快的情况下考虑不够用的情况我们自己定义一个缓冲数组
// 常量类 | |
public class Constant { | |
public static final String PATH = "E://下载器演示目录/"; | |
public static final double MB = 1024d * 1024d; | |
public static final int BYTE_SIZE = 1024 * 100; | |
} |
改写下载器类:
// 下载器 | |
public class Downloader { | |
// 创建线程池 | |
public ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); | |
public void download(String url) { | |
// 获取文件名 | |
String httpFileName = HttpUtils.getHttpFileName(url); | |
// 文件下载到本地路径 | |
httpFileName = Constant.PATH + httpFileName; | |
// 获取本地文件的大小 | |
long localFileLength = FileUtils.getFileContentLength(httpFileName); | |
// 获取连接对象 | |
HttpURLConnection httpURLConnection = HttpUtils.getHttpURLConnection(url); | |
// 获取下载文件的总大小 | |
int contentLength = httpURLConnection.getContentLength(); | |
// 创建获取下载信息的任务对象 | |
DownloadInfoThread downloadInfoThread = new DownloadInfoThread(contentLength); | |
// 将任务交给线程执行,每隔 1 秒执行一次 | |
scheduledExecutorService.scheduleAtFixedRate(downloadInfoThread, 1, 1, TimeUnit.SECONDS); | |
InputStream inputStream = null; | |
BufferedInputStream bufferedInputStream = null; | |
FileOutputStream fileOutputStream = null; | |
BufferedOutputStream bufferedOutputStream = null; | |
try { | |
inputStream = httpURLConnection.getInputStream(); | |
bufferedInputStream = new BufferedInputStream(inputStream); | |
fileOutputStream = new FileOutputStream(httpFileName); | |
bufferedOutputStream = new BufferedOutputStream(fileOutputStream); | |
// 缓冲流的默认缓冲大小是 8192 在网速较快的情况下不够用,所以我们自己写一个数组 | |
byte[] buffer = new byte[Constant.BYTE_SIZE]; | |
int i = -1; | |
while (((i = bufferedInputStream.read(buffer)) != -1)) { | |
// 累计记录当前下载的大小 | |
downloadInfoThread.downSize += i; | |
bufferedOutputStream.write(buffer, 0, i); | |
} | |
} catch (Exception e) { | |
LogUtils.error(e.getMessage()+"{}", url); | |
} finally { | |
// 关闭连接对象 | |
try { | |
System.out.print("\r"); | |
System.out.print("下载完成"); | |
if (bufferedOutputStream != null) { | |
bufferedOutputStream.close(); | |
} | |
if (fileOutputStream != null) { | |
fileOutputStream.close(); | |
} | |
if (bufferedInputStream != null) { | |
bufferedInputStream.close(); | |
} | |
if (inputStream != null) { | |
inputStream.close(); | |
} | |
// 关闭线程池的任务 | |
scheduledExecutorService.shutdownNow(); | |
} catch (IOException e) { | |
throw new RuntimeException(e); | |
} | |
} | |
} | |
} |
# 4 线程池简介
线程在创建,销毁的过程中会消耗一些资源,为了节省这些开销,jdk 添加了线程池。线程池节省了开销,提供了线程使用的效率。阿里巴巴开发文档中建议在编写多线程程序的时候使用线程池。
# 4.1 ThreadPoolExecutor 构造方法参数
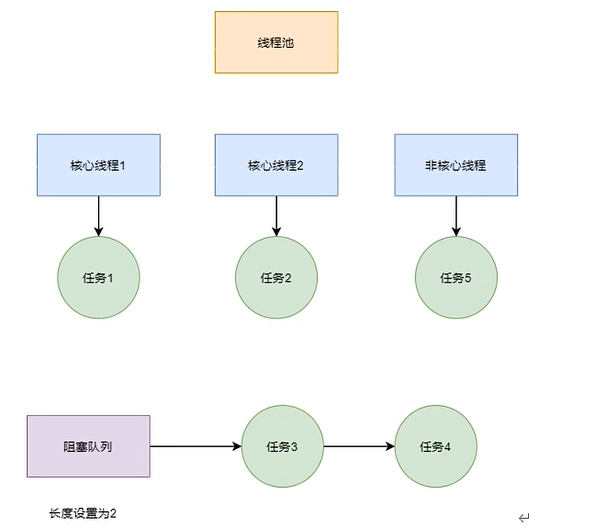
在 juc 包下提供了 ThreadPoolExecutor 类,可以通过该类来创建线程池,这个类中有 4 个重载的构造方法,最核心的方法是有 7 个形参的,这些参数所代表的意义如下:
corePoolSize
线程池中核心线程的数量
maximumPoolSize
线程池中最大线程的数量,是核心线程数量和非核心线程数量之和
keepAliveTime
非核心线程空闲的生存时间
unit
keepAliveTime 的生存时间单位
workQueue
当没有空闲的线程时,新的任务会加入到 workQueue 中排队等待
threadFactory
线程工厂,用于创建线程
handler
拒绝策略,当 workQueue 已满,且池中的线程数达到 maximumPoolSize 时,线程池拒绝添加新任务时采取的策略。(可以不指定)
代码演示:
public static void main(String[] args) { | |
// 参数 1:核心线程数量,参数 2:最大线程数量 (核心与非核心线程之和),参数 3:非核心线程存活时间 | |
// 参数 4:非核心线程 (当正在执行的线程数等于 corePoolSize 时,多余的任务会缓存在 ArrayBlockingQueue 中,等待有空闲的线程继续执行) | |
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 3, 1, | |
TimeUnit.MINUTES, new ArrayBlockingQueue<>(2), | |
// 创建线程工厂,也可以使用 jdk 默认的 | |
r -> { | |
Thread thread = new Thread(r); | |
thread.setName("demo"); | |
return thread; | |
}); | |
// 创建任务 | |
Runnable r = () -> System.out.println(Thread.currentThread().getName()); | |
// 将任务提交给线程池 | |
for (int i = 0; i < 6; i++) { | |
threadPool.execute(r); | |
} | |
} |
如果 线程池的 核心线程数和 非核心线程数 的数量小于 开辟的线程数时就会报错
打印结果:
demo
demo
demo
demo
demo
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task com.bjpowernode.test.TestDemo$$Lambda/0x0000021501003418@b1bc7ed rejected from java.util.concurrent.ThreadPoolExecutor@7530d0a[Running, pool size = 3, active threads = 3, queued tasks = 2, completed tasks = 0]
at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2081)
at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:841)
at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1376)
at com.bjpowernode.test.TestDemo.main(TestDemo.java:20)
# 4.2 线程池工作过程
# 4.3 线程池的状态
线程池中有 5 个状态,分别是:
Runing
创建线程池之后的状态是 Runing
SHUTDOWN
该状态下,线程池就不会接收新任务,但会处理阻塞队列剩余任务,相对温和
STOP
该状态下会中断正在执行的任务,并抛弃阻塞队列,相对暴力
TIDAYNG
任务全部执行完毕,活动线程为 0 即将进入终止
TERMINATE
线程池终止
# 4.4 线程池的关闭
线程池使用完毕之后需要进行关闭,提供了以下两种方法进行关闭
shutdown()
该方法执行后,线程池状态变为 SHUTDOWN,不会接收新任务,但是会执行完已提交的任务,此方法不会阻塞调用线程的执行
shutdownNow()
该方法执行后,线程池状态变为 STOP,不会接受新任务,会将队列中的任务返回,并用 interrupt 的方式中断正在执行的任务
# 4.5 工作队列
jdk 中提供的一些工作队列 workQueue
SychronousQueue
直接提交队列
ArrayBlockingQueue
有界队列,可以指定容量
LinkedBlockingDeque
无界队列,可以一直存储不指定容量
PriorityBlockingQueue
优先任务队列,可以根据任务优先级顺序执行任务
# 4.6 jdk 提供的创建线程池便捷方式
//jdk 提供的便捷的创建线程池的方式 | |
// 但是 阿里巴巴 开发文档提出了不建议使用 | |
// 建议使用原生的 ThreadPool | |
// 不建议的原因:如果不对内部实现了解就会出现问题,比如说 newFixedThreadPool 中使用了无界队列,任务不断的往里面扔任务量特别大的话那么程序就会出现问题 | |
// 除非你对如下的线程池内部实现比较熟悉才可以实用 | |
public class TestDemo01 { | |
public static void main(String[] args) { | |
// 我们可以通过 Executors 来创建一个线程池 | |
// 五个核心线程和五个非核心线程 | |
Executors.newFixedThreadPool(5); | |
// 没有核心线程,都是非核心线程,存活时间为 60 秒 | |
Executors.newCachedThreadPool(); | |
// 无界队列,核心线程数量 1,没有非核心线程 | |
Executors.newSingleThreadExecutor(); | |
// 创建 5 个核心线程与非核心线程 | |
Executors.newScheduledThreadPool(5); | |
} | |
} |
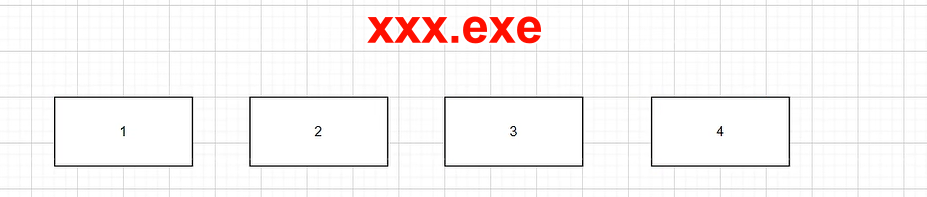
# 5 文件切分下载
把一个文件分成若干份,如果说目前把一个大文件分成了 4 分如下图所示:
当我们下载的时候不能用因为是 一个文件被分成了 4 个文件了,接下来我们就需要进行合并文件
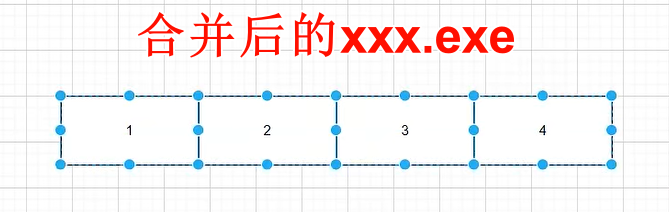
思考如何进行分块下载
我们需要把文件的每一块的 起始位置 和 结束位置 算出来就行了
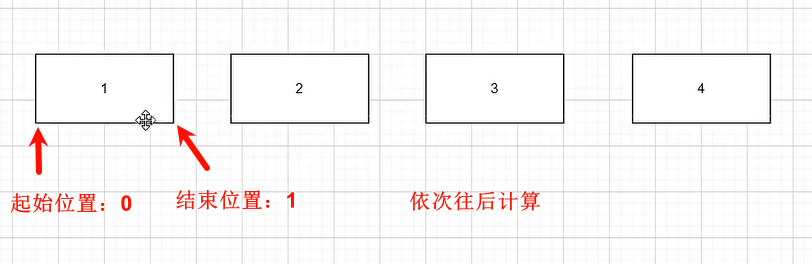
完成代码:
常量类
// 常量类 | |
public class Constant { | |
// 文件下载到本地的地址 | |
public static final String PATH = "E://下载器演示目录/"; | |
// 计算文件下载大小的单位 | |
public static final double MB = 1024d * 1024d; | |
// 开辟数组缓冲区的大小 | |
public static final int BYTE_SIZE = 1024 * 100; | |
// 线程数量 | |
public static final int THREAD_NUM = 5; | |
} |
下载器类
// 下载器 | |
public class Downloader { | |
// 创建线程池对象 | |
public ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(Constant.THREAD_NUM, Constant.THREAD_NUM, | |
0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5)); | |
// 创建线程池 | |
public ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); | |
// 合并完毕后 清除合并文件 | |
public boolean clearTemp(String fileName) { | |
for (int i = 0; i < Constant.THREAD_NUM; i++) { | |
File file = new File(fileName + ".temp" + i); | |
if (!file.delete()) { | |
System.out.println("\r"); | |
System.out.print("error = "+file.getAbsolutePath()); | |
return false; | |
} else { | |
System.out.println("\r"); | |
System.out.print("success = "+file.getAbsolutePath()); | |
} | |
} | |
return true; | |
} | |
// 合并分块文件 | |
public boolean merge(String fileName) { | |
LogUtils.info("开始合并文件{}", fileName); | |
byte[] bytes = new byte[Constant.BYTE_SIZE]; | |
int i = -1; | |
try (RandomAccessFile accessFile = new RandomAccessFile(fileName, "rw")) { | |
for (int j = 0; j < Constant.THREAD_NUM; j++) { | |
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(fileName + ".temp" + j))) { | |
while (((i = bis.read(bytes)) != -1)) { | |
accessFile.write(bytes, 0, i); | |
} | |
} | |
} | |
LogUtils.info("文件合并完毕"); | |
} catch (Exception e) { | |
LogUtils.error(e.getMessage() + "{}", fileName); | |
return false; | |
} | |
return true; | |
} | |
/** | |
* 文件切分 | |
* | |
* @param url | |
* @param futureList | |
*/ | |
public void split(String url, ArrayList<Future> futureList) { | |
// 获取下载文件大小 | |
long contentLength = HttpUtils.getHttpFileContentLength(url); | |
// 计算切分后的文件大小 | |
long size = contentLength / Constant.THREAD_NUM; | |
// 根据线程数量计算分块的个数 | |
for (int i = 0; i < Constant.THREAD_NUM; i++) { | |
// 计算下载起始位置 | |
long startPos = i * size; | |
// 计算结束位置 | |
long endPos; | |
// 如果 i == 线程数量 - 1 就说明是最后一块 分块文件下载了 | |
if (i == Constant.THREAD_NUM - 1) { | |
// 下载最后一块,将下载剩余的部分全部下载即可 | |
endPos = 0; | |
} else { | |
// 如果不是最后一块那么就计算 起始位置加上 文件切分后大小 就是结束位置 | |
endPos = startPos + size; | |
} | |
// 如果不是第一块,起始位置要加 1 | |
if (startPos != 0) { | |
startPos++; | |
} | |
// 创建任务对象 | |
DownloaderTask downloaderTask = new DownloaderTask(url, startPos, endPos, i); | |
// 将任务提交到线程池中 | |
//submit 与 execute 的区别本质还是调用了 execute 方法执行线程任务的 | |
Future<Boolean> future = poolExecutor.submit(downloaderTask); | |
futureList.add(future); | |
} | |
} | |
public void download(String url) { | |
// 获取文件名 | |
String httpFileName = HttpUtils.getHttpFileName(url); | |
// 文件下载到本地路径 | |
httpFileName = Constant.PATH + httpFileName; | |
// 获取本地文件的大小 | |
long localFileLength = FileUtils.getFileContentLength(httpFileName); | |
// 获取连接对象 | |
HttpURLConnection httpURLConnection = null; | |
try { | |
httpURLConnection = HttpUtils.getHttpURLConnection(url); | |
// 获取下载文件的总大小 | |
int contentLength = httpURLConnection.getContentLength(); | |
// 创建获取下载信息的任务对象 | |
DownloadInfoThread downloadInfoThread = new DownloadInfoThread(contentLength); | |
// 将任务交给线程执行,每隔 1 秒执行一次 | |
scheduledExecutorService.scheduleAtFixedRate(downloadInfoThread, 1, 1, TimeUnit.SECONDS); | |
// 切分任务 | |
ArrayList<Future> lists = new ArrayList<>(); | |
split(url, lists); | |
lists.forEach(future -> { | |
try { | |
future.get(); | |
} catch (InterruptedException e) { | |
throw new RuntimeException(e); | |
} catch (ExecutionException e) { | |
throw new RuntimeException(e); | |
} | |
}); | |
// 合并分块文件 | |
if (merge(httpFileName)) { | |
// 清除临时文件 | |
clearTemp(httpFileName); | |
} | |
LogUtils.info("下载完成"); | |
} catch (Exception e) { | |
LogUtils.error(e.getMessage() + "{}", url); | |
} finally { | |
if (httpURLConnection != null) { | |
// 关闭连接 | |
httpURLConnection.disconnect(); | |
} | |
// 关闭线程池 | |
scheduledExecutorService.shutdown(); | |
poolExecutor.shutdown(); | |
} | |
} | |
} |
分开下载任务类
// 分块下载任务 类 | |
// 下载时是否成功我们需要返回一个布尔值所以使用 Callable 线程 | |
public class DownloaderTask implements Callable<Boolean> { | |
// 下载链接 | |
private String url; | |
// 下载块的起始位置 | |
private Long startPos; | |
// 下载块的结束位置 | |
private Long endPos; | |
// 标识当前下载的是 第几块 | |
private int part; | |
public DownloaderTask(String url, Long startPos, Long endPos, int part) { | |
this.url = url; | |
this.startPos = startPos; | |
this.endPos = endPos; | |
this.part = part; | |
} | |
@Override | |
public Boolean call() { | |
// 获取文件名 | |
String httpFileName = HttpUtils.getHttpFileName(url); | |
// 分块的文件名 | |
httpFileName = httpFileName + ".temp" + part; | |
// 下载路径 | |
httpFileName = Constant.PATH + httpFileName; | |
// 获取下载链接 | |
HttpURLConnection httpURLConnection = HttpUtils.getHttpURLConnection(url, startPos, endPos); | |
try { | |
// 获取连接信息 | |
InputStream input = httpURLConnection.getInputStream(); | |
// 传入到缓冲流中 | |
BufferedInputStream bis = new BufferedInputStream(input); | |
// 创建随机读写类,后面如果断点续传会用上 | |
RandomAccessFile accessFile = new RandomAccessFile(httpFileName, "rw"); | |
// 读写文件 | |
byte[] bytes = new byte[Constant.BYTE_SIZE]; | |
int i = -1; | |
while (((i = bis.read(bytes)) != -1)) { | |
// 1 秒内下载数据之和 , 通过原子类进行操作 | |
DownloadInfoThread.downSize.add(i); | |
accessFile.write(bytes, 0, i); | |
} | |
} catch (IOException e) { | |
LogUtils.error(e.getMessage() + "{}", url); | |
// 如果发生了错误就当前线程返回 false | |
return false; | |
} finally { | |
// 关闭连接 | |
if (httpURLConnection != null) { | |
httpURLConnection.disconnect(); | |
} | |
} | |
// 如果没有发生错误当前线程返回 true | |
return true; | |
} | |
} |
展示下载信息类
// 展示下载信息 | |
public class DownloadInfoThread implements Runnable{ | |
// 下载文件总大小 | |
private long httpFileContentLength; | |
// 本地已下载文件的大小 | |
public static LongAdder finishedSize = new LongAdder(); | |
// 本次积累下载的大小 volatile 强制从主内存中读数据 | |
public static volatile LongAdder downSize = new LongAdder(); | |
// 前一次下载的大小 | |
public double prevSize; | |
public DownloadInfoThread(int contentLength) { | |
this.httpFileContentLength = contentLength; | |
} | |
@Override | |
public void run() { | |
// 计算文件总大小 单位:mb (兆) | |
String httpFileSize = String.format("%.2f", httpFileContentLength / Constant.MB); | |
// 计算每秒下载速度 | |
int speed = (int) (downSize.doubleValue() - prevSize) / 1024; | |
// 把当前下载大小赋值给 前一次的下载大小 | |
prevSize = downSize.doubleValue(); | |
// 剩余文件的大小 | |
double remainSize = httpFileContentLength - finishedSize.doubleValue() - downSize.doubleValue(); | |
// 计算剩余时间 | |
String remainTime = String.format("%.1f", remainSize / 1024 / speed); | |
// 如果是无限大数字的话就让他展示为一个 - | |
if ("Infinity".equalsIgnoreCase(remainTime)) { | |
remainTime = "-"; | |
} | |
// 已下载大小 | |
String currentFileSize = String.format("%.2f", (downSize.doubleValue() - finishedSize.doubleValue()) / Constant.MB); | |
String downInfo = String.format("已下载 %smb/%smb, 速度 %skb/s, 剩余时间 %ss", currentFileSize, | |
httpFileSize, speed, remainTime); | |
// 这里不能使用 System.out.println (); 使用的话就会逐行打印信息 | |
// 如果使用如下方式打印 就会只在一行中显示信息 | |
System.out.print("\r"); | |
System.out.print(downInfo); | |
} | |
} |
工具类:
FileUtils
public class FileUtils { | |
// 获取本地文件的大小 | |
public static long getFileContentLength(String path) { | |
File file = new File(path); | |
// 判断当前目录是否存在 和 是否是文件 | |
return file.exists() && file.isFile() ? file.length() : 0; | |
} | |
} |
HttpUtils
// Http 相关工具类 | |
public class HttpUtils { | |
// 获取下载文件大小 | |
public static long getHttpFileContentLength(String url) { | |
int contentLength = 0; | |
HttpURLConnection httpURLConnection = null; | |
try { | |
// 获取 url 连接 | |
httpURLConnection = getHttpURLConnection(url); | |
// 获取 url 的文件大小信息 | |
contentLength = httpURLConnection.getContentLength(); | |
} catch (Exception e) { | |
throw new RuntimeException(e); | |
} finally { | |
// 关闭连接 | |
if (httpURLConnection != null) { | |
httpURLConnection.disconnect(); | |
} | |
} | |
// 返回文件的大小 | |
return contentLength; | |
} | |
/** | |
* 分块下载 | |
* @param url 下载地址 | |
* @param startPos 下载文件起始位置 | |
* @param endPos 下载文件的结束位置 | |
* @return | |
*/ | |
public static HttpURLConnection getHttpURLConnection(String url, long startPos, long endPos) { | |
HttpURLConnection httpURLConnection = getHttpURLConnection(url); | |
LogUtils.info("下载的区间是{}-{}", startPos, endPos); | |
if (endPos != 0) { | |
// 向浏览器发送请求:下载区间为 startPos 到 endPos 之间 | |
httpURLConnection.setRequestProperty("RANGE", "bytes=" + startPos + "-" + endPos); | |
} else { | |
// 当下载文件到了最后一块的时候就不需要知道结束位置了,因为我们只需要全部下载下来就行了 | |
httpURLConnection.setRequestProperty("RANGE", "bytes=" + startPos + "-"); | |
} | |
return httpURLConnection; | |
} | |
/** | |
* 获取 HttpURLConnection 链接对象 | |
* @param url 文件下载地址 | |
* @return | |
*/ | |
public static HttpURLConnection getHttpURLConnection(String url) { | |
URL urlOne = null; | |
HttpURLConnection httpURLConnection = null; | |
try { | |
urlOne = new URL(url); | |
httpURLConnection = (HttpURLConnection) urlOne.openConnection(); | |
} catch (Exception e) { | |
throw new RuntimeException(e); | |
} | |
// 向目标服务器发送标识信息 | |
httpURLConnection.setRequestProperty("User-Agent", | |
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)" + | |
" Chrome/14.0.835.163 Safari/535.1"); | |
return httpURLConnection; | |
} | |
/** | |
* 获取下载文件的名字 | |
* @param url | |
* @return | |
*/ | |
public static String getHttpFileName(String url) { | |
return url.substring(url.lastIndexOf("/") + 1); | |
} | |
} |
LogUtils
// 日志工具类 | |
public class LogUtils { | |
public static void info(String msg, Object... args) { | |
print(msg, "-info-", args); | |
} | |
public static void error(String msg, Object... args) { | |
print(msg, "-error-", args); | |
} | |
private static void print(String msg, String level, Object... args) { | |
if (args != null && args.length > 0) { | |
String.format(msg.replace("{}", "%s"), args); | |
} | |
String name = Thread.currentThread().getName(); | |
System.out.println(LocalTime.now().format(DateTimeFormatter.ofPattern("hh:mm:ss")) + " thread:" | |
+ name + " level:" + level + " msg:" + msg); | |
} | |
} |
主方法:
public class Main { | |
public static void main(String[] args) { | |
// 下载地址 | |
String url = null; | |
if (args == null || args.length == 0) { | |
for(;;) { | |
LogUtils.info("请输入下载链接"); | |
Scanner scanner = new Scanner(System.in); | |
url = scanner.next(); | |
if (url != null) { | |
break; | |
} | |
} | |
} else { | |
url = args[0]; | |
} | |
Downloader downloader = new Downloader(); | |
downloader.download(url); | |
} | |
} |