# 二级菜单数据结构
创建数据库表
/* | |
Navicat Premium Data Transfer | |
Source Server : windows | |
Source Server Type : MySQL | |
Source Server Version : 80028 | |
Source Host : localhost:3306 | |
Source Schema : tree_data | |
Target Server Type : MySQL | |
Target Server Version : 80028 | |
File Encoding : 65001 | |
Date: 29/02/2024 10:25:33 | |
*/ | |
SET NAMES utf8mb4; | |
SET FOREIGN_KEY_CHECKS = 0; | |
-- ---------------------------- | |
-- Table structure for data | |
-- ---------------------------- | |
DROP TABLE IF EXISTS `data`; | |
CREATE TABLE `data` ( | |
`id` int NOT NULL AUTO_INCREMENT, | |
`name` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '', | |
`p_id` int NULL DEFAULT NULL, | |
`order_num` int NULL DEFAULT NULL, | |
PRIMARY KEY (`id`) USING BTREE | |
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; | |
-- ---------------------------- | |
-- Records of data | |
-- ---------------------------- | |
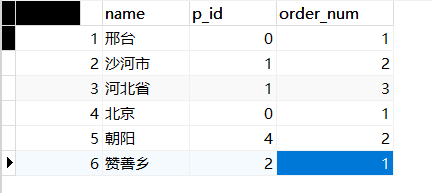
INSERT INTO `data` VALUES (1, '邢台', 0, 1); | |
INSERT INTO `data` VALUES (2, '沙河市', 1, 2); | |
INSERT INTO `data` VALUES (3, '河北省', 1, 3); | |
INSERT INTO `data` VALUES (4, '北京 ', 0, 1); | |
INSERT INTO `data` VALUES (5, '朝阳', 4, 2); | |
INSERT INTO `data` VALUES (6, '赞善乡', 2, 1); | |
SET FOREIGN_KEY_CHECKS = 1; |
创建好的数据库如下:
编写递归 SQL 语句:
WITH recursive t1 AS ( | |
SELECT * FROM `data` WHERE `data`.id = 1 | |
UNION ALL | |
SELECT t2.* FROM `data` AS t2 INNER JOIN t1 ON t1.id = t2.p_id | |
) | |
SELECT * FROM t1 ORDER BY t1.order_num; |
查询结果:
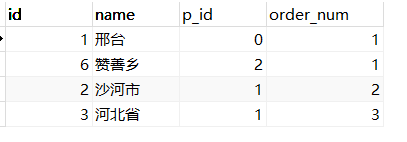
可以看到 id = 1 下的所以子级数据都被查询出来了
应用到业务中编写 java 代码,编写实体类:
public class Data { | |
private Integer id; | |
private String name; | |
private Integer pId; | |
private Integer order; | |
public Integer getId() { | |
return id; | |
} | |
public void setId(Integer id) { | |
this.id = id; | |
} | |
public String getName() { | |
return name; | |
} | |
public void setName(String name) { | |
this.name = name; | |
} | |
public Integer getpId() { | |
return pId; | |
} | |
public void setpId(Integer pId) { | |
this.pId = pId; | |
} | |
public Integer getOrder() { | |
return order; | |
} | |
public void setOrder(Integer order) { | |
this.order = order; | |
} | |
@Override | |
public String toString() { | |
return "Data{" + | |
"id=" + id + | |
", name='" + name + '\'' + | |
", pId=" + pId + | |
", order=" + order + | |
'}'; | |
} | |
} |
编写 Dto 类用于存储子级数据:
public class DataDo extends Data{ | |
private List<Data> datas; | |
public List<Data> getDatas() { | |
return datas; | |
} | |
public void setDatas(List<Data> datas) { | |
this.datas = datas; | |
} | |
} |
编写 mapper
public interface CourseCategoryMapper extends BaseMapper<Data> { | |
// 使用递归查询分类 | |
List<CourseCategotyTreeDto> selectTreeNodes(String id); | |
} |
mapper.xml
<select id="selectTreeNodes" parameterType="string" resultMap="BaseResultMap"> | |
WITH recursive t1 AS ( | |
SELECT * FROM course_category WHERE course_category.id = #{id} | |
UNION ALL | |
SELECT t2.* FROM course_category AS t2 INNER JOIN t1 ON t1.id = t2.parentid | |
) | |
SELECT * FROM t1 ORDER BY t1.id; | |
</select> |
service
public interface CourseCategoryService extends IService<Data> { | |
List<CourseCategotyTreeDto> selectTreeNodes(String id); | |
} |
serviceImpl
@Slf4j | |
@Service | |
public class CourseCategoryServiceImpl extends ServiceImpl<CourseCategoryMapper, Data> implements CourseCategoryService { | |
@Autowired | |
private CourseCategoryMapper courseCategoryMapper; | |
@Override | |
public List<DataDo> selectTreeNodes(String id) { | |
// 调用 mapper 递归查询出分类信息 | |
List<DataDo> list = courseCategoryMapper.selectTreeNodes("1"); | |
// 找到每个节点的子节点,最终封装成 List<CourseCategoryTreeDto> | |
// 先将 list 转成 map,key 就是节点的 id,value 就是 CourseCategoryTreeDto 对象,目的就是为了方便从 map 获取节点 | |
//stream 将 List 集合转换为流 filter 过滤父节点 collect 转换为目标集合 (map) | |
//toMap 参数:根据 id 和 内容 转换为 map 集合元素,并且如果有重复的 key (id) 则以 key2 为准 | |
Map<Integer, DataDo> mapTemp = | |
list.stream().filter(item -> ! id.equals(item.getId())) | |
.collect(Collectors.toMap(key -> key.getId() | |
, value -> value, (key1, key2) -> key2)); | |
// 定义一个 List 作为最终返回的 List | |
List<DataDo> listTwo = new ArrayList<>(); | |
// 从头遍历 List<CourseCategoryTreeDto> , 一边遍历一边找子节点放在父节点的 childrenTreeNodes | |
//filter 过滤掉父节点 | |
list.stream().filter(item -> ! id.equals(item.getId())).forEach(item -> { | |
// 向 List 中写入元素 | |
if(item.getParentid().equals(id)) | |
{ | |
listTwo.add(item); | |
} | |
// 找到节点的父节点 | |
DataDo courseCategotyTreeDto = mapTemp.get(item.getParentid()); | |
// 判断 map 集合中是否存在该父节点 | |
if(courseCategotyTreeDto != null) | |
{ | |
// 找到父节点后判断这个父节点是否有子节点如果没有则为空 | |
if(courseCategotyTreeDto.getDatas() == null) | |
{ | |
// 如果为空则实例化 List 集合 | |
courseCategotyTreeDto.setDatas(new ArrayList<>()); | |
} | |
// 找到每个节点的子节点放在父节点的 childrenTreeNodes 属性中 | |
courseCategotyTreeDto.getDatas().add(item); | |
} | |
}); | |
return listTwo; | |
} | |
} |